Background
Ever since R1 took off earlier this year, I have seen a lot of discussion about the nature of intelligence. A large part of that discussion seems to converge on one view: language is the foundation of intelligence, and the path to AGI runs through language.
Zhang Xiaojun’s interviews this year with several researchers include two representative examples:
- Yang Zhilin argued that under the current paradigm, multimodal capability often does not improve a model’s “IQ”, and may even harm the language intelligence it already has. In one interview he said that if you want to add multimodal capability, you need to make sure it does not damage the model’s “brain”. At best, multimodality should reuse the intelligence already stored in the text model, instead of creating an entirely separate parameter system that overwrites it.
- Yao Shunyu also emphasized that language seems more fundamental on the road to general intelligence. He originally worked in computer vision, but later concluded that language was the more central and more promising direction. In his view, language is the most important tool humans invented for cognitive generalization, because it forms a closed loop between generation and reasoning.
There are, however, other viewpoints. Some researchers argue that the potential of multimodal capability may be constrained more by the current training paradigm than by multimodality itself. Zhang Xiangyu, for example, pointed out two things:
- A lot of image-text data is noisy. If we simply mix visual and textual data without solving the chain-of-thought and task-complexity issues, training can even become harmful. Models may take shortcuts and jump directly to answers instead of reasoning carefully, which introduces chaotic gradients and can actually reduce math and logic performance.
- Visual reasoning may also need the right kind of pretraining activation. In OpenAI’s O3, the model can directly manipulate images during reasoning by cropping, rotating, and zooming. Surprisingly, some of these operations are quite simple, but they work well. A possible explanation is that pretraining corpora already contain many patterns where people inspect a full image, then zoom in on local regions and explain them.
I want to write down some of my own understanding and views on this topic.
Studying Reasoning in Vision Language Models
Before diving in, let me define what I mean by “IQ” here. A model’s abilities can roughly be split into understanding, reasoning, and generation. In this framing, reasoning is what I mean by intelligence.
Vision CoT
Chain-of-thought was one of the earliest paradigms proven to improve complex reasoning in LLMs. Its visual extension, Vision CoT or Visual CoT, started appearing around 2023.
At first, the input combined text and image, but the chain of thought was still purely textual. In that setting the image did not participate in the reasoning process itself, so it was hard to argue that the image improved reasoning ability as such.
Later, O3 popularized a new direction: thinking with images. The key idea is that image understanding should not be a one-shot input stage. Instead, the image should enter the iterative reasoning loop and become part of the intermediate state.
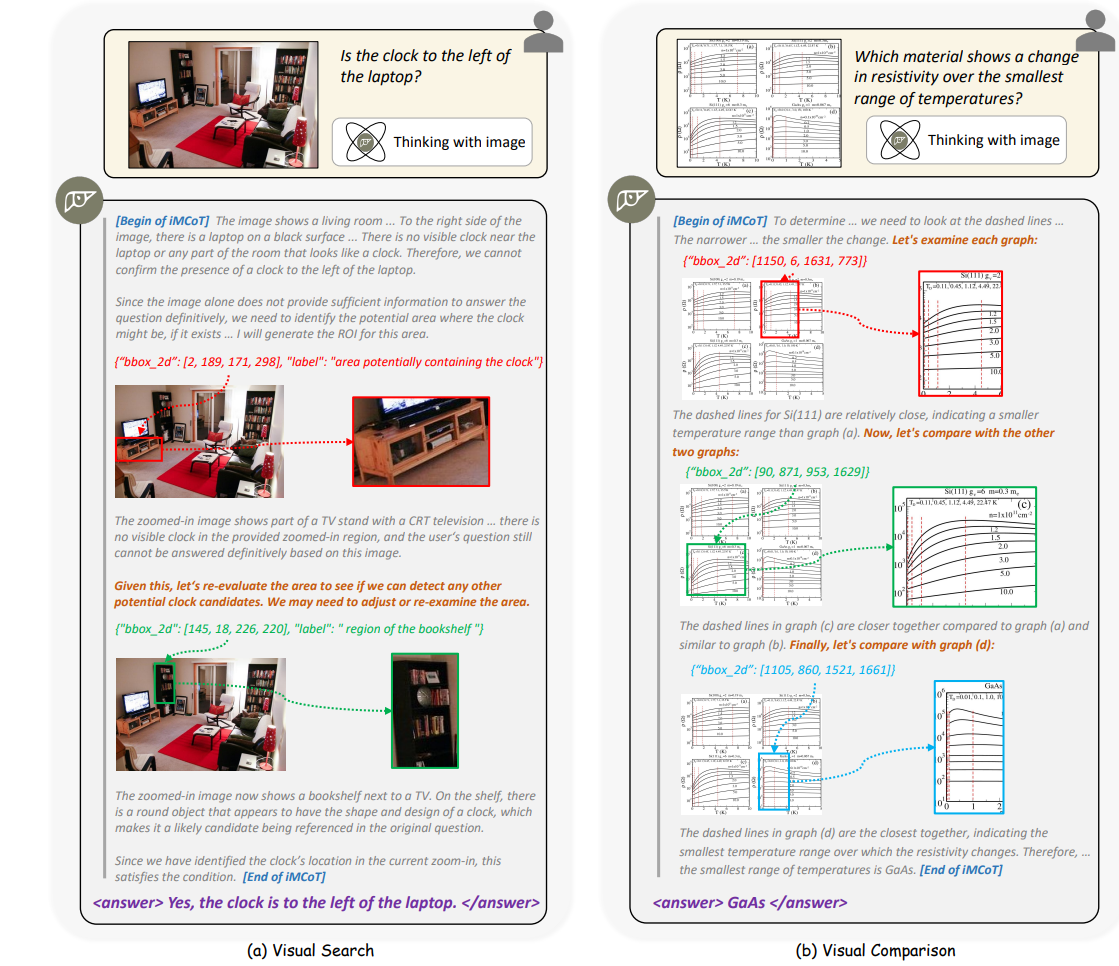
OpenAI O1 / O3
OpenAI’s o1 series was one of the first strong demonstrations of the relationship between test-time scaling and reasoning ability. O3 pushed the idea further. In demos it showed not only that the model could “look at images”, but that it could also “think with images” by:
- actively locating relevant regions
- zooming in on formulas or local structures
- rotating views when useful
- feeding local visual observations into later reasoning steps
O3 reached 95.7% on the visual reasoning benchmark V*Bench, which strongly suggests that explicitly incorporating vision into the chain of thought is a viable research direction.
DeepEyes
DeepEyes was probably the first open-source project to reproduce a version of “thinking with images”. Instead of relying on additional human SFT, it uses RL to activate the model’s step-by-step visual focusing behavior.
The loop is roughly:
- produce an initial reasoning trace
- judge whether more detail is needed
- invoke zoom or crop operations autonomously
- re-encode the cropped image region
- continue the reasoning process
The project reports that:
- a 7B model beats a larger 32B model on fine-grained visual reasoning tasks
- visual thought traces also improve math and abstract reasoning on image-related datasets, suggesting positive transfer into the language backbone
Pixel-Reasoner
Pixel-Reasoner takes a similar route, but makes visual operations themselves, such as zooming and region selection, into explicit reasoning tokens. It extends reasoning from text space into pixel space.
Training happens in two phases:
- instruction tuning on synthetic template data to teach the model the syntax of visual operations
- curiosity-driven RL to overcome the tendency to stay on the language-only shortcut and to call visual functions when needed
The result is that a 7B model reaches or approaches state-of-the-art open-source performance on tasks such as V*Bench, TallyQA-Complex, and InfographicsVQA.
A First Summary
These Vision CoT studies suggest that incorporating vision into the chain of thought can improve model behavior, at least on vision-language datasets. So why do many people still argue that language remains the real core of reasoning? That is the question for the next section.
Visual Tool Chains: Looking Again vs Actually Thinking with Images
The examples above all look like “thinking with images”, but if we examine them more closely, most of the mechanism still looks like repeatedly operating on images in order to validate and refine a reasoning process.
It helps to compare this with a purely textual CoT project such as R1-V. R1-V applies RLVR to a VLM while keeping the reasoning trace itself textual, and still achieves large gains.
That result suggests that even with a text-only chain of thought, a model can repeatedly inspect visual cues, focus on local evidence, verify counts from multiple angles, and then summarize in language.
In other words, even when the system uses visual tools, the real gain may not be a new reasoning capability. It may simply be better information acquisition. The ability to decide what information matters is still largely mediated by language.
If we focus specifically on reasoning ability, the central question becomes:
Is vision improving the reasoning process itself, or is it mainly acting as an additional information channel or tool?
Several observations support the latter interpretation.
Adaptive Visual Calls
Pixel-Reasoner shows that early in training the model tends to ignore visual operations, because the language path is the path of least resistance. Curiosity rewards push it to explore the visual action space. Once the policy matures, the model moves from blind repeated zooming to targeted and minimal zooming. The number of visual operations decreases, but the information density of those operations improves.
Stepwise Solving and Long-Horizon Verification
O3, DeepEyes, Kimi-VL, and related work also suggest that visual test-time scaling often behaves like this:
look again, gather more evidence, verify intermediate conclusions, and therefore improve confidence and error correction.
Summary
Seen from that angle, most current so-called visual reasoning is closer to this pattern:
improve image attention, possibly with tools such as HTML generation, resize, or crop; gather new evidence; correct the model’s focus; then improve the language chain of thought.
That looks more like information completion than truly native image-based reasoning.
Benchmarks: The Two Sides of Vision for Reasoning
Once we treat vision as an additional source of information, another question naturally follows: does adding vision always help, or can it also hurt?
The answer seems to depend on whether the model learns to conditionally and selectively bring visual information into the reasoning backbone.
The Positive Side: New Evidence
Vision helps when it contributes evidence that text alone does not provide, for example:
- restoring blurry or irregular symbols such as handwritten formulas or road signs
- recovering structural, spatial, or counting information omitted from text
- providing concrete world details such as color, position, and relative layout
DeepEyes solves detail-heavy questions after local cropping. O1 improves scientific question answering when visual input is enabled. These are all examples of vision acting as an information completer.
The Negative Side: Noise and Attention Dilution
But vision can also introduce failure modes:
- Bypassing: the model follows the language prior and ignores the image
- Forced attention: the model is forced to describe the image but still misses the key details, which increases hallucination
- Gradient noise: noisy image-text pairs dilute useful information at each step of the chain of thought
- Shortcut overfitting: the model learns statistical shortcuts and fails badly out of distribution or on detail-sensitive tasks
Common Mitigations
Recent work addresses those issues in several ways:
- dataset filtering that removes samples with no visual gain or the wrong difficulty level
- extra reward for correct and useful tool use
- curiosity and exploration bonuses early on, followed by more targeted behavior later
- explicit visual-action APIs instead of opaque fusion
- filtering out trajectories that bypass vision entirely
Summary
If vision is treated as another information source, then the research direction naturally shifts away from just adding more multimodal data and toward teaching models when to look, how to look, and how efficiently to look.
Vision and Intelligence
This section focuses on two questions:
- Why does “strong vision + strong language” not automatically imply much stronger reasoning?
- In today’s large models, is vision really a collaborative cognitive module, or mostly an external tool layer?
Ability Independence: Understanding, Generation, and Reasoning Do Not Automatically Reinforce Each Other
For text tasks, understanding, generation, and reasoning often look mutually reinforcing. But for image data, those abilities still seem quite fragmented.
In early multimodal practice, even when huge amounts of image-text pretraining data were added, image understanding and image generation often behaved like two parallel modules. Improving one did not necessarily improve the other. Models such as Ming-Omni even use a two-stage recipe of “perception first, generation later”, freezing the backbone in the generation stage to avoid contaminating the reasoning path.
There are several likely reasons:
- language and vision have conflicting characteristics: vision is dense and local, while language is sparse and semantically compressed
- cross-modal alignment often stays at the embedding or projection level and does not deeply share the strategy layer where planning and decomposition happen
- the roles in pretraining data are already specialized: language organizes, verifies, and reflects, while vision mostly supplies raw evidence
So the conclusion for now is that visual understanding, generation, and reasoning behave more like cooperating plugins. Our current training recipes and data regimes are not enough for visual data to directly improve reasoning ability.
The Tool View: Vision Is Still Mostly an External Device
DeepEyes and Pixel-Reasoner both decompose visual processing into explicit actions such as cropping, zooming, and frame selection. In essence, they translate vision into a set of discrete tool tokens.
This is a white-box approach:
- it is controllable because the model explicitly decides when and how often to call a visual tool
- it is interpretable because the reasoning trajectory leaves behind a visible inspect-and-confirm trail
- it is optimizable because reward can be attached directly to whether visual tools were called and whether they were useful
But that white-box design also reveals the limitation. Vision is still mostly acting as a plugin for evidence gathering. The core reasoning remains language-driven. We still do not really have vision participating in hypothesis generation, counterfactual construction, or strategic branching in the same way language does.
The dominant loop is still:
language raises a question -> vision gathers evidence -> language summarizes.
That is not yet a fully bidirectional cognitive loop.
Summary
At the moment, vision still seems to play a supporting role in LLM reasoning. It can help the model reason better by providing better evidence, but it does not yet appear to push the model’s core reasoning ability into a fundamentally new stage. In fact, because the model has to spend parameters on handling images, it is not surprising that multimodal systems often count as successful if they can preserve language performance rather than improve it.
Other Research and Some Personal Views
Other Research Directions
So far I have argued that current systems are not really “thinking with images” in a strong sense. What would that stronger form look like?
There are some more radical explorations outside the main line:
- Thinking with Generated Images lets a model actively generate intermediate images during reasoning, using them as visual thought steps and bouncing between image and text to validate and revise hypotheses.
- Visual Planning: Let’s Think Only with Images goes even further and proposes planning entirely with sequences of images. In visual navigation and related tasks, this can outperform language-based planning and argues that language is not always the best carrier for reasoning, especially in spatial settings.
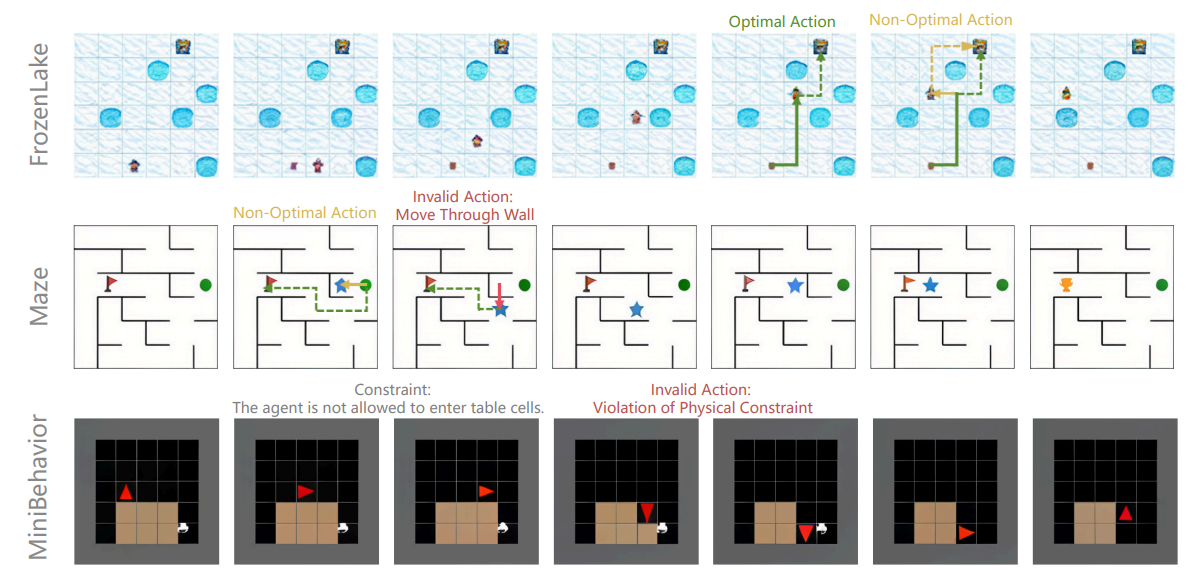
Those lines of work try to let vision participate more directly in the reasoning logic itself. But because of current limitations in data, task design, and scaling recipes, they are still far from becoming mainstream large-scale training paradigms.
My Own View
My current opinion is that under today’s approaches, images do not really improve reasoning ability by themselves. They mainly serve as a specialized tool. If we want multimodal data to truly improve reasoning, we will probably need tasks and data that jointly integrate understanding, generation, and reasoning across modalities, and only then will scaling laws have a chance to amplify that intelligence.
Perhaps in the era of experience, embodied systems interacting with the real world will finally provide the right data and tasks for that to happen.
References
[1] Conversation with Yang Zhilin after one year: K2, Agentic LLMs, Brain in a Vat, and Standing at the Infinite Beginning https://www.xiaoyuzhoufm.com/episode/68ae86d18ce45d46d49c4d50
[2] A three-hour interview with OpenAI’s Yao Shunyu: six years of agent research, humans and systems, and the boundaries of consumption https://www.xiaoyuzhoufm.com/episode/68c29ca12c82c9dccadba127
[3] A conversation with Zhang Xiangyu on the struggle and future of multimodal research https://www.xiaoyuzhoufm.com/episode/683d2ceb38dcc57c641a7d0f
[4] OpenAI o1 System Card - arXiv https://arxiv.org/abs/2412.16720
[5] Thinking with images https://openai.com/index/thinking-with-images/
[6] DeepEyes: Incentivizing “Thinking with Images” via Reinforcement Learning https://arxiv.org/abs/2505.14362
[7] Pixel Reasoner: Incentivizing Pixel-Space Reasoning with Curiosity-Driven Reinforcement Learning https://arxiv.org/abs/2505.15966v2
[8] Self-Imagine: Effective Unimodal Reasoning with Multimodal Models using Self-Imagination https://arxiv.org/abs/2401.08025v2
[9] R1-V: Reinforcing Super Generalization Ability in Vision Language Models with Less Than $3 https://github.com/StarsfieldAI/R1-V
[10] Ming-Omni: A Unified Multimodal Model for Perception and Generation https://arxiv.org/abs/2506.09344
[11] Visual Planning: Let’s Think Only with Images https://arxiv.org/abs/2505.11409
[12] Thinking with Generated Images https://arxiv.org/abs/2505.22525
Last modified on 2025-09-15