I am planning to write a series of posts about linear attention and use them to organize some of the relevant theory and engineering ideas. This article focuses on the fundamentals.
From Softmax Attention to Linear Attention
Softmax Attention and the $O(N^2)$ Bottleneck
Standard Transformers use softmax attention. Given query, key, and value matrices $Q, K, V \in \mathbb{R}^{N \times d}$, where $N$ is the sequence length and $d$ is the feature dimension, the formula is:
$$ Attention(Q, K, V) = \text{softmax}\left(\frac{QK^T}{\sqrt{d}}\right)V $$
Let us unpack the dimensions step by step:
- Similarity matrix: compute $QK^T$.
- $Q$ has shape $N \times d$ and $K^T$ has shape $d \times N$.
- The result is an $N \times N$ matrix.
- The computational complexity is $O(N^2 d)$.
- Softmax: normalize each row. The shape stays $N \times N$.
- Weighted sum: multiply by $V$.
- An $N \times N$ matrix times an $N \times d$ matrix gives an $N \times d$ output.
- This step is also $O(N^2 d)$.
The core bottleneck is that softmax is nonlinear, so the full $N \times N$ attention matrix must be formed before the weighted sum can happen.
- Compute complexity: $O(N^2 d)$
- Memory usage: $O(N^2)$ if we ignore FlashAttention-like optimizations
- KV cache: during inference we need to keep all keys and values, which costs $O(Nd)$
For a long time this was acceptable, but as agent workloads push context windows longer and longer, the $O(N^2)$ cost is becoming too expensive.
Linear Attention
The core idea of linear attention is simple: if we can remove softmax, or replace it with a kernelized feature map $\phi(\cdot)$, then we can exploit associativity in matrix multiplication.
Suppose we define the similarity as $\text{sim}(q, k) = \phi(q)^T \phi(k)$, where $\phi(\cdot)$ maps inputs into a feature space. Then the attention formula becomes:
$$ Attention(Q, K, V) = \left( \phi(Q) \phi(K)^T \right) V $$
Using associativity,
$$ Attention(Q, K, V) = \phi(Q) \left( \phi(K)^T V \right) $$
Ignoring the normalization term for the moment, we can now change the computation order:
- First compute $\phi(K)^T V$
- $\phi(K)^T$ is $d \times N$, and $V$ is $N \times d$
- The result is a $d \times d$ matrix, often called the state matrix or KV memory
- Complexity: $O(N d^2)$
- Then left-multiply by $\phi(Q)$
- Complexity: another $O(N d^2)$
The benefits are immediate:
- Total complexity: $O(N d^2)$, which is linear in sequence length when $d$ is treated as a small constant
- Memory usage: the main state is just a fixed-size $d \times d$ matrix and no longer grows with $N$
The RNN View
Linear attention is not only more efficient, it can also be written as an RNN, which makes it very friendly for autoregressive inference.
For token $t$, the output is:
$$ o_t = \sum_{i=1}^t \text{sim}(q_t, k_i) v_i = \sum_{i=1}^t (\phi(q_t)^T \phi(k_i)) v_i $$
Pulling out the query-dependent term:
$$ o_t = \phi(q_t)^T \sum_{i=1}^t \phi(k_i) v_i^T $$
Define the state
$$ S_t = \sum_{i=1}^t \phi(k_i) v_i^T $$
Then we get the recursion:
$$ S_t = S_{t-1} + \phi(k_t) v_t^T $$ $$ o_t = \phi(q_t)^T S_t $$
This is the RNN form of linear attention:
- Update the state with the current $k_t$ and $v_t$
- Query the state with $q_t$
That explains why linear attention is so efficient at inference time. Unlike softmax attention, it does not have to revisit the entire historical KV cache. It only maintains a fixed-size state.
Design Ideas and Major Families of Linear Attention
The classical form of linear attention is elegant, but not very strong in practice. To make it work, researchers had to find better ways to design the recurrence.
There are many equivalent narratives for linear attention. Here I will use Mamba and DeltaNet as representative examples.
State Space Models
The Mamba family is built on state space models, which originally come from control theory.
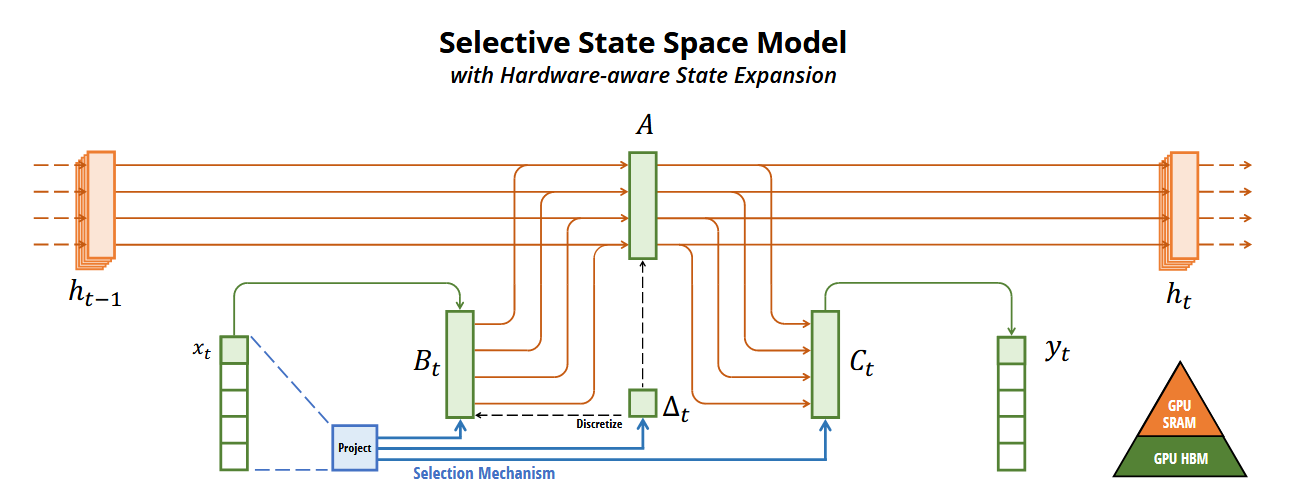
Mamba SSM Architecture
In continuous time, an SSM describes a system whose hidden state evolves according to:
$$ h’(t) = A h(t) + B x(t) $$ $$ y(t) = C h(t) $$
where $A$ is the state-transition matrix, $B$ projects inputs into the state, and $C$ projects the state back to the output.
To process discrete token sequences we have to discretize the system. A common choice is zero-order hold, which gives a recurrence:
$$ h_t = \bar{A}t h{t-1} + \bar{B}_t x_t $$ $$ y_t = C h_t $$
with $\bar{A}_t$ and $\bar{B}_t$ derived from $A$, $B$, and the step size $\Delta_t$.
This looks strikingly similar to the RNN form of linear attention:
- Linear attention: $S_t = I \cdot S_{t-1} + \phi(k_t) v_t^T$
- SSM: $h_t = \bar{A}t h{t-1} + \bar{B}_t x_t$
If we interpret decay in linear attention as the transition matrix $\bar{A}$, and the key-value update as the input term, the two views become tightly connected.
Mamba’s main innovation is the selection mechanism, which makes parameters such as $B$, $C$, and $\Delta$ functions of the input itself. That allows the model to decide dynamically what to retain and what to forget, overcoming the lack of context sensitivity in a plain linear time-invariant system.
Semiseparable Matrices
If we expand the SSM recurrence over a whole sequence, the transformation can be written as $y = Mx$, where $M$ is a lower-triangular matrix. That matrix has a semiseparable structure.
$$ M = \begin{pmatrix} C_0 B_0 & 0 & \dots & 0 \ C_1 A_1 B_0 & C_1 B_1 & \dots & 0 \ \vdots & \vdots & \ddots & \vdots \ C_L A_L \dots A_1 B_0 & \dots & \dots & C_L B_L \end{pmatrix} $$
When the state-transition matrix is diagonal, the cumulative product can be factorized. If we define $L_t = \prod_{k=1}^t A_k$, then for $i > j$:
$$ A_i \dots A_{j+1} = L_i L_j^{-1} $$
Substituting that back into the matrix gives a factorization that matches the linear-attention form:
$$ y_i = \sum_{j=0}^i (Q_i K_j^T) V_j $$
That is the key observation behind the state-space duality in Mamba2: the same system can be seen either as an SSM recurrence for efficient inference or as an attention-like matrix factorization for parallel training.
Mamba2 SSD Architecture
Mamba2 keeps the general shape of Mamba, but adds stronger structural constraints to make hardware usage much more efficient.
The most important change is that inside one head, the transition parameter is simplified from a diagonal matrix to a scalar. This reduces expressiveness a little, but it allows the whole computation to be rewritten as block matrix multiplication that runs efficiently on Tensor Cores.
So Mamba2 is really an algorithm-hardware co-design: it gives up some modeling freedom in exchange for much better hardware efficiency, and then recovers practical performance by scaling state dimension and model size.
Mamba3
Mamba3 continues that line of work and tries to recover some of the expressiveness Mamba2 gave up.
The major ideas include:
- Complex state spaces: the transition parameter becomes complex-valued, so the state can rotate as well as decay, which improves long-range and periodic modeling.
- Trapezoidal discretization: instead of zero-order hold, it uses a more accurate numerical discretization.
- Multi-input multi-output interactions: it allows richer channel interaction while still targeting Tensor Core efficiency.
Orthogonality Assumptions and the Delta Rule
DeltaNet develops linear attention from another angle.
In standard linear attention, the state update is just:
$$ S_t = S_{t-1} + k_t v_t^T $$
This resembles Hebbian learning: if key and value co-occur, strengthen the association.
But this update quietly assumes that keys are close to orthogonal. If the current key is highly correlated with previous keys, then a new write changes not only the intended memory slot but also the projections associated with older keys. That creates interference.
There are two common forms of this conflict:
- One key, multiple meanings: similar keys can appear multiple times in different contexts but correspond to different values.
- Correlated keys: if keys are not orthogonal, writing a new key perturbs older memories and causes crosstalk.
Softmax attention handles this by explicitly looking at all historical keys and weighting values dynamically. Linear attention, by contrast, compresses all history into a fixed-size state and therefore has to manage interference directly.
Delta Rule
DeltaNet introduces the Delta Rule, also known as the Widrow-Hoff rule or LMS update:
$$ S_t = S_{t-1} + \beta_t (v_t - S_{t-1} k_t) k_t^T $$
The interpretation is straightforward:
- Predict: $S_{t-1} k_t$ is the old state’s prediction for the current key.
- Measure error: $e_t = v_t - S_{t-1} k_t$
- Correct: only write the residual error back into the state.
This is effectively one step of online gradient descent, which lets the model store and retrieve information much more accurately under a fixed-capacity state.
If the previous state is zero, or if keys are assumed orthogonal so that $S_{t-1} k_t \approx 0$, the rule simplifies back to the standard linear-attention update. That gives a neat interpretation:
- standard linear attention is the lazy update that assumes orthogonal keys
- DeltaNet performs the full residual correction
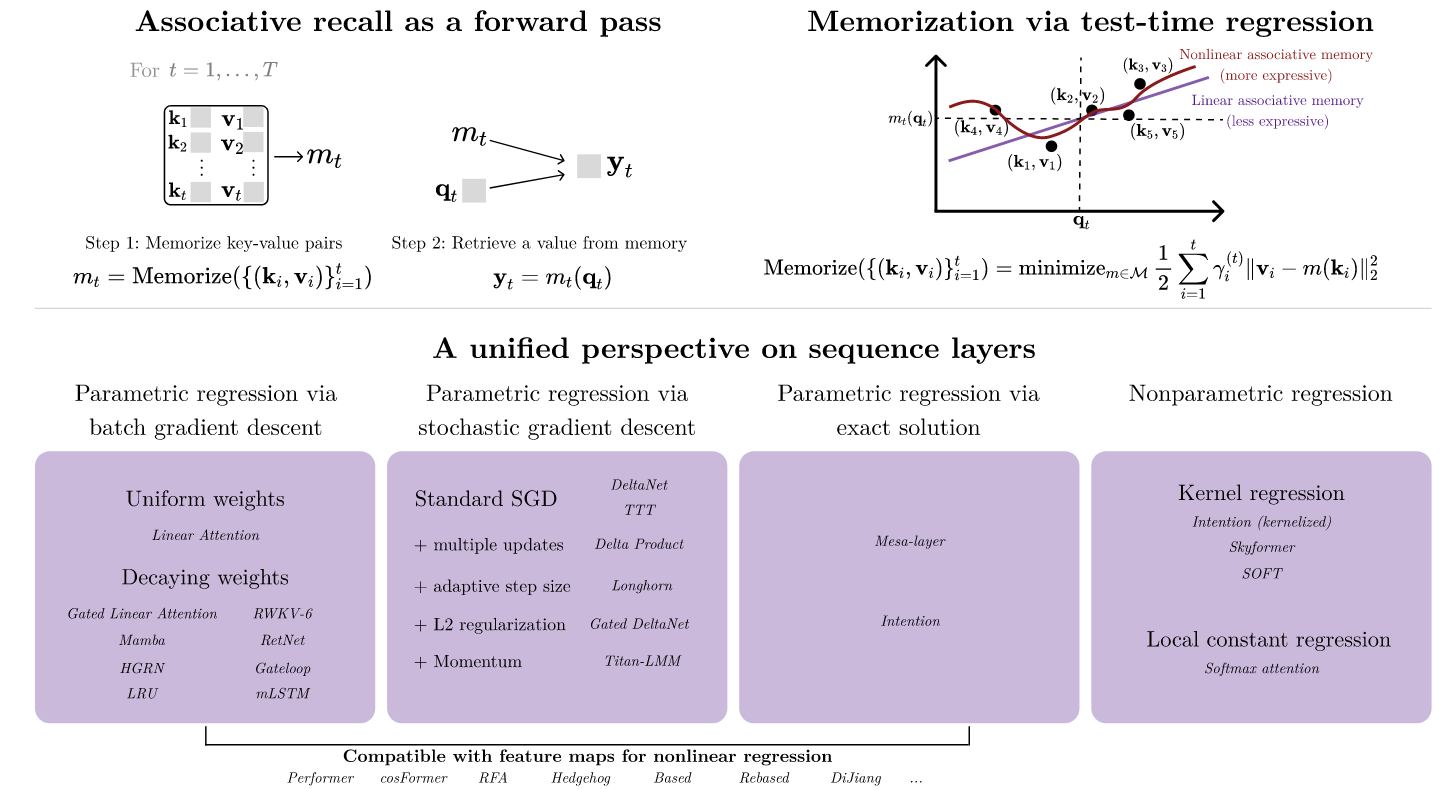
This viewpoint also connects naturally to newer ideas such as RWKV-7 and TTT-Linear, where the hidden state is treated as the parameter of a small model that is trained online during inference.
That perspective explains one of the main weaknesses of linear attention in needle-in-a-haystack tasks: compression is inherently lossy. When exact retrieval of a very specific historical detail matters, a compressed parametric state is at a disadvantage relative to full attention, which can still look back at the original history.
Forgetting Mechanisms
Standard linear attention usually treats all history equally. But in language modeling, locality matters: recent tokens are often more important than distant ones.
RetNet and related models introduce an exponential decay:
$$ S_t = \gamma S_{t-1} + k_t v_t^T $$
where $\gamma \in (0, 1)$ is a decay factor.
This acts like a soft sliding window. The farther back a token is, the smaller its contribution becomes. It also improves numerical stability by preventing the state from growing without bound.
Some models go further and use per-head or even per-dimension decay so that different channels can specialize in different time scales.
Test-Time Regression as a Unifying Framework
The paper Test-time regression: a unifying framework for designing sequence models with associative memory provides a very helpful perspective. It views attention as a regression problem performed at inference time.
We can think of the model as learning a function $f: \mathbb{R}^d \to \mathbb{R}^d$ such that $f(k_i) \approx v_i$.
Full Attention as Nonparametric Regression
Full attention corresponds to nonparametric regression, or the dual form.
- The model explicitly stores all past samples $(K, V)$.
- When a new query arrives, it compares the query to all previous keys and computes a weighted average of the values.
$$ o = \sum_i \frac{K(q, k_i)}{\sum_j K(q, k_j)} v_i $$
The capacity therefore grows with sequence length, and the model can in principle remember arbitrary details as long as it can afford the compute.
Linear Attention as Parametric Regression
Linear attention corresponds to parametric regression, or the primal form.
- Instead of storing all data, it maintains a fixed-size parameter matrix $S$.
- Processing a sequence is equivalent to updating that parameter online.
- Prediction for a new query is just:
$$ o = S q $$
The state is efficient, but its capacity is bounded. If the history becomes too rich, the compressed state saturates and old information is forgotten.
Gradient-Descent Derivation
Suppose we want to learn a matrix $S$ such that $S k_t \approx v_t$. Define the instantaneous least-squares loss:
$$ L_t(S) = \frac{1}{2} | S k_t - v_t |^2 $$
A stochastic gradient step gives:
$$ S_t = S_{t-1} - \eta \nabla_S L_t(S_{t-1}) $$
The gradient is:
$$ \nabla_S L_t(S) = (S k_t - v_t) k_t^T $$
So the update becomes:
$$ S_t = S_{t-1} + \eta (v_t - S_{t-1} k_t) k_t^T $$
This is exactly the Delta Rule.
Tricks and Optimizations
To compensate for some of the weaknesses of linear attention, such as poor local focus and numerical issues, a number of practical tricks have been proposed.
Causal Convolution and Token Shift
Softmax attention naturally tends to focus on local neighbors. Linear attention often produces smoother, less local behavior. To compensate for that, models such as Mamba, RWKV, and RetNet usually add a short-window causal convolution before the recurrent state update.
RWKV-4 introduced a very lightweight version called Token Shift, which linearly interpolates the current token and the previous token. Mamba uses an explicit 1D convolution, usually with a small kernel such as 4.
The point is to let the model explicitly capture short-range local structure, while the recurrent state focuses on long-range dependencies.
DPLR Matrices
Early SSM work such as S4 used diagonal-plus-low-rank (DPLR) parameterizations of the transition matrix:
$$ A = \Lambda - pp^* $$
This gives better numerical stability and enables efficient algorithms for matrix inversion and convolution kernels. Mamba later simplified this structure for hardware reasons, but DPLR remains important for understanding the theory behind state-space models.
Positional Encoding
Most modern linear-attention variants use NoPE, but that does not mean position information is impossible.
RetNet showed one way to fold positional information into the recurrent decay itself, for example through a complex factor:
$$ S_t = \gamma e^{i\theta} S_{t-1} + k_t v_t^T $$
This preserves the efficient recurrence while still encoding a relative-position bias.
ROSA
Finally, RWKV-8 introduces a direction called ROSA, which tries to recover historical information by attaching a structured retrieval system to the recurrent model.
Instead of relying purely on hidden-state compression, ROSA builds a suffix-automaton-like structure online during inference. It indexes not only input tokens, but also layer-wise hidden features after binarization. At inference time it can quickly retrieve the longest matching historical fragment and reuse the associated continuation state for prediction.
This is a very different memory design from the test-time-training view, and it feels like a direction with a lot of potential. It will be worth revisiting once the formal paper and larger-scale results are available.
Last modified on 2025-12-16