The previous two articles in this series focused on the theory and kernel-level engineering of linear attention. But those discussions were mostly centered on the development environment. In real large-scale deployment, we need many additional optimizations in order to make better use of hardware resources. In this article, I want to discuss linear attention from the perspective of deployment-oriented optimizations, and explain why I believe the infrastructure around linear attention is still in a very early stage.
Quantization
LLM.int8() and Massive Activations
Even before ChatGPT exploded in popularity, some research had already studied the difficulties that full attention architectures face during quantization. In LLM.int8(), the authors point out that some outlier activation values inside full attention can significantly hurt quantization quality, and therefore suggest separating those outliers from the normal values.
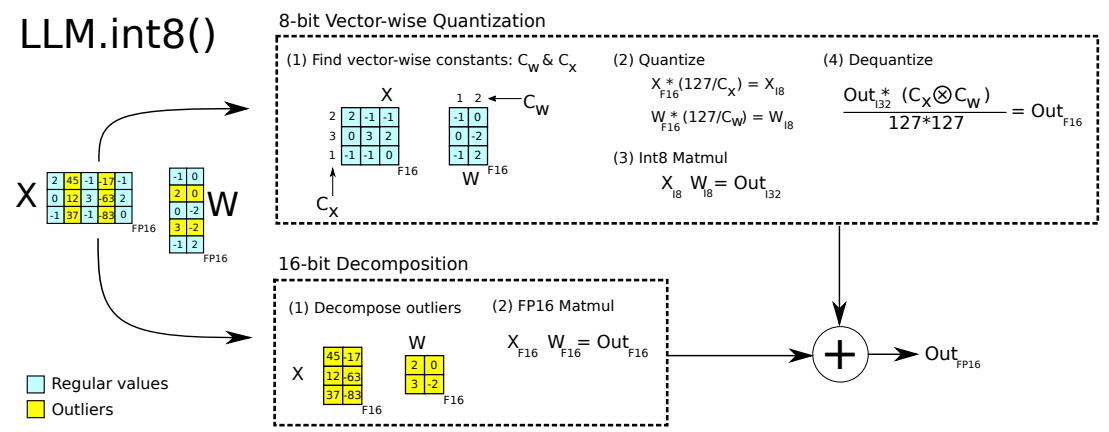
This phenomenon is often called Massive Activations. It has been studied extensively, and two major contributing factors are Softmax and RoPE.
Softmax normalization: Softmax enforces the constraint that all attention weights must sum to 1. But in real LLM computation, we often want more flexible behavior. For example, if an input is simple enough that the first 40 layers of a 60-layer model have already done the useful work, then the remaining layers might ideally perform a near no-op, which in a residual network corresponds more closely to outputting 0. To satisfy such requirements, attention may develop behaviors similar to Attention Sink, concentrating attention on irrelevant tokens and producing massive activations.
RoPE positional encoding: The paper Massive Values in Self-Attention Modules are the Key to Contextual Knowledge Understanding points out that RoPE applies rotations with frequency-dependent angles on the Query/Key channel dimensions. This transformation depends on relative position, and in some projected dimensions it can substantially amplify or shrink values, causing clusters of dimensions to concentrate and produce spike-like outliers. The paper also finds experimentally that models using RoPE, such as LLaMA, Qwen, Gemma, and Falcon, all exhibit this massive-values stripe phenomenon, while models without RoPE, such as GPT-2, OPT, and Jamba, do not.
Quantizing Linear Attention
Without Softmax and RoPE, linear attention avoids some of the issues above, and the problem is greatly alleviated. For example, A Unified View of Attention and Residual Sinks reports that replacing full attention with linear attention reduces the peak hidden-state activation from 6000 to 510, which appears to make the problem substantially easier.
But that does not mean the problem has disappeared. Different linear attention architectures still have different quantization challenges:
- State accumulation: the recurrent nature of linear attention causes numerical error or certain patterns to accumulate over time. For example, PScan in Mamba can suffer from length-induced numerical degradation on very long sequences.
- Gating amplification: architectures such as GLA and Mamba rely heavily on gating mechanisms, and the gate weights often show a sparse-and-extreme bilateral distribution, widening the value range across channels.
As a result, some quantization methods designed for full attention, such as LLM.int8(), can transfer to linear attention reasonably well, while others, such as SmoothQuant, are much harder to apply directly. We will likely need architecture-aware quantization strategies tailored to different linear attention designs.
That said, among the three deployment topics discussed below, quantization is actually the most mature one for linear attention so far.
Prefix Cache
Even if quantization is not strictly required in LLM deployment, Prefix Cache certainly is. Reusing previous computation results, that is, the KV Cache, is almost unavoidable at scale. In multi-turn dialogue or shared system prompt scenarios, it can significantly reduce TTFT and improve system throughput.
However, linear attention cannot integrate Prefix Cache in a seamless way.
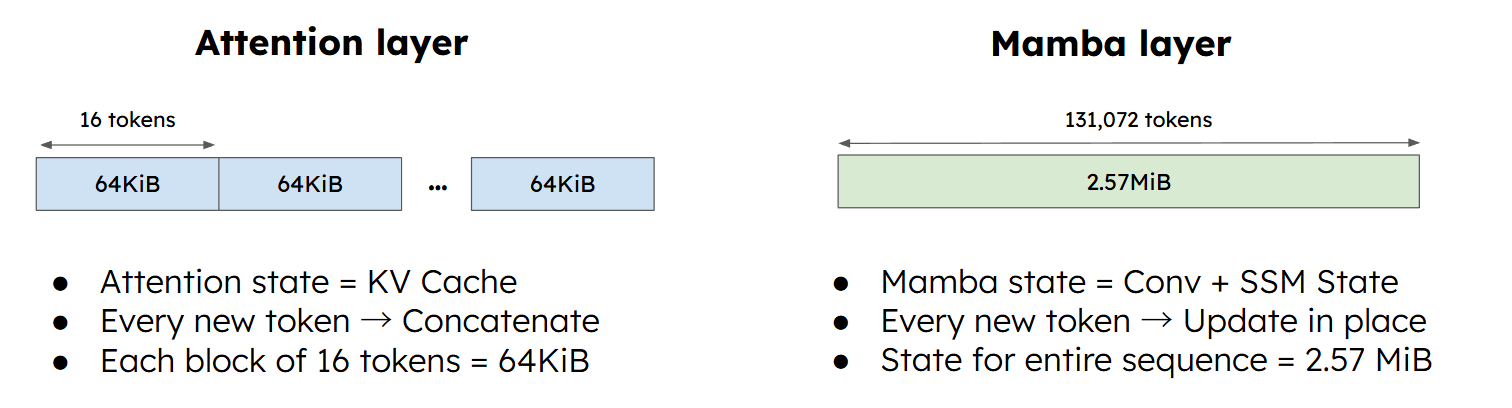
- In-place updates: the key advantage of linear attention is that it compresses all historical information into a fixed-size state matrix $h_t$. That means we no longer keep the full token-level history, as in a standard KV Cache. Instead, we keep only the latest state, updated in place.
- High storage cost: in full attention, Prefix Cache only needs to store token-wise KV blocks, and the per-token state is small, for example around 4 KB. In linear attention, the state is often much larger, for example around 2 MB. If we save it at high frequency like full attention does, VRAM is exhausted very quickly.
vLLM: Automatic Prefix Caching (APC)
To address this, the vLLM community, see #issues/26201, has been pushing APC support for hybrid models. The core idea is to compromise between granularity and storage cost, and reduce the save frequency by using a larger chunk or block size.
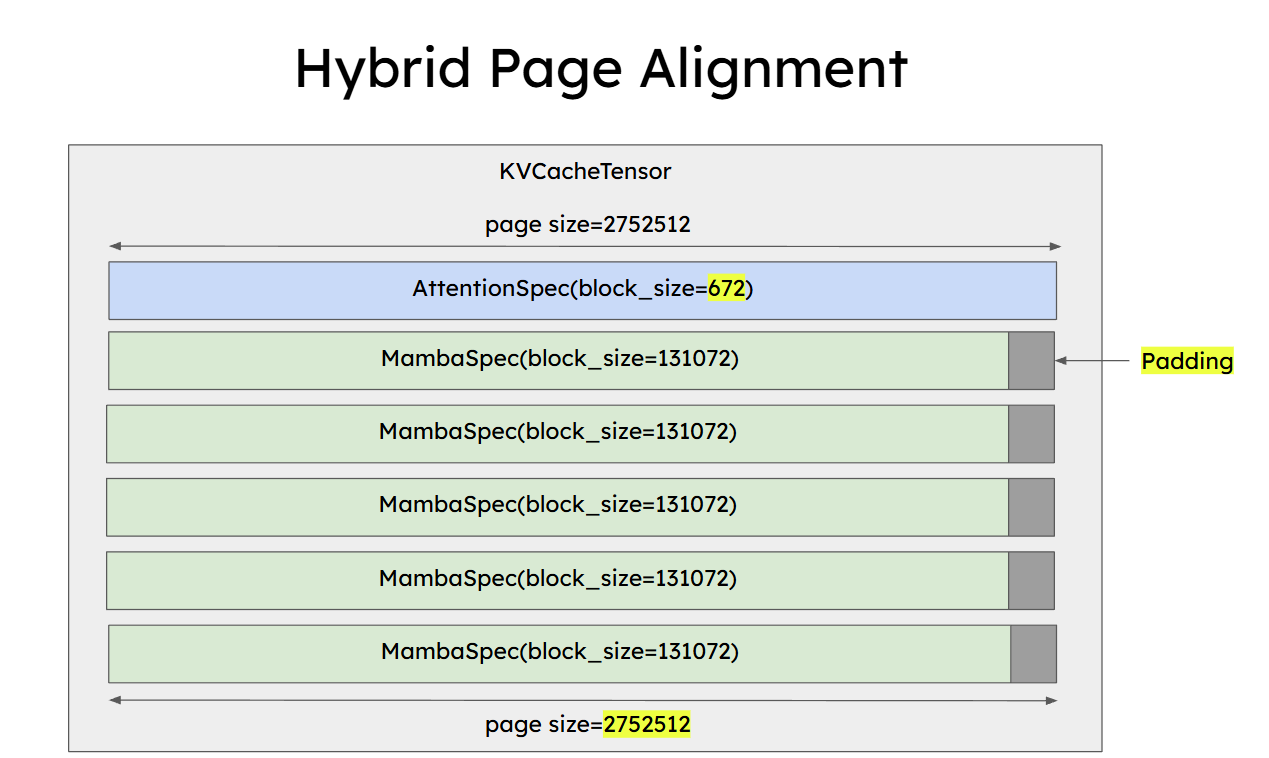
Unified Block Management
For hybrid architectures, vLLM uses a unified Block Manager. This means the system enforces a common block size, for example 512, to manage both the linear-layer state and the attention-layer KV blocks.
Checkpoints (State Cache)
To make caching possible, vLLM requires both the linear attention kernel and the runtime to give up the old approach of keeping only one final state. Instead, it introduces checkpoints, storing state at a coarser granularity than full attention.
Prefill kernel changes: previously, the Prefill kernel would process all tokens at once and emit only the final state. To support APC, the kernel is modified to emit and save the current state every chunk_size tokens. In fact, if you recall the engineering article, this matches the structure of the earlier CUDA kernel design surprisingly well.
Overall, because the state is large, often 2 MB or more, hybrid attention systems usually need a block size in the hundreds or even thousands. That makes cache hit rates lower than in standard full attention, but it can still deliver large benefits in long-context dialogue workloads.
Speculative Decoding
Although it is not as fundamental as Prefix Cache, speculative decoding remains one of the most effective ways to reduce TPOT in real deployments.
Why Linear Attention Struggles Here
Linear attention still has a large support gap for speculative decoding. Recall the engineering article: linear attention depends on two major classes of kernels:
- Parallel / chunk-wise kernels (Prefill): these have high parallelism and are well suited for long sequences such as $L=8192$. But for the short sequences typical in speculative decoding, for example $K=5$, they cannot utilize the GPU well and the kernel launch overhead becomes dominant.
- Recurrent / RNN kernels (Decoding): these are serial and depend on the previous state $h_{t-1}$. If we use them to verify $K$ proposed tokens, we must run the kernel serially $K$ times. There is no real parallel verification speedup.
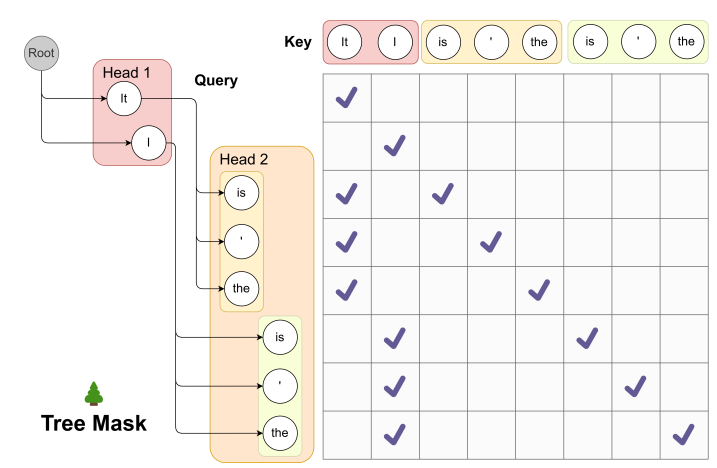
More importantly, modern speculative decoding often includes tree structures, as in Medusa or Eagle. In standard full attention, this is easy to support by modifying the attention mask. But linear attention has no mask mechanism in that sense. Its computation is driven by recurrent state updates, which makes it hard to evaluate tree branches in parallel.
Some Early Exploration
At the moment, research from both academia and industry is still at a very early stage. Work such as When Linear Attention Meets Autoregressive Decoding proposes some task-specific verification ideas, but the open-source implementation is just a very simple PyTorch script and does not seem to have gone through serious validation.
To make speculative decoding with linear attention practical in production, we would need far more efficient CUDA kernels:
- Small-chunk kernels: we need specialized parallel kernels for tiny batches such as $K = 5 \sim 10$, and they must support shared-state tree-style inference so that kernel launch overhead is minimized and compute density stays high.
- State rollback: because the core running state of linear attention is updated in place, rolling it back cheaply after speculative rejection is a difficult engineering problem, and may need to be combined with checkpointing.
If we look back at the current Triton-based Flash Linear Attention implementations, this still feels quite far away.
In short, compared with quantization and Prefix Cache, speculative decoding for linear attention has not yet received enough attention. Hopefully we will see more real progress in 2026.
Last modified on 2026-02-10