In the previous article I discussed Ray and the evolution of LLM reinforcement learning frameworks, but I did not really explain why frameworks evolved in that direction instead of starting there from day one. Part of the answer is of course repeated practical optimization, but another equally important part is that the underlying demands of LLM RL also changed.
This article focuses on how algorithms and system frameworks influence each other and co-evolve in LLM reinforcement learning. I will start with two relatively mature case studies, then move on to a few directions that still feel unsettled but, in my view, have a lot of potential.
Typical Cases of Algorithm-System Co-Evolution
Let us begin with two issues where the community already has some degree of consensus.
Case 1: Reasoning Models Driving Disaggregated Architectures
As mentioned in the previous article, earlier RL systems tried to stay as on-policy as possible, so the common design was an on-policy algorithm paired with a colocated architecture. That choice made sense. On the algorithm side, on-policy methods do have sample-efficiency advantages. On the system side, before CoT and test-time scaling became dominant, output lengths were shorter and the compute bubbles caused by inference engines were still tolerable.
But starting from the release of o1, and then especially after R1, the industry started to care much more about test-time scaling. The balance changed. Models began producing much longer outputs during reasoning, and the variance in output length across samples became huge. Under that computation pattern, the algorithmic advantage of on-policy training could no longer compensate for the massive waste of system resources. All parallel environments had to wait for the single slowest reasoning trace before the next iteration could begin.

That challenge pushed the industry toward asynchronous RL framework design. The core idea is to fully decouple generation and training and treat them as a producer-consumer pipeline.
Examples such as AsyncFlow and AReaL follow this pattern:
- Rollout workers continuously generate new data asynchronously without waiting for each other.
- Trainer workers asynchronously pull data from a shared buffer and update the model.
This streaming RL design avoids having the entire system blocked by slow inference jobs, keeps compute devices busy, and significantly improves throughput. It is a clean example of algorithm-system co-design: a new demand forced a new tradeoff, and that tradeoff led to a new architecture.
Case 2: MoE Models and Train-Infer Alignment
Another challenge appears at the system level when extremely large or MoE models are involved: the mismatch between the training engine and the inference engine.
In RL training, generation often happens inside a dedicated inference engine such as vLLM, while gradient computation happens inside a training backend such as DeepSpeed. Those engines may differ in numerical precision, fused kernels, batching logic, or MoE routing behavior. As a result, rollout data and training-time computation can drift apart.
This issue existed even before MoE. For example, Xiaohongshu mentioned the need for strict train-infer consistency in a QCon talk and ended up building internal infrastructure for alignment. Some teams generate data with an inference engine and then re-run inference in the training engine to recover logits for probability computation.
But MoE and aggressive inference acceleration have made the problem much harder. Routing mismatch in MoE can be much larger than simple numeric mismatch in dense models. The actual token trajectory sampled by the inference engine can diverge significantly from what the training engine would have sampled. Recomputing probabilities in the training engine is no longer enough.
To address this, the AReaL framework proposed Decoupled PPO. The idea is elegant: use inference-engine probabilities for importance sampling, because those probabilities reflect the real sampling distribution, while still using training-engine probabilities to define the trust region for the update.

Similarly, FlashRL proposes a truncated importance-sampling method called TIS, which reweights updates to correct the policy mismatch between quantized inference used for sampling and the full-precision model used for optimization. With that trick, even heavily quantized rollout data such as INT8 or FP8 can still be used for training without degrading the final outcome.
This is another good example of algorithm design being used to bridge the gap created by system design.
Emerging Trends: New Challenges and New Opportunities
After the mature examples, let us look at a few directions where the field clearly sees the problem, but the solution has not fully converged yet.
Direction 1: Agent RL, Sample Efficiency, Environment Management, and Process Rewards
As Agent RL develops, LLMs are no longer just generating text. They are becoming autonomous agents that call tools, invoke APIs, and interact with environments over long horizons. That introduces a new set of challenges.
From the current research trend, Agent RL seems to fall into two broad patterns:
- Sandbox + Browser: typically used for general-purpose agents, where the model is trained in controlled sandboxes or browser environments.
- MCP + Tool Use: more common in internal or vertical settings, where the model is trained to use a specific tool ecosystem.
Several core problems become much more visible in those settings.
1. Sparse and Delayed Rewards
In complex tasks, pure outcome rewards are extremely inefficient. Anthropic has mentioned that Claude Opus 4 can run for hours in the background on software-development tasks. If reward is only given at the very end, sample generation becomes painfully expensive and the delayed signal does little to guide learning.
That is why process-level rewards and other agent-guidance mechanisms may become important again.
Recent work such as Agent-RLVR adds teacher-like feedback to RL training, including high-level instructions and dynamic error correction, and significantly improves success rates on complex coding tasks.
This also connects to sample efficiency more broadly. We need both more efficient data-generation pipelines and better mechanisms for reusing high-quality data. Work such as Sample-efficient LLM Optimization with Reset Replay is already moving in that direction.
2. Complex State Representation and State Management
An agent’s state is no longer just dialogue history. It includes tool outputs, environment observations, and internal reasoning traces. Traditional RL frameworks are not good at modeling such high-dimensional, long-horizon, heterogeneous state spaces.
To address this, new research is exploring explicit memory modules and state-compression techniques. For example, AGILE shows that giving agents explicit memory and reflection mechanisms can improve long-horizon reasoning and cross-step consistency.
3. Environment Observability and Tool Reliability
Agent RL usually depends on many external tools and services, such as code interpreters and search APIs. But those components can fail, become slow, or return bad results. That makes the environment only partially observable and increases both training instability and debugging difficulty.
So observability, fault recovery, and tool-chain monitoring are likely to become key system-design challenges.
New RL Infrastructure
To handle the challenges above, RL infrastructure is moving toward stronger modularity and stronger scalability. In my view, future Agent RL frameworks need:
- a distributed training engine that supports fine-grained tracing and observability
- an inference engine that supports continuous partial rollouts, so trajectories can be generated, interrupted, and reused in stages
- more efficient offline RL and data-reuse mechanisms to reduce the cost of sampling high-quality trajectories
Only a new RL architecture that is simultaneously flexible, interpretable, and operationally robust will be able to support continuous learning in real-world environments.
Direction 2: Generative Reward Models and Further Disaggregation
Another notable trend in recent alignment research is the rise of generative reward models (GRMs), for example DeepSeek-GRM. Instead of outputting a scalar score like a traditional reward model, a GRM is itself a language model that can generate detailed evaluation text and reasoning traces. With enough test-time scaling, this can make reward evaluation much more robust.
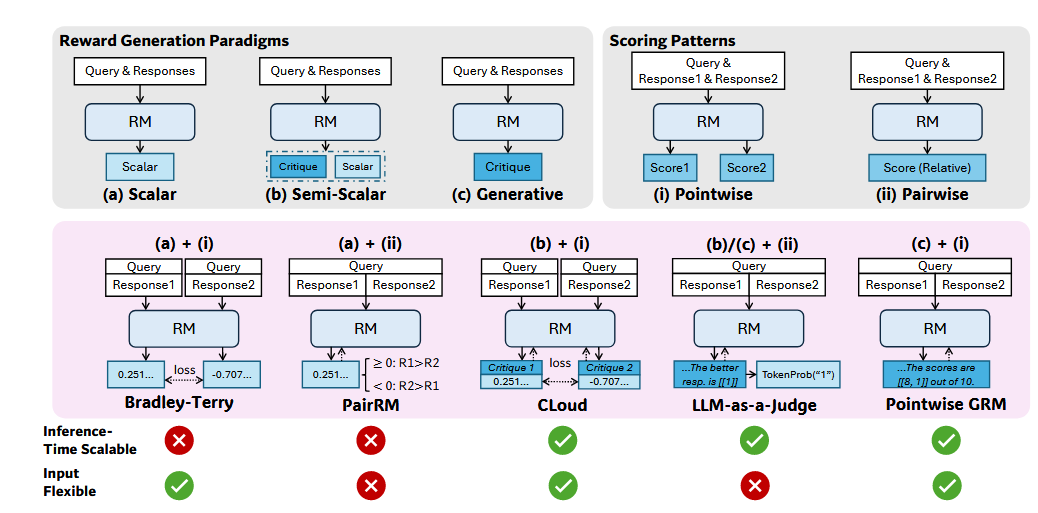
In some sense this direction is a continuation of an older point OpenAI already emphasized in Scaling Laws for Reward Model Overoptimization: reward models need scale too.
Just as o1 and R1 amplified the importance of disaggregated architectures, generative reward models will push RL pipelines toward even more distributed and multi-model designs. Instead of training around a single policy model, the framework now has to orchestrate a policy model, a value model, one or more reward models, and potentially more evaluator models, all interacting dynamically.
That raises the bar for resource management, task orchestration, and inter-model communication.
GRMs are therefore not just an algorithmic innovation. They are a system-level challenge to the entire RL infrastructure stack.
Closing Thoughts
The cases discussed here show a recurring pattern in LLM RL: algorithmic change and system change are not independent. They co-evolve because each side exposes the limits of the other.
The mature cases already taught us a lot. Asynchronous RL architecture emerged because reasoning workloads made synchronous rollout too wasteful. Decoupled PPO and related methods appeared because system-level train-infer mismatch became too large to ignore.
The newer trends point to even deeper coupling. Agent RL requires richer environment management and more powerful state handling. Generative reward models require the framework to manage several large models at once. In both cases, algorithmic progress depends on system capabilities, and system direction is shaped by algorithmic needs.
More broadly, this co-evolution is redefining what an RL system even is. Traditional single-machine design principles are no longer enough. We should expect to see more system-aware algorithms and more algorithm-optimized system architectures in the next wave of LLM RL.
Last modified on 2025-08-14