LLM reinforcement learning frameworks have been evolving extremely quickly. Ray was one of the frameworks that benefited the most from the ChatGPT wave, and among all stages of LLM training, RL is probably where Ray is used the most. I want to write down the development path of this area and a few of my own views.
Starting from Google Pathways
If we want to discuss Ray and RL systems, a good place to start is Pathways. In 2021 Google proposed Pathways as a next-generation AI architecture and distributed ML platform, and the related work discussed a Single-Controller + MPMD system design in detail.
Single-Controller means using one central coordinator to manage the entire distributed computation flow. There is a master control node responsible for task dispatching, resource scheduling, status monitoring, and orchestration of the whole graph.
Multiple-Controller means using several distributed control nodes that jointly manage different parts of the workload. There is no single global coordinator. Instead, different sub-systems are coordinated through a distributed consistency protocol.
In Ray, the Driver Process is a typical Single-Controller. It can launch and coordinate many different task programs. By contrast, a PyTorch DDP program started via torchrun is a typical Multiple-Controller setup, because each node is running its own copy of the program.
MPMD stands for Multiple Program, Multiple Data. Different nodes run different programs on different data shards within the same overall task.
SPMD stands for Single Program, Multiple Data. Every node runs the same program, though usually on different shards of the data.
Traditional distributed training such as PyTorch DDP is a classic SPMD workload. Each node runs the same code, with only small rank-based differences, such as rank = 0 being responsible for checkpointing. Large-model training, however, often includes more complicated stages such as pipeline parallelism, where different node groups run different logic. That is much closer to MPMD.
In general, MPMD systems contain many heterogeneous components, which makes coordination and synchronization complex. To reduce development complexity and keep execution semantics consistent, a Single-Controller architecture becomes the natural choice: a central controller manages task scheduling, state synchronization, and failure handling.
There are two old OneFlow articles about Pathways that are still very insightful if you want more background.
What does this have to do with LLM reinforcement learning? RL for LLMs is fundamentally a multi-stage, multi-node distributed workload. A typical RLHF pipeline involves several models and several distinct stages:
- Generation: the current policy model generates responses for a batch of prompts.
- Evaluation: the responses are scored by a reward model, or compared by a human or automated preference model.
- Training: the policy model is updated using the reward signal, often together with a value model or critic update.
These stages have explicit data dependencies. Training must wait for generated samples and their rewards. In a naive implementation the stages have to run serially, which introduces large context-switching costs and forces all participating models to use the same number of GPUs. That is highly inefficient. Inspired by Pathways, the goal is to overlap and parallelize these stages as much as possible while preserving correctness.
The following table from HybridFlow illustrates the contrast. I only kept the two earliest RLHF systems. On the left, DeepSpeed-Chat uses a serial SPMD design. On the right, OpenRLHF is a typical MPMD system.
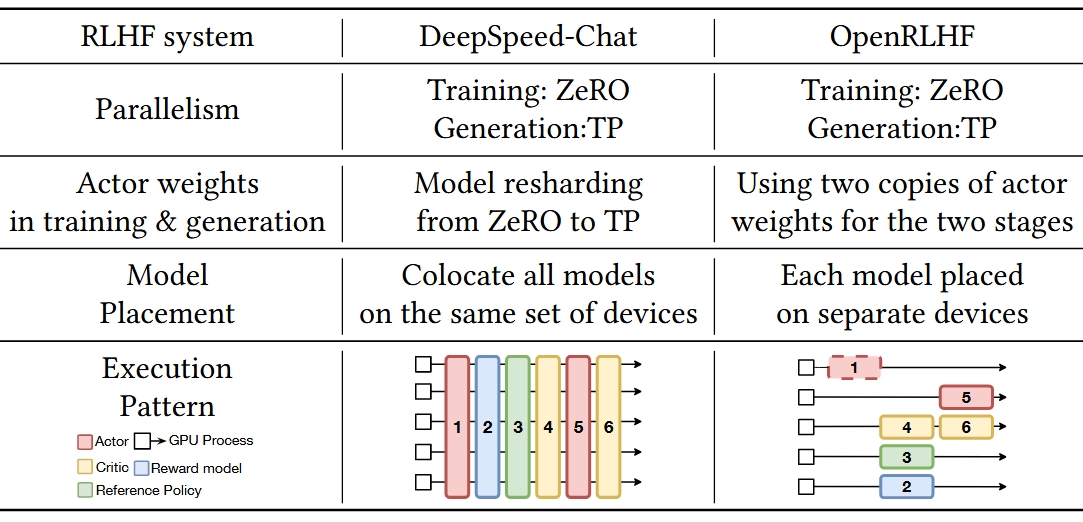
Ray and LLM RL Frameworks
From the discussion above, it should already be clear that Ray is a good fit for building Single-Controller + MPMD systems, so it is naturally well suited to LLM RL.
In practice the community has indeed built a large number of RL frameworks on top of Ray. Their designs broadly fall into two categories: colocated architectures and disaggregated architectures.
Roughly speaking:
- Colocated means the generation stage and the training stage run on the same nodes.
- Disaggregated means they run on different nodes.
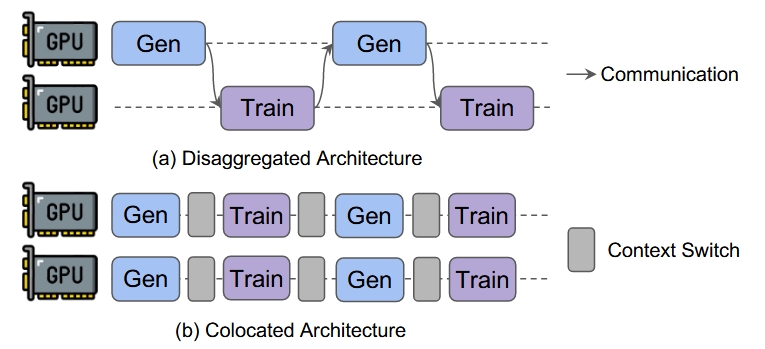
One thing immediately stands out in the diagram: the disaggregated architecture can suffer from large bubbles, and in some cases may even look worse than the older SPMD mode. That is why many frameworks such as OpenRLHF, Nemo-aligner, and VeRL were designed around the colocated approach.
It is worth noting that the figure’s Train and Gen stages are different RLHF phases. Inside each phase, different GPUs may still be running different roles, so the full system is still MPMD.
Take PPO as an example. The training stage usually contains four models: Actor, Reference, Reward, and Critic. The generation stage uses an Actor model inside an inference framework. In OpenRLHF, the picture looks like this:

The Actor moves back and forth between DeepSpeed and vLLM, because the full algorithm effectively has to manage five different model instances.
Colocated RL Frameworks: Benefits and Limits
OpenRLHF uses Ray to launch and coordinate components, but it relies on Ray Placement Groups to implement a colocated architecture. On each node, GPU resources are split between rollout workers and training workers. For example, one framework may assign 0.75 of each GPU to the training actor and 0.25 to the generation actor, letting both processes share the same device without fully stepping on each other.
The main advantage is resource sharing. With the right grouping strategy, we can reduce GPU idle time, reduce model offload frequency, and overlap the execution of different stages across nodes as much as possible.
However, colocated systems also show clear limitations as model sizes and cluster sizes grow.
The first major issue is what StreamRL calls resource coupling. Although colocated systems improve over plain SPMD by parallelizing more of the workflow and letting different model groups use different resources, they still cannot fully avoid the constraints of shared devices. Generation and training share the same GPUs, which means we cannot scale or tune resources for those two phases independently. Training is compute-bound while generation is often more IO-bound, so they do not have the same bottlenecks.
Another problem is that LLM output length is variable. With reasoning models becoming more important, the rollout time for different groups can vary wildly. Imagine 32 GPUs split into groups of 4 for generation. If one group gets a very long sample, the other 28 GPUs may end up waiting.
So colocated frameworks do achieve high GPU utilization through fine-grained resource management, and they are comparatively mature and stable. Many later frameworks borrowed similar designs. But the resource-coupling problem limits their scalability. That naturally leads to the next question: can generation and training be made truly independent and parallel?
On-Policy and Off-Policy
This article focuses on system design, so I will keep the algorithm section short.
- On-Policy: training must use data generated by the latest policy. In RLHF this means every iteration has to wait for the current actor to finish a fresh rollout before training can proceed. The upside is perfect policy-data consistency. The downside is the large synchronization bubbles described above.
- Off-Policy: training is allowed to use data generated by a slightly older policy. In practice that means the trainer can consume samples produced by earlier actor versions instead of waiting for the newest one to finish. This introduces policy staleness, but it also lets generation and training run in parallel.
The reason disaggregated architectures had so many bubbles in the original on-policy setting is exactly this requirement: training can only consume samples produced by the latest policy.
From a theoretical perspective, on-policy algorithms do have better sample efficiency because the data distribution matches the current policy exactly. In LLM RL, policy staleness introduces distribution shift. The rollout policy and the current training policy no longer match, which can hurt convergence stability and sample efficiency.
In industrial RL practice, however, that gap is often offset by the throughput gain. Modern LLM RL systems mitigate staleness with larger experience buffers, better sampling strategies, and more frequent model synchronization. In deployment, many teams have found that with proper hyperparameter tuning, such as learning-rate decay and gradient clipping, off-policy systems can remain stable while delivering much higher throughput. That engineering tradeoff is one reason the field has been moving from pure RLHF toward more iterative and more parallel-friendly variants.
Disaggregated Architectures: From Off-Policy to Streaming RL
Naturally, the industry began exploring off-policy LLM RL. ASYNCHRONOUS RLHF provided an encouraging result: a moderate amount of policy staleness is acceptable and does not significantly hurt training quality. StreamRL validated and extended this direction further.
Meta proposed a similar pipeline in LlamaRL, giving us a more streaming-style disaggregated architecture:
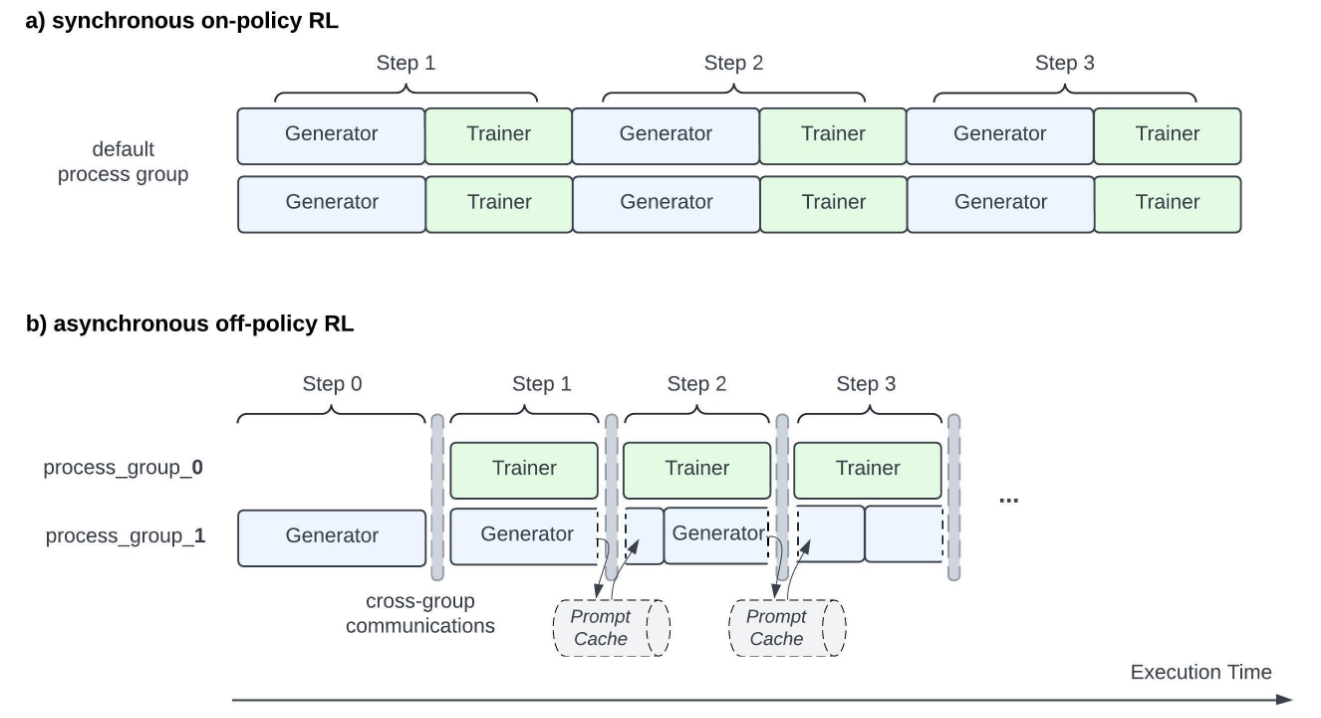
This points to a clear trend: the latest LLM RL systems are moving toward disaggregated architecture + off-policy designs, which fit naturally with the MPMD paradigm.
The idea is to separate generation and training into different services that run concurrently on different GPU pools. One GPU pool continuously generates fresh rollouts, while another pool continuously trains on incoming samples.
Compared with colocated systems, disaggregated systems make independent scaling of heterogeneous resources possible. If generation becomes the bottleneck, we can scale out the generation pool only. If reward-model evaluation or PPO updates become the bottleneck, we can instead scale the training side. That elasticity is especially valuable in cloud and multi-tenant environments.
By accepting a small amount of stale-policy data, streaming frameworks improve utilization dramatically. GPUs no longer have to stop in sync between iterations. Generation and training can both run at steady throughput. StreamRL explicitly addresses the pipeline bubbles and long-tail stragglers that plague synchronous systems. Weight updates, generation, and training are overlapped as much as possible.
To coordinate the training cluster and the inference cluster even better, it is natural to introduce a data buffer or queue as the interface between them. A good example is AsyncFlow, which uses a TransferQueue to move data and control training execution.
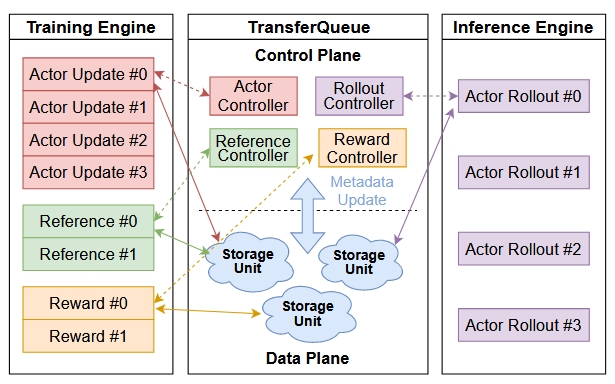
In short, streaming RL frameworks decouple the RL loop into independent components and use asynchronous execution to improve throughput. They solve the weaknesses of colocated systems by avoiding resource coupling and enabling more fine-grained scaling. The cost is higher system complexity and the need to deal with off-policy training, but with careful design, as in AsyncFlow and StreamRL, those issues are manageable.
RL Without Ray?
As LLM RL frameworks continue to evolve, a new trend has started to appear: dependence on Ray is gradually shrinking.
Ray was originally a great choice for fast prototyping. It made cluster configuration, process launch, remote function calls, and actor orchestration very easy. Early OpenRLHF, mid-stage VeRL, and newer systems such as Slime and AsyncFlow all used Ray as the glue that held the training loop together.
But once these systems reached large-scale production deployment, several Ray limitations started to show up.
Technical Challenges with Ray
- Debugging complexity is one of the biggest issues. When a deep exception happens inside a remote worker, you often receive a vague serialized error message rather than the real root cause.
- Communication overhead is another major bottleneck. Ray relies heavily on Python object serialization and gRPC. In RLHF that becomes expensive quickly. An experience batch may contain tens of thousands of generated tokens, full logits distributions, and a variety of reward and value outputs. Moving those payloads between the generation stage and the training stage can be costly.
The Ray community has been trying to address these issues with tools such as Ray Flow Insight, Compiled Graph, and GPU Objects, but those solutions are not yet fully mature.
The Buffer-Driven Trend Toward Ray-Free Architectures
Because of these issues, the community has started to discuss Ray-free designs more seriously. Meta’s LlamaRL is built entirely on native PyTorch and has been validated on a 405B model. Other frameworks have had similar discussions, including VeRL.
Is that realistic? If you think about the direction these systems are moving, the key abstraction in new streaming RL frameworks is the data buffer. It stores the current rollout set and exposes it to trainers. In essence, it is an experience queue or shared-memory interface. Generation workers continuously push new samples into the buffer, while training workers continuously pull from it. Once those phases are decoupled that far, a heavyweight orchestration layer may no longer be necessary.
That said, abandoning Ray is not free either. Many frameworks still keep it because it remains useful for cluster management, process launch, fault recovery, and resource scheduling. The HybridFlow team at ByteDance, for example, considered replacing Ray with TorchRPC and even got it working. But in real deployment they found that TorchRPC was not maintained aggressively enough and had various strange corner-case issues. With careful engineering a custom stack may deliver better performance, but Ray still saves a lot of development and maintenance effort when you need a stable distributed application.
Another issue is scale. As post-training compute budgets keep growing, Ray’s role may shift from pure control-flow orchestration toward fault tolerance and dynamic resource management. RL is far more flexible than pretraining, and we already have examples where Ray helped improve training stability even in pretraining. That role may become even more important in RL, though admittedly only the largest companies can really push that frontier.
Closing Thoughts
The evolution of LLM RL frameworks over the past year shows a very classic distributed-systems tradeoff.
Early colocated architectures achieved good GPU utilization through resource sharing, but as model sizes and cluster sizes increased, resource coupling became harder to ignore. The emergence of streaming RL marks a fundamental shift in design philosophy: through joint algorithm-system design, the field is moving from on-policy to off-policy training, accepting a limited amount of policy staleness in exchange for better scalability and utilization.
Ray played a critical role as the infrastructure for this generation of frameworks, especially for fast prototyping and cluster management. But as systems became more complex and performance requirements rose, its limitations around debugging and communication overhead also became harder to ignore. That in turn pushed the community toward more specialized solutions, including native PyTorch implementations and hybrid architectures.
Looking forward, LLM RL frameworks will likely continue moving toward finer-grained decoupling and more specialized components. Core compute paths will rely more heavily on highly optimized native implementations, while cluster management and fault tolerance may still be delegated to mature distributed systems. That layered design is a reasonable way to preserve both performance and maintainability.
Last modified on 2025-07-27