This article mainly draws on Mamba: The Hard Way and the open-source project flash-linear-attention.
Prefill and Decoding
As we know, Prefill and Decoding are two very different scenarios in attention computation, with the following characteristics:
| Property | Prefill | Decoding |
|---|---|---|
| Input | Long sequence (length $L$) | 1 new token + historical state |
| Common bottleneck | Compute bound (Tensor Core utilization) | Memory / latency bound (state reads/writes + small matrix ops) |
Recall the derivation from the theory article, especially the section on Mamba. Common linear attention variants can usually be written in two equivalent forms:
Matrix form (attention view):
$$ y_i = \sum_{j=0}^i (CausalMask(Q_i K_j^T)) V_j $$
Recurrent form (SSM view):
$$ h_t = A_t h_{t-1} + B_t x_t $$ $$ y_t = C h_t $$
In Decoding, the recurrent form can be used quite directly, so in this article I will focus mainly on how Prefill is implemented.
Common Algorithms for Linear Attention
There are several recurring implementation ideas in linear attention. In this section, I will explain them with reference to flash-linear-attention.
Prefix Scan / Cumsum
Algorithm Overview
Let us first review what Prefix Scan means. In short, Prefix Scan is an optimization technique for associative operators.
Suppose we have $y_t = x_1 ⊗ x_2 ⊗ x_3 … ⊗ x_t$. If $⊗$ is associative, then $y_t$ can be computed efficiently with a reduce-style parallel procedure.
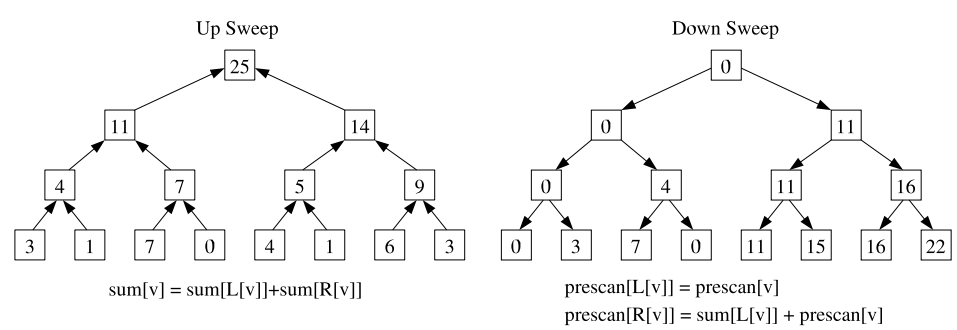
=== Parallel Prefix Scan (Up Sweep) ===
Sequence: [x1][x2][x3][x4][x5][x6][x7][x8]
Step 1: Merge adjacent elements in pairs (4 parallel ops)
[x_1] [x1 ⊗ x2] [x_3] [x3 ⊗ x4] [x_5] [x5 ⊗ x6] [x_7] [x7 ⊗ x8]
Step 2: Continue merging (2 parallel ops)
[x_1] [x_1 ⊗ x_2] [x_3] [x1 ⊗ x2 ⊗ x3 ⊗ x4] [x_5] [x5 ⊗ x6] [x_7] [x5 ⊗ x6 ⊗ x7 ⊗ x8]
Step 3: Final merge + down-sweep (recover all prefix results)
[complete prefix sequence (y_t)]
Total: O(log L) rounds, each round O(L) work
This phase is usually called the Up Sweep. During this process we not only compute the final $y_t$, but also generate many intermediate results. You can think of the array as a binary tree.
Now recall that in practice we often want not only the final $y_L$, but every prefix result from $y_1$ to $y_L$. Up Sweep alone only gives the full prefix for the last position. To recover all prefix values efficiently, we need the Down Sweep phase.
The core idea of Down Sweep is: use the intermediate values left on the tree by Up Sweep, and propagate the “left accumulated value” downward from the root.
=== Parallel Prefix Scan (Down Sweep) ===
State after Up Sweep: [x1] [x1⊗x2] [x3] [x1⊗x2⊗x3⊗x4] [x5] [x5⊗x6] [x7] [x1⊗...⊗x8]
Step 1: Set to identity
Set the last element (the root) to the identity element (for example 0).
This is because the prefix sum before the first element should be 0.
[x1] [x1⊗x2] [x3] [x1⊗x2⊗x3⊗x4] [x5] [x5⊗x6] [x7] [0]
Step 2: Swap and distribute
From top to bottom, do the following at each level:
1. Save the current left child value.
2. Assign the current node value to the left child.
3. Assign "saved left child value ⊗ current node value" to the right child.
(First propagation: send the root's 0 to the left half,
and the total of the left half to the right half)
[x1] [x1⊗x2] [x3] [0] [x5] [x5⊗x6] [x7] [x1⊗x2⊗x3⊗x4]
Step 3: Recursive down-sweep
Continue recursively until the leaves.
The final array becomes the Exclusive Scan sequence.
Step 4: Recover Inclusive Scan
Combine the Exclusive Scan result with the original sequence elementwise via ⊗
to obtain y_1 through y_L.
Total: O(log L) rounds, each round O(L) work, so overall still O(L).
These two phases can be visualized as two tree-shaped computations:
And here is a concrete example:
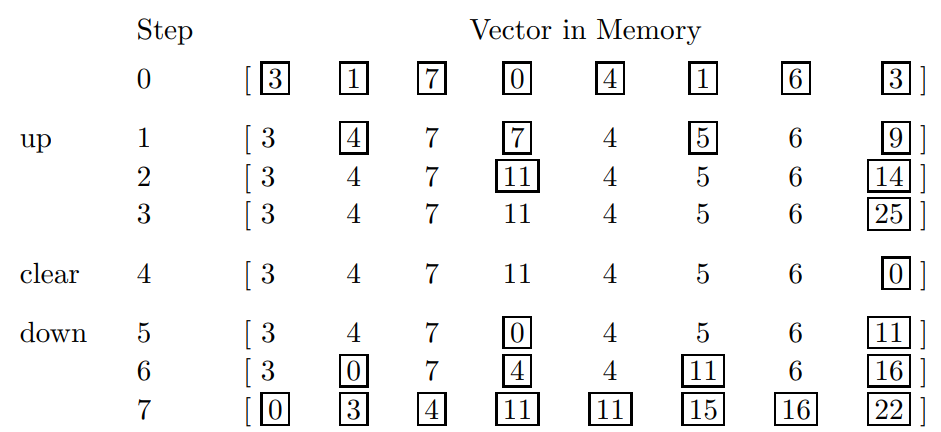
Prefix Scan in Linear Attention
Now that we understand Prefix Scan, let us look at the recurrence in linear attention:
$$ h_t = A_t h_{t-1} + B_t x_t $$ $$ y_t = C h_t $$
This is a first-order linear recurrence. In a traditional RNN, we must compute $h_1, h_2, \dots, h_L$ sequentially, which becomes a major bottleneck on long sequences. To convert it into a Prefix Scan, we need to find an associative operator $\otimes$.
Mathematical Derivation: Why the Recurrence Is Associative
Why can a linear recurrence be converted into Prefix Scan? The key is to view state transitions as composition of linear functions.
For any time step $t$, the update is:
$$ h_t = A_t h_{t-1} + b_t \quad (\text{where } b_t = B_t x_t) $$
We can interpret this as a linear transform $f_t(h) = A_t h + b_t$. Then $h_t$ is simply the nested composition of these transforms:
$$ h_t = f_t(f_{t-1}(\dots f_1(h_0) \dots)) $$
Now define an operator $\otimes$ over two linear transforms, representing the composition $f_j \circ f_i$ (assuming $j > i$):
$$ (f_j \circ f_i)(h) = A_j (A_i h + b_i) + b_j = (A_j A_i) h + (A_j b_i + b_j) $$
So we can define an operator over tuples $(A, b)$:
$$ (A_j, b_j) \otimes (A_i, b_i) = (A_j A_i, A_j b_i + b_j) $$
The physical meaning of this operator is: it computes the “total transition matrix” and “total bias term” from state $h_{i-1}$ to $h_j$.
If we perform Prefix Scan over the sequence $[(A_1, b_1), (A_2, b_2), \dots, (A_L, b_L)]$, then the result at position $t$, namely $(A_{1:t}, b_{1:t})$, represents the full transform from the initial state $h_0$ to $h_t$:
$$ h_t = A_{1:t} h_0 + b_{1:t} $$
Proof of associativity:
Assume we have three consecutive transitions $(A_3, b_3), (A_2, b_2), (A_1, b_1)$:
-
Left-associated: $$((A_3, b_3) \otimes (A_2, b_2)) \otimes (A_1, b_1) = (A_3 A_2, A_3 b_2 + b_3) \otimes (A_1, b_1) = (A_3 A_2 A_1, (A_3 A_2) b_1 + (A_3 b_2 + b_3))$$
-
Right-associated: $$(A_3, b_3) \otimes ((A_2, b_2) \otimes (A_1, b_1)) = (A_3, b_3) \otimes (A_2 A_1, A_2 b_1 + b_2) = (A_3 A_2 A_1, A_3 (A_2 b_1 + b_2) + b_3)$$
After expansion, the two are exactly the same. That means we can compute all $h_t$ in parallel in $O(\log L)$ time using Parallel Prefix Scan.
Code Sketch
In implementations like flash-linear-attention or Mamba, one often uses jax.lax.associative_scan or manually implements similar logic in Triton. Here is a simplified example:
def associative_scan_op(q_earlier, q_later):
"""
q = (A, b)
Compose two linear transforms: f_later(f_earlier(h))
"""
a_i, b_i = q_earlier
a_j, b_j = q_later
# The new A is the product of the two matrices (later on the left).
# The new b is later_A * earlier_b + later_b.
return a_j * a_i, a_j * b_i + b_j
# 1. Prepare the input tuple sequence
# A_bars: [L, d_state]
# b_bars: [L, d_state], i.e. B_t * x_t
inputs = (A_bars, b_bars)
# 2. Run the parallel prefix scan
# The result at each position t is the combined transform from h_0 to h_t.
combined_params = associative_scan(associative_scan_op, inputs)
# 3. Compute hidden states h_t (assuming h_0 = 0)
# h_t = A_1:t * h_0 + b_1:t = b_1:t
h_states = combined_params[1]
# 4. Compute output y = C * h
outputs = C * h_states
The beauty of this formulation is that it turns a serial for loop, where $h_t$ depends on $h_{t-1}$, into a tree-shaped parallel reduction. On a GPU, that means thousands of cores can work on different parts of the sequence simultaneously, dramatically improving Prefill throughput.
Chunk-wise Parallel
Chunk-wise Parallel is the most important Prefill implementation strategy in flash-linear-attention. Mamba: The Hard Way also explains the same idea. While the concrete implementation varies with kernel partitioning, the core idea is always a two-pass design.
Specifically, we split the full sequence of length $L$ into multiple chunks of length $C$, and then compute as follows:
- Pass 1: compute the hidden state of the last token of each chunk sequentially, i.e. $L / C$ steps producing $L / C$ states.
- Pass 2: do local computation inside each chunk and add the contribution from preceding chunks in parallel, with dense matmul-heavy work.
The process is illustrated below:
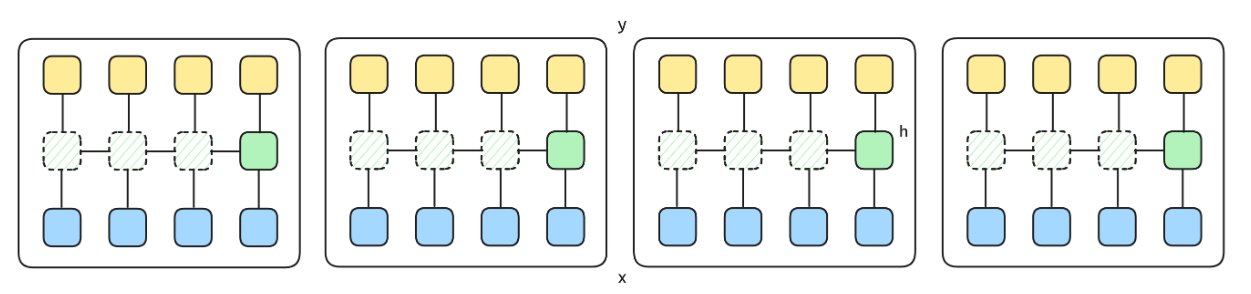
- In Pass 1, each chunk is processed sequentially to produce the dark green blocks.
- In Pass 2, all chunks compute the light green blocks from those dark green boundary states, and then produce the final blue outputs.
Triton Pseudocode
# 1. Inter-chunk: propagate state (Pass 1)
# Similar to an RNN, but only at chunk boundaries.
for i in range(num_chunks):
# Load the previous chunk state (or S_0 for i = 0)
b_s = tl.load(s_ptr + (i - 1) * stride) if i > 0 else tl.zeros(...)
# Update state: S = S * Decay + K^T * V (current chunk contribution)
b_s = b_s * chunk_decay + tl.dot(tl.trans(b_k_block), b_v_block)
# Save it for the next chunk
tl.store(s_ptr + i * stride, b_s)
# 2. Intra-chunk: chunk-local parallel compute (Pass 2)
# Similar to standard attention, but only within the chunk.
# Load Q, K, V for the current chunk
b_q = tl.load(q_ptr) # [BLOCK_SIZE, D_K]
b_k = tl.load(k_ptr) # [BLOCK_SIZE, D_K]
b_v = tl.load(v_ptr) # [BLOCK_SIZE, D_V]
# Local attention score: Q @ K^T
b_s = tl.dot(b_q, tl.trans(b_k)) * decay_mask # [BLOCK_SIZE, BLOCK_SIZE]
# Compute output
b_o = tl.dot(b_s, b_v) # [BLOCK_SIZE, D_V]
# Add contribution from the previous chunk state
b_o += tl.dot(b_q, prev_s) * decay
FFT and Convolutional Linear Attention
Core Idea: Accelerating Convolution
For some linear attention variants such as Hyena, the key property is that the decay weights depend only on relative position, not absolute position. That allows the computation to be rewritten as a convolution and accelerated with FFT.
From Recurrence to Convolution
Consider a simplified output formula:
$$o_t = \sum_{j=1}^t u_j \cdot \alpha_{t-j}$$
where:
- $u_j$ is the input representation at time $j$.
- $\alpha_{t-j}$ is a decay coefficient that depends only on relative distance $(t-j)$.
Since the subscript of $\alpha$ is $t-j$, it matches the definition of a convolution.
Directly computing this convolution costs $O(L^2)$, because for each position $t$ we must sum over all previous $j$. But by the convolution theorem:
$$\text{convolution in time domain} = \text{pointwise multiplication in frequency domain}$$ $$f * g = \mathcal{F}^{-1}(\mathcal{F}(f) \cdot \mathcal{F}(g))$$
FFT costs $O(L \log L)$, pointwise multiplication costs $O(L)$, so the total complexity becomes $O(L \log L)$, much smaller than $O(L^2)$.
Here is a concrete example.
Suppose $L=4$, input $u = [1, 2, 3, 4]$, and decay kernel $\alpha = [1.0, 0.5, 0.25, 0.125]$.
Direct computation ($O(L^2)$):
o_1 = u_1 * α_0 = 1 * 1.0 = 1.0
o_2 = u_2 * α_0 + u_1 * α_1 = 2*1.0 + 1*0.5 = 2.5
o_3 = u_3 * α_0 + u_2 * α_1 + u_1 * α_2 = 3*1.0 + 2*0.5 + 1*0.25 = 4.25
o_4 = u_4 * α_0 + u_3 * α_1 + u_2 * α_2 + u_1 * α_3 = 4*1.0 + 3*0.5 + 2*0.25 + 1*0.125 = 6.125
FFT acceleration ($O(L \log L)$):
1. FFT(u) and FFT(α) -> move to frequency domain (O(L*logL))
2. Pointwise multiply -> elementwise multiply (O(L))
3. IFFT -> move back to time domain (O(L*logL))
Code Example
def fft_conv(u, k, seqlen):
"""
Accelerate causal convolution with FFT
Args:
u: input sequence [batch, seqlen, dim]
k: decay kernel [seqlen] (depends only on relative position)
seqlen: sequence length
Returns:
output sequence [batch, seqlen, dim]
"""
# 1. Pad to 2*L to avoid circular-convolution boundary issues
fft_size = 2 * seqlen
# 2. FFT into frequency domain (O(L log L))
k_f = torch.fft.rfft(k, n=fft_size)
u_f = torch.fft.rfft(u, n=fft_size)
# 3. Pointwise multiply in frequency domain (O(L))
y_f = u_f * k_f
# 4. Inverse FFT back to time domain (O(L log L))
y = torch.fft.irfft(y_f, n=fft_size)
# 5. Take the valid range
return y[..., :seqlen]
Although FFT looks very appealing, in most linear attention variants the decay kernel depends not only on position but also on the input $x$. So FFT-based acceleration is uncommon in practice and only works for specific architectures.
Further Compute Efficiency and Performance Optimizations
DeltaNet: WY Representation and the UT Transform
Earlier we introduced the basic chunk-wise framework, but in practice it is not quite usable out of the box. Here I will use DeltaNet to explain the WY representation and UT transform. A similar idea also appears in KDA.
Recall the core idea of the chunk-wise algorithm, the two-pass structure:
Pass 1 (Inter-chunk): sequentially compute the boundary state of each chunk.
- For standard linear attention: $S[i+1] = S[i] + V[i]^T K[i]$ (matrix multiplication, efficient).
Pass 2 (Intra-chunk): compute outputs inside the chunk in parallel.
- We need to express local chunk accumulation in a form that can be computed as matrix multiplication.
- For example: $O[i] = Q[i] S[i]^T + (\text{local intra-chunk contribution})$.
To get good performance, both passes want the computation to be representable as efficient matrix multiplication so that GPU Tensor Cores can be used, instead of serial loops or dense $d \times d$ matrix add/subtract operations.
The Problem with DeltaNet’s Original Form
In standard linear attention, state update is a simple additive form:
$$ S_t = S_{t-1} + v_t k_t^T $$
So within one chunk:
$$ S[i+1] = S[i] + \sum_{t=1}^{C} v_t k_t^T = S[i] + V^T K $$
But recall from the theory article that in DeltaNet, the Delta Rule update is more complicated:
$$ S_t = S_{t-1}(I - \beta_t k_t k_t^{\top}) + \beta_t v_t k_t^{\top} $$
Now, if we try to accumulate this within a chunk, we run into major efficiency problems.
From Section 2 of Parallelizing Linear Transformers with the Delta Rule over Sequence Length, the update from $S[i]$ to $S[i+1]$ within a chunk can be derived as:
$$ S[i+1] = S[i] \prod_{t=1}^C \bigl(I - \beta_t k_t k_t^{\top}\bigr) + \sum_{t=1}^C \left( \beta_t v_t k_t^{\top} \prod_{j=t+1}^C \bigl(I - \beta_j k_j k_j^{\top}\bigr) \right). $$
Here:
- $C$: chunk size.
- $S[i]$: input state of chunk $i$.
- $S[i+1]$: output state of chunk $i$, passed to the next chunk.
- $t$: position index inside the chunk, $t = 1, 2, \dots, C$.
- $k_t, v_t$: key and value at position $t$ inside the chunk.
- $\beta_t$: learning rate / forget gate at that position.
And the two terms mean:
- First term: the previous chunk state $S[i]$ after all Delta-rule decays inside the current chunk.
- Second term: each local contribution $\beta_t v_t k_t^T$, further decayed by all later positions $j > t$.
If we directly compute $P[i] = \prod_{t=1}^C (I - \beta_t k_t k_t^T)$:
- Expanding two factors gives: $$(I - \beta_2 k_2 k_2^T)(I - \beta_1 k_1 k_1^T) = I - \beta_2 k_2 k_2^T - \beta_1 k_1 k_1^T + \beta_1\beta_2 k_2 k_2^T k_1 k_1^T$$
- As we keep multiplying, more and more cross terms appear, and after $C$ steps the result becomes a dense matrix with rank $O(C)$.
This is very inefficient because we cannot compute or store it efficiently: it requires $O(d^2)$ space and $O(C d^3)$ compute.
The Solution: WY Representation + UT Transform
WY representation: make chunk accumulation expressible as matrix multiplication
We can see that the high-rank matrix state is a major challenge for chunk-wise compute and storage. So we need a change of representation.
For DeltaNet, a key observation is that although directly computing $\prod (I - \beta_t k_t k_t^T)$ leads to rank explosion, by exploiting properties related to Householder-style transforms, the product can still be written compactly as:
$$ \prod_{i=1}^C \bigl(I - \beta_i k_i k_i^{\top}\bigr) = I - W_C K_C^{\top}, $$
where $W_C \in \mathbb{R}^{C \times d}$ and $K_C \in \mathbb{R}^{C \times d}$.
Then the inter-chunk update becomes:
$$ S[i+1] = S[i] \bigl(I - W[i] K[i]^{\top}\bigr) + U[i]^{\top} K[i] = S[i] - (S[i]W[i])K[i]^{\top} + U[i]^{\top} K[i] $$
Now this is standard matrix multiplication. We can make much better use of Tensor Cores, reducing compute from $O(C d^3)$ to $O(C d^2)$, while state storage drops from $O(d^2)$ to $O(d C)$. That greatly reduces both compute and IO burden.
UT transform: make the computation of W parallelizable too
However, each row $w_t$ in $W$ is still computed recursively:
$$ w_t = \beta_t \Bigl(k_t - \sum_{i=1}^{t-1} w_i (k_i^{\top} k_t)\Bigr) $$
This is still serial and cannot exploit Tensor Cores well.
The UT transform defines a lower triangular matrix $A$ containing the $k_i^T k_j$ information, and converts the recurrence into:
$$ W = T \mathrm{diag}(\beta) K, \qquad \text{where } T = (I - A)^{-1} $$
Because $A$ is strictly lower triangular, $T$ can be solved efficiently by forward substitution, or by direct matrix methods when the chunk is small. As a result:
- The computation becomes matrix math and can use GPU Tensor Cores.
- Computation inside a chunk becomes parallel instead of step-by-step serial execution.
Together, WY representation + UT transform convert DeltaNet’s chunk-local computation into GPU-friendly matrix multiplication, making its chunk-wise parallel algorithm truly practical.
Performance Evaluation and Analysis
Finally, I ran several performance tests for the above algorithms on half an H200 (H200 MIG3-70G).
SIMPLE GLA Performance
Algorithm Properties
Compared with full GLA, Simple GLA uses head-wise gating rather than element-wise gating. This simplification reduces parameter count and also lowers the chance of numerical instability.
Its state update is:
$$S_{t+1} = g_{t+1} \odot S_{t} + K_{t+1} V_{t+1}^{\top}$$
where $g$ is a scalar, so the decay can be fused efficiently into matrix computation.
Benchmark Results
Test configuration: Batch = 4, Heads = 8, d_head = 128, evaluated across different sequence lengths $L$.
Three algorithms were tested:
- Chunk-wise: a chunk-wise implementation with 2 kernels.
- Fused Chunk-wise: a chunk-wise implementation with 1 fused kernel.
- Parallel Scan: sweep up/down based algorithm.
| L | Chunk-wise | Fused Chunk-wise | Parallel Scan |
|---|---|---|---|
| 32 | 0.099184 | 0.045680 | 0.013440 |
| 64 | 0.093040 | 0.044832 | 0.018016 |
| 128 | 0.113344 | 0.070464 | 0.020704 |
| 256 | 0.111024 | 0.112288 | 0.034528 |
| 512 | 0.172096 | 0.281088 | 0.064032 |
| 1024 | 0.498624 | 0.546480 | 0.150272 |
| 2048 | 0.985968 | 1.078208 | 0.422528 |
| 4096 | 1.955248 | 2.132128 | 1.350048 |
| 8192 | 3.882000 | 4.229376 | 4.766928 |
| 16384 | 7.750400 | 8.427360 | 17.839392 |
We can see that for relatively short sequences, for example $L \le 4096$, Parallel Scan has a clearer advantage. This mainly comes from two reasons:
- The critical path of scan is $O(\log L)$ rounds of up-sweep / down-sweep, so the number of rounds is small for short sequences.
- These implementations often reduce “state merging” to lightweight vector or small-matrix operations, so the kernel itself is more latency-bound and therefore can win for short $L$.
But as the sequence gets longer, we observe an inflection point around $L \approx 8192$, and by $L = 16384$ the gap becomes large. Parallel Scan gradually slows down because:
- The number of sweep rounds grows with $\log L$, and each round involves global synchronization or cross-block data exchange, making the algorithm increasingly memory-bound.
- The arithmetic intensity of scan is relatively low, so with longer sequences it gets limited by HBM bandwidth and synchronization overhead.
By contrast, the two-pass chunk-wise structure keeps Tensor Cores busier on long sequences. Pass 1 only updates states at chunk boundaries, while Pass 2 performs larger-granularity matrix operations inside chunks, which have higher arithmetic intensity. So throughput remains more stable as $L$ grows.
Also note that although Fused Chunk-wise launches only one kernel, that single kernel has to perform both Pass 1 and Pass 2. To avoid writing intermediate states to HBM, it tries to keep more intermediate quantities and states, such as accumulated state $S$ or chunk boundary states, in registers.
That raises register pressure and lowers occupancy. In extreme cases, it may even trigger register spilling into local memory, which is why on long sequences it can actually underperform the two-kernel chunk-wise implementation.
DeltaNet Performance
In this section I use DeltaNet as an example. I will first present the core benchmark results, and then explain why some parallelization strategies, especially Parallel Scan-based ones, fail in practice.
For different sequence lengths $L$, the results are:
| L | Chunk-wise Parallel | Parallel Scan |
|---|---|---|
| 128 | 0.178384 | 0.159504 |
| 256 | 0.172256 | 0.159840 |
| 512 | 0.185056 | 0.210512 |
| 1024 | 0.198560 | 0.478272 |
| 2048 | 0.350336 | 1.239392 |
| 4096 | 0.674592 | 3.765408 |
| 8192 | 1.318208 | 12.916416 |
| 16384 | 2.600304 | 47.368912 |
Why the Gap Appears
We can see that for DeltaNet, the advantage of Parallel Scan becomes much smaller, and by $L = 512$ the chunk-wise algorithm already overtakes it.
To understand why, let us rewrite DeltaNet’s single-step update:
$$ S_t = S_{t-1}(I - \beta_t k_t k_t^{\top}) + \beta_t v_t k_t^{\top}. $$
Define:
$$M_t = I - \beta_t k_t k_t^{\top} \in\mathbb{R}^{d\times d}$$
$$B_t = \beta_t v_t k_t^{\top} \in\mathbb{R}^{d\times d}$$
Then each step is an affine transform of the matrix state $S$:
$$S_t = S_{t-1} M_t + B_t$$
To accelerate this with Parallel Scan, we can keep using the operator defined earlier:
$$(A_j,b_j)\otimes (A_i,b_i) = (A_j A_i,; A_j b_i + b_j),$$
which means “apply transform $i$ first, then transform $j$”.
Applying this operator to the sequence $(M_t, B_t)$ gives:
$$S_1 = S_0 M_1 + B_1$$ $$S_2 = S_1 M_2 + B_2 = S_0 (M_1 M_2) + (B_1 M_2 + B_2)$$
So when merging an interval, we must multiply the corresponding $M$ matrices to produce terms like $M_1 M_2$, and also transform and accumulate the earlier $B$ values to produce terms like $B_1 M_2 + B_2$. These are both heavy matrix operations, which is the fundamental reason Parallel Scan is inefficient for DeltaNet:
-
The merge must explicitly compute and store $M$. For ordinary linear attention with additive accumulation, scan merges fixed-shape small matrices or vectors, so the operator is light. But in DeltaNet the merged object is a full $d \times d$ matrix, and computing terms like $M_1 M_2$ is much more expensive.
-
Low-rank structure is hard to preserve during merge. A single-step matrix $M_t = I - \beta_t k_t k_t^T$ is a rank-1 update, but after two multiplications: $$ (I - \beta_2 k_2 k_2^T)(I - \beta_1 k_1 k_1^T) = I - \beta_1 k_1 k_1^T - \beta_2 k_2 k_2^T + \beta_1\beta_2 k_2 (k_2^T k_1) k_1^T $$ cross terms keep appearing. If we try to write the product over an interval of length $m$ as “identity minus low rank”, the effective rank generally grows with $m$, intuitively close to $O(m)$.
That means if scan tries to carry only low-rank factors, for example in the form $I - W K^T$, then at higher up-sweep levels the row counts of $W$ and $K$ keep growing. The intermediate state is no longer constant-sized, so it cannot be implemented efficiently with the fixed-shape tensors that ordinary scan relies on.
Although Parallel Scan uses only $O(\log L)$ rounds, every round performs one full pass of “merge + global read/write + synchronization” over the sequence. Once the merge operator itself becomes a large matrix operation, the runtime starts to blow up with sequence length, exactly like the trend shown in the table.
Summary
So even within linear attention, there are multiple engineering implementations, but for any specific operator you still need to pick the right algorithm based on the operator’s structure and runtime regime, such as sequence length.
Last modified on 2026-01-01