At the end of March I put together a PPT about the classic Paged Attention algorithm. That reminded me that I had not written a blog post in years, so I turned the slides into an article just to prove that I am still alive.

Paged Attention in vLLM
Before we begin, it is worth clarifying that vLLM has gone through several different implementations of the Paged Attention kernel:
Early vLLM versions:
- Prefilling ->
flash_attn_varlen_funcfrom Flash Attention - Decoding -> vLLM’s own Paged Attention implementation
paged_attention_v1: used for relatively short sequencespaged_attention_v2: used in the cases where you would rather not use v1 :)
The source code looks roughly like this:
# NOTE(woosuk): We use a simple heuristic to decide whether to use
# PagedAttention V1 or V2. If the number of partitions is 1, we use
# V1 to avoid the overhead of reduction. Also, if the number of
# sequences or heads is large, we use V1 since there is enough work
# to parallelize.
# TODO(woosuk): Tune this heuristic.
# For context len > 8192, use V2 kernel to avoid shared memory
# shortage.
use_v1 = (max_seq_len <= 8192 and (max_num_partitions == 1 or num_seqs * num_heads > 512))
In the latest vLLM versions, everything has moved to Flash Attention and is implemented with CUTLASS.
NVIDIA GPU Basics
Before diving into the Paged Attention implementation, we need a quick refresher on NVIDIA GPU architecture. I will focus on the A100 here.
From the CUDA programming model, a GPU program has three levels:
- Grid -> Thread Block -> Threads
These correspond to the hardware hierarchy:
- GPU -> SM -> CUDA Cores
At execution time, threads run in groups of 32, so in practice there is one more layer: the warp. That gives us:
- CUDA program: Grid -> Thread Block -> Warp -> Threads
- GPU hardware: GPU -> SM (multiple rounds) -> SM (single issue round) -> CUDA Cores
On an A100 we have:
- 108 SMs
- 4 warp schedulers per SM
- At most 4 warps can execute on one SM at the same time
- Each warp scheduler has a queue of length 16
- So one SM can schedule up to 64 warps
All of these numbers matter when designing kernels, because they directly affect how well we can utilize the hardware.
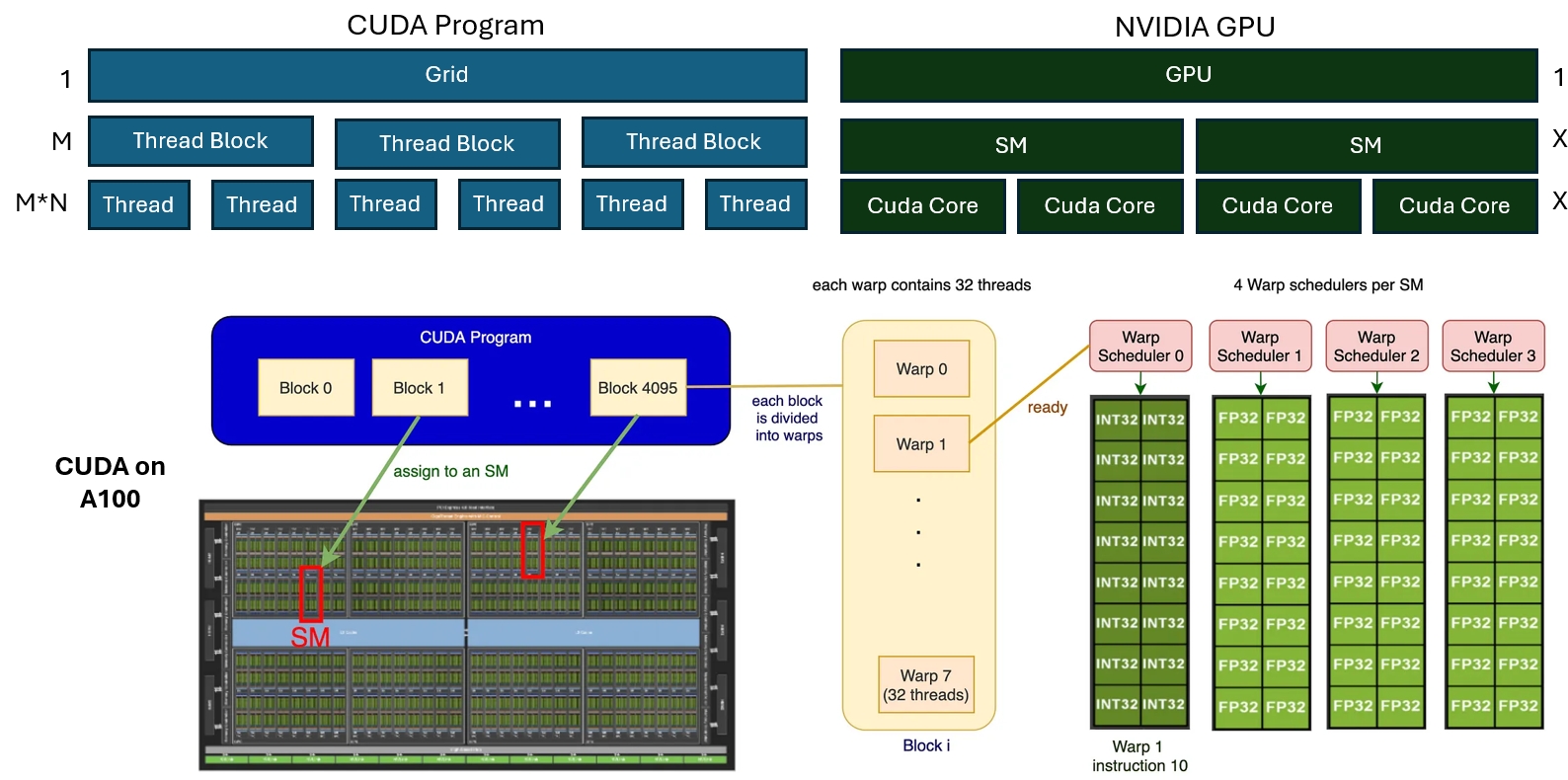
How the vLLM Kernel Maps to the GPU
Now let us look at the vLLM kernel design. For simplicity, assume there is no tensor parallelism.
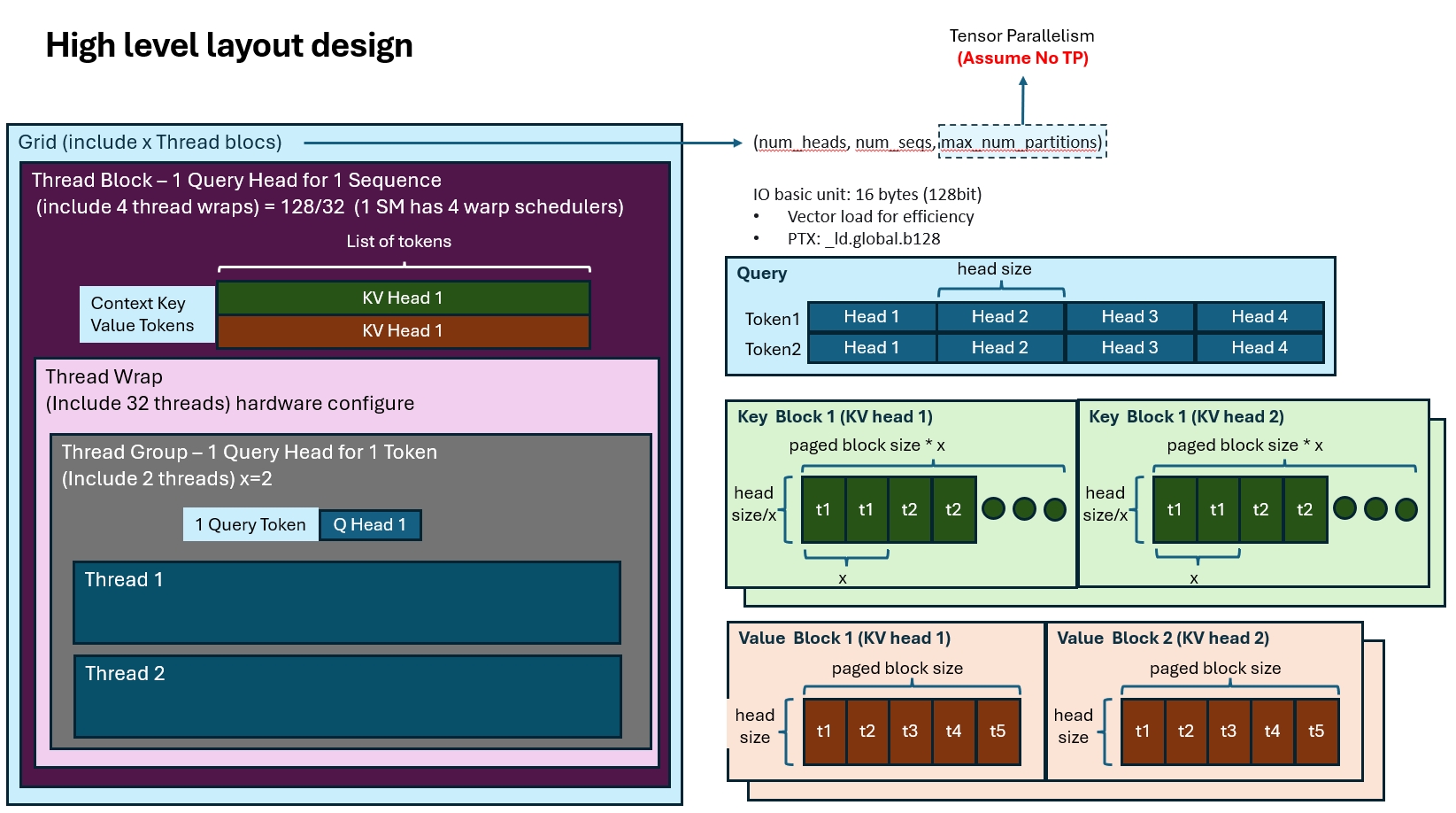
The first step in kernel design is to split the computation across thread blocks. In vLLM, each thread block computes one query head for one query token.
This design is fairly rough, but that is fine. Flash Attention applies much more aggressive optimizations later.
Once the computation granularity is fixed, the next step is memory layout. vLLM uses different layouts for Q, K, and V. From the code:
const scalar_t* __restrict__ q, // [num_seqs, num_heads, head_size]
const cache_t* __restrict__ k_cache, // [num_blocks, num_kv_heads,
// head_size/x, block_size, x]
const cache_t* __restrict__ v_cache, // [num_blocks, num_kv_heads,
// head_size, block_size]
When we design a memory layout, we usually care about two things:
- Reading contiguous memory blocks, ideally with vectorized loads such as
_ld.global.b128, which loads 128 bits or 16 bytes at a time. - Reducing access conflicts across threads.
The QKV layouts in vLLM are designed around exactly those considerations:
- Q uses the simplest layout: sequence length -> number of heads -> head dimension.
- K is more complex. Beyond
num_blocksandnum_kv_heads, which naturally describe the KV cache blocks, it introduces an extra parameterxinstead of storing data continuously alonghead_size. This exists to improve key-loading efficiency, which we will discuss shortly. - V is more straightforward than K and does not need that extra
xdimension.
The related launch configuration is:
// We want one warp to process one KV cache block at a time. Here block_size
// is usually 4, 8, or 16.
// Since warp_size = 32 is larger than cache block size, we can assign several
// threads to one token to accelerate the computation.
// With one warp handling one cache block, we can derive how many threads are
// assigned to each token. This is the thread group size.
[[maybe_unused]] int thread_group_size = MAX(WARP_SIZE / BLOCK_SIZE, 1);
assert(head_size % thread_group_size == 0);
...
// NUM_THREADS is 128, which gives 4 warps. That also lines up nicely with
// the 4 warp schedulers on one A100 SM.
constexpr int NUM_WARPS = NUM_THREADS / WARP_SIZE;
...
// A thread block uses 128 threads to process one token head.
dim3 grid(num_heads, num_seqs, 1);
dim3 block(NUM_THREADS);
With thread groups added, the CUDA hierarchy becomes more complicated:
- CUDA program: Grid -> Thread Block -> Warp -> Thread Group -> Threads
Query Access Pattern
After all that setup, we can finally get to the actual computation. The figure below illustrates how the query token is loaded.
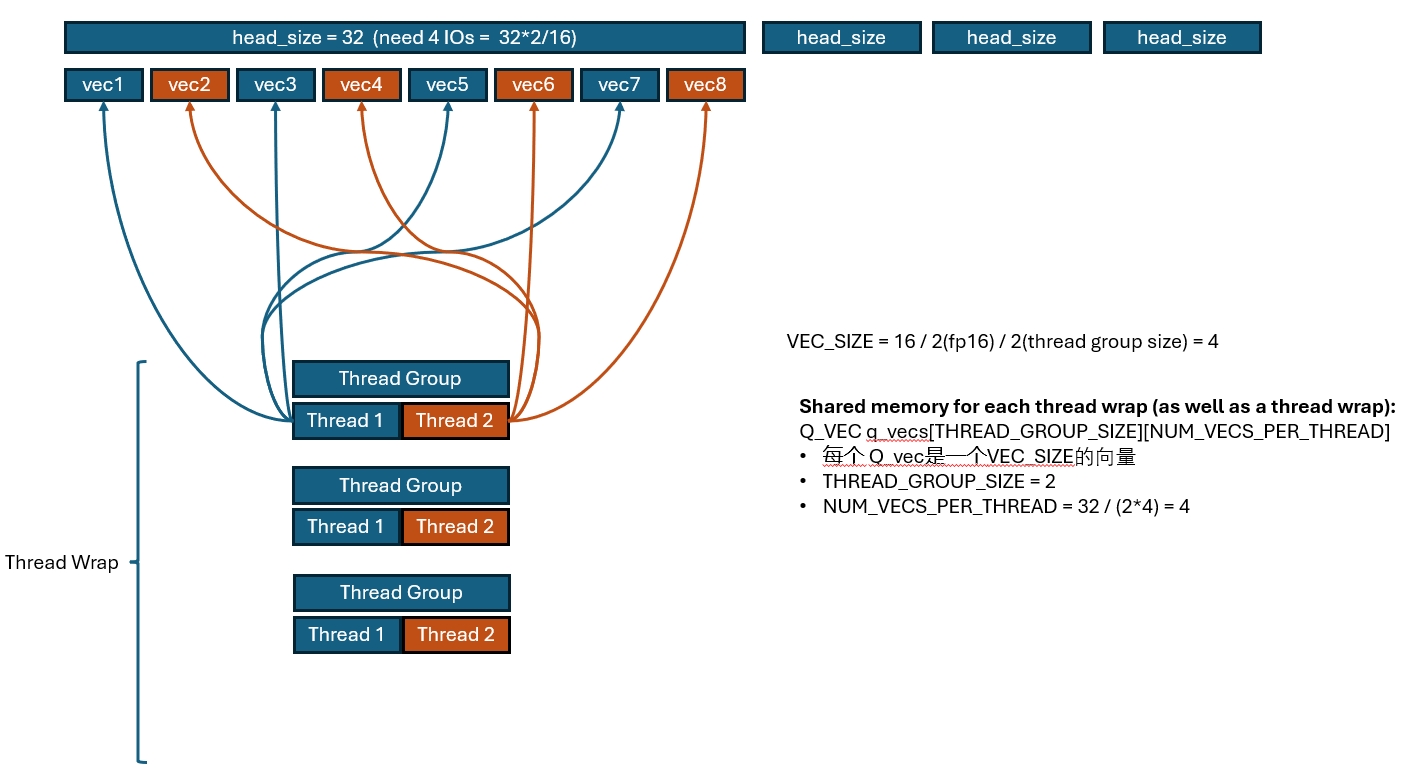
constexpr int VEC_SIZE = MAX(16 / (THREAD_GROUP_SIZE * sizeof(scalar_t)), 1);
constexpr int NUM_ELEMS_PER_THREAD = HEAD_SIZE / THREAD_GROUP_SIZE;
constexpr int NUM_VECS_PER_THREAD = NUM_ELEMS_PER_THREAD / VEC_SIZE;
const scalar_t* q_ptr = q + seq_idx * q_stride + head_idx * HEAD_SIZE;
__shared__ Q_vec q_vecs[THREAD_GROUP_SIZE][NUM_VECS_PER_THREAD];
#pragma unroll
for (int i = thread_group_idx; i < NUM_VECS_PER_THREAD;
i += NUM_THREAD_GROUPS) {
const int vec_idx = thread_group_offset + i * THREAD_GROUP_SIZE;
q_vecs[thread_group_offset][i] =
*reinterpret_cast<const Q_vec*>(q_ptr + vec_idx * VEC_SIZE);
}
The core idea is straightforward:
- One block is dedicated to one token head, so the query vectors can be staged into shared memory for reuse.
VEC_SIZEdetermines how many elements each thread should load if we want each thread group to collectively issue one 16-byte vector load.- Once we know
VEC_SIZE, we can derive how many vectors each thread has to read and which exact slice of data each thread is responsible for.
Each thread loads at vector granularity, while each thread group loads 16 bytes at a time. That gives us vectorized global memory reads and better IO efficiency.
In practice, many thread groups would otherwise load duplicate data. Once one group finishes loading, the others can directly reuse the shared-memory copy.
Key Cache Access Pattern
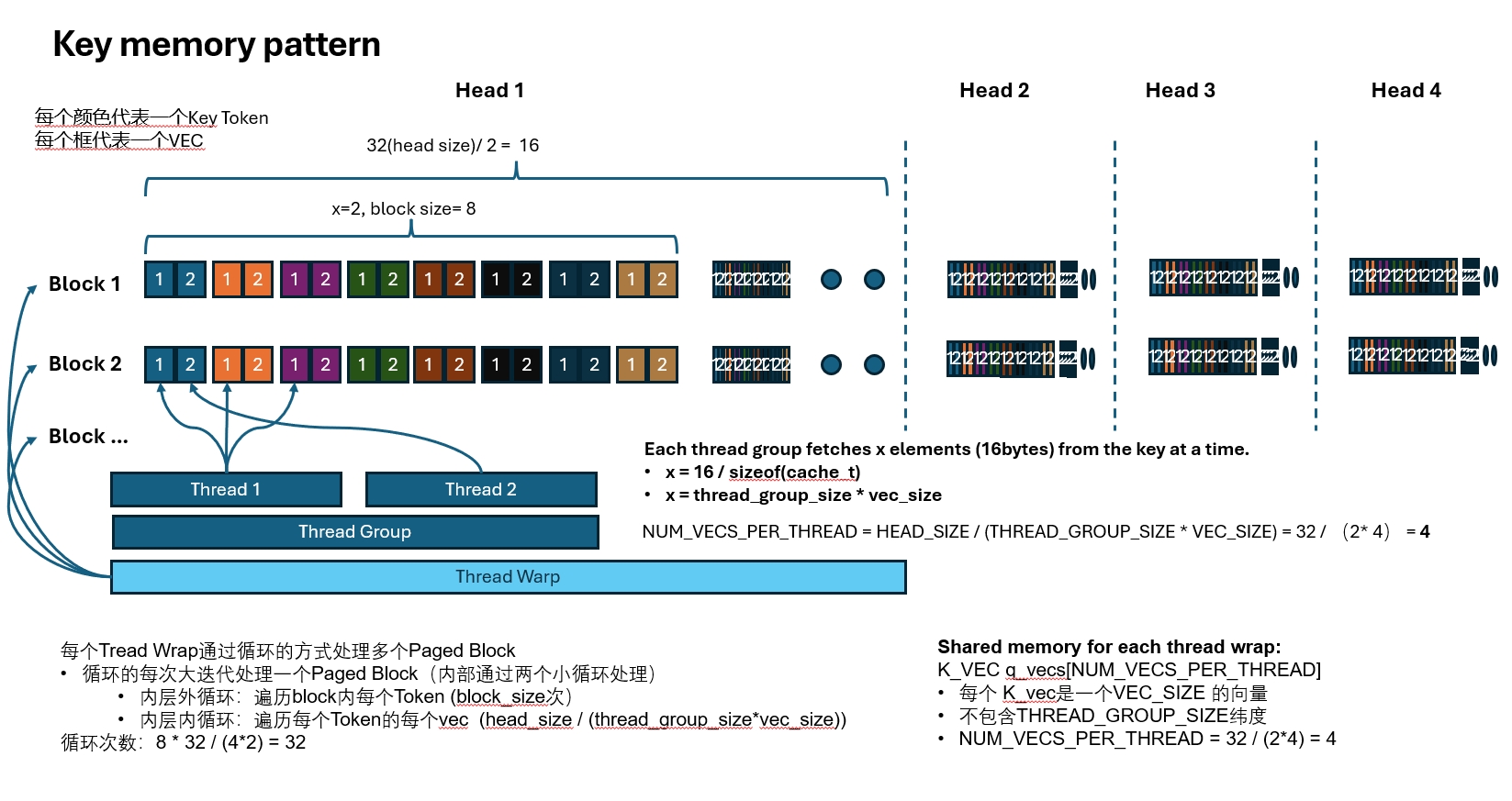
Just like queries, keys are also accessed at vector granularity so that each load pulls in 16 bytes. That is why K has the extra x dimension in its innermost layout.
If every x elements occupy 16 bytes, then each thread can naturally read one 16-byte chunk at a time.
Because we need the product between the current query token and all key tokens, the kernel walks through the KV cache one block at a time. Conceptually the loading process is a three-level loop:
- Each warp iterates over multiple paged blocks.
- In each outer iteration, one paged block is processed.
- Inside the block:
- one loop walks through every token in the block
- the innermost loop walks through every vector of that token
As with Q, once one warp finishes loading data, the rest of the thread block can reuse the result.
The relevant code looks like this:
// Outer loop: 4 warps iterate over all paged blocks.
// Each iteration: one warp handles one paged block.
for (int block_idx = start_block_idx + warp_idx; block_idx < end_block_idx;
block_idx += NUM_WARPS) {
...
// Load a key to registers.
// Each thread in a thread group has a different part of the key.
for (int i = 0; i < NUM_TOKENS_PER_THREAD_GROUP; i++) {
const int physical_block_offset =
(thread_group_idx + i * WARP_SIZE) % BLOCK_SIZE;
const int token_idx = block_idx * BLOCK_SIZE + physical_block_offset;
K_vec k_vecs[NUM_VECS_PER_THREAD];
#pragma unroll
for (int j = 0; j < NUM_VECS_PER_THREAD; j++) {
const cache_t* k_ptr =
k_cache + physical_block_number * kv_block_stride +
kv_head_idx * kv_head_stride + physical_block_offset * x;
const int vec_idx = thread_group_offset + j * THREAD_GROUP_SIZE;
const int offset1 = (vec_idx * VEC_SIZE) / x;
const int offset2 = (vec_idx * VEC_SIZE) % x;
if constexpr (KV_DTYPE == Fp8KVCacheDataType::kAuto) {
k_vecs[j] = *reinterpret_cast<const K_vec*>(
k_ptr + offset1 * BLOCK_SIZE * x + offset2);
} else {
Quant_vec k_vec_quant = *reinterpret_cast<const Quant_vec*>(
k_ptr + offset1 * BLOCK_SIZE * x + offset2);
k_vecs[j] = fp8::scaled_convert<K_vec, Quant_vec, KV_DTYPE>(
k_vec_quant, *k_scale);
}
}
// Compute dot product.
....
}
QK Computation
Once Q and K are loaded, the next step is the matrix multiply.
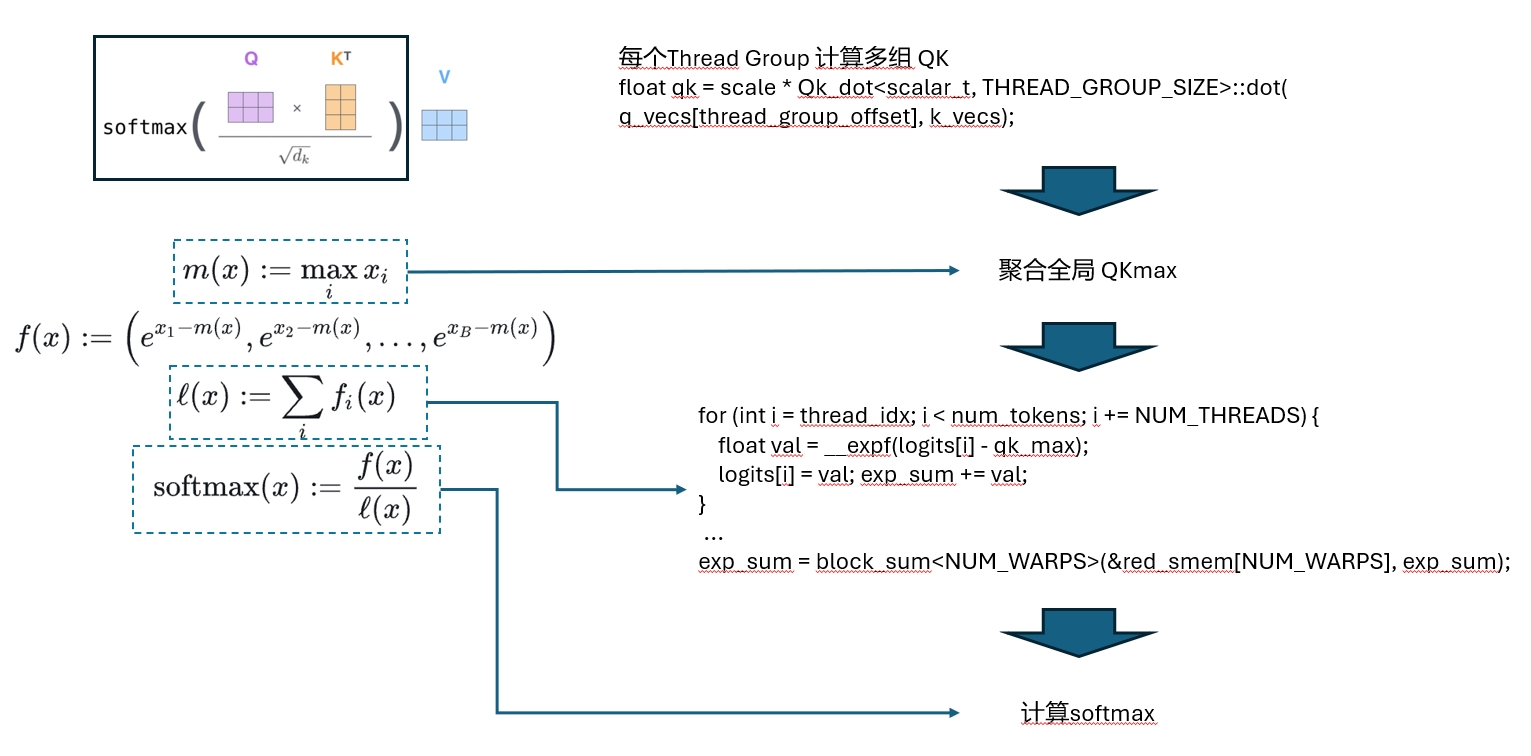
The basic logic is the omitted part of the code above:
// Compute dot product.
// This includes a reduction across the threads in the same thread group.
float qk = scale * Qk_dot<scalar_t, THREAD_GROUP_SIZE>::dot(
q_vecs[thread_group_offset], k_vecs);
// Add the ALiBi bias if slopes are given.
qk += (alibi_slope != 0) ? alibi_slope * (token_idx - seq_len + 1) : 0;
if (thread_group_offset == 0) {
// Store the partial reductions to shared memory.
// NOTE(woosuk): It is required to zero out the masked logits.
const bool mask = token_idx >= seq_len;
logits[token_idx - start_token_idx] = mask ? 0.f : qk;
// Update the max value.
qk_max = mask ? qk_max : fmaxf(qk_max, qk);
}
}
After that, the partial results must be reduced, because the QK products are distributed across multiple threads and we need the whole thread block to cooperate before we can compute the final softmax. This uses the classic two-stage reduction pattern:
// Reduction inside one warp.
#pragma unroll
for (int mask = WARP_SIZE / 2; mask >= THREAD_GROUP_SIZE; mask /= 2) {
qk_max = fmaxf(qk_max, VLLM_SHFL_XOR_SYNC(qk_max, mask));
}
if (lane == 0) {
red_smem[warp_idx] = qk_max;
}
__syncthreads();
// Reduction across the thread block.
Then the kernel computes softmax:
// Get the max qk value for the sequence.
qk_max = lane < NUM_WARPS ? red_smem[lane] : -FLT_MAX;
#pragma unroll
for (int mask = NUM_WARPS / 2; mask >= 1; mask /= 2) {
qk_max = fmaxf(qk_max, VLLM_SHFL_XOR_SYNC(qk_max, mask));
}
qk_max = VLLM_SHFL_SYNC(qk_max, 0);
float exp_sum = 0.f;
for (int i = thread_idx; i < num_tokens; i += NUM_THREADS) {
float val = __expf(logits[i] - qk_max);
logits[i] = val;
exp_sum += val;
}
exp_sum = block_sum<NUM_WARPS>(&red_smem[NUM_WARPS], exp_sum);
const float inv_sum = __fdividef(1.f, exp_sum + 1e-6f);
for (int i = thread_idx; i < num_tokens; i += NUM_THREADS) {
logits[i] *= inv_sum;
}
__syncthreads();
At that point, softmax is done. The only thing left is to multiply by the V cache.
Value Access and Attention Output
The V side is much more direct. All threads simply work together to read the value cache.
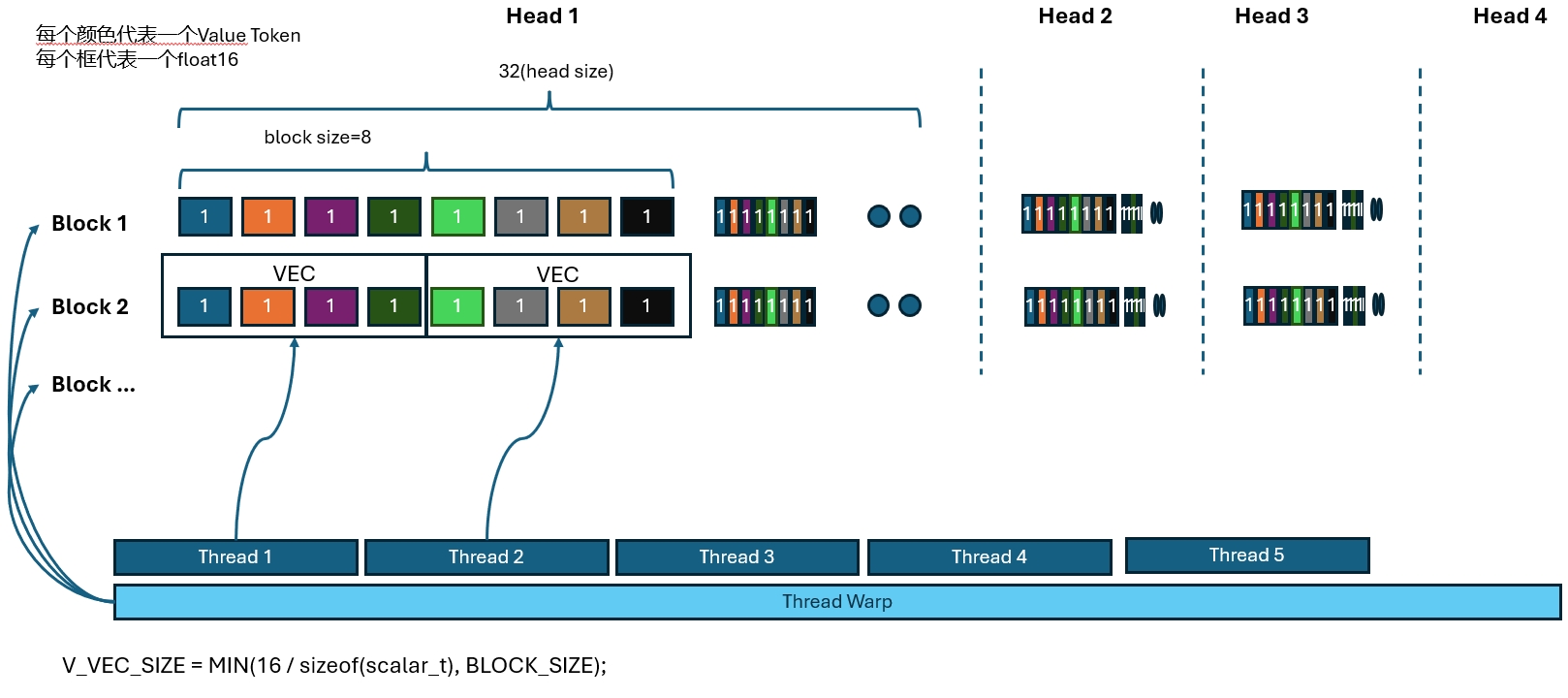
And the attention accumulation happens while reading:
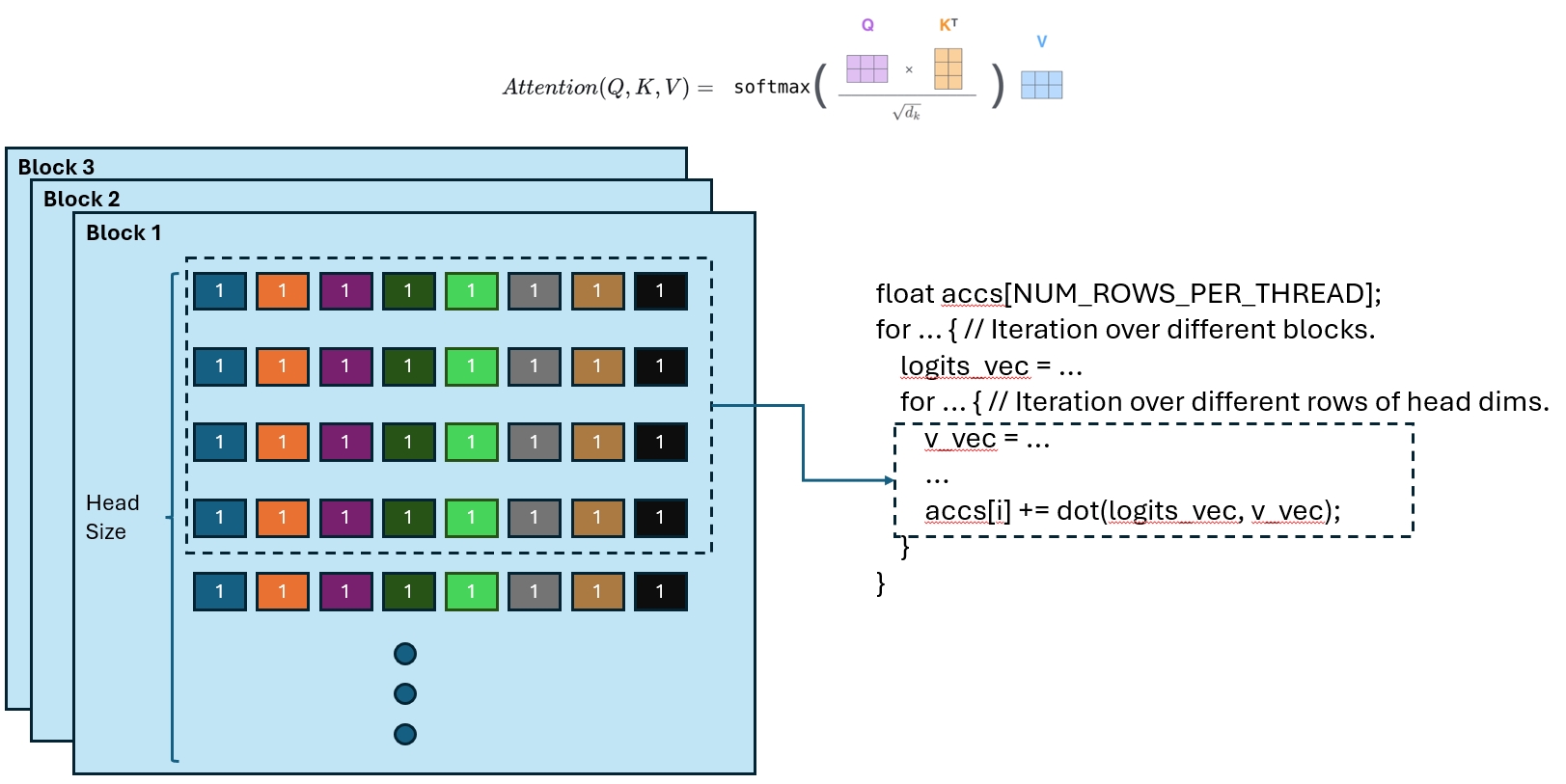
The kernel iterates block by block. In each block it reads a slice of every token’s value vector, accumulates partial results per thread, and then reduces them.
for (int block_idx = start_block_idx + warp_idx; block_idx < end_block_idx;
block_idx += NUM_WARPS) {
const int64_t physical_block_number =
static_cast<int64_t>(block_table[block_idx]);
const int physical_block_offset = (lane % NUM_V_VECS_PER_ROW) * V_VEC_SIZE;
const int token_idx = block_idx * BLOCK_SIZE + physical_block_offset;
L_vec logits_vec;
from_float(logits_vec, *reinterpret_cast<Float_L_vec*>(logits + token_idx -
start_token_idx));
const cache_t* v_ptr = v_cache + physical_block_number * kv_block_stride +
kv_head_idx * kv_head_stride;
#pragma unroll
for (int i = 0; i < NUM_ROWS_PER_THREAD; i++) {
const int row_idx = lane / NUM_V_VECS_PER_ROW + i * NUM_ROWS_PER_ITER;
if (row_idx < HEAD_SIZE) {
const int offset = row_idx * BLOCK_SIZE + physical_block_offset;
V_vec v_vec;
if constexpr (KV_DTYPE == Fp8KVCacheDataType::kAuto) {
v_vec = *reinterpret_cast<const V_vec*>(v_ptr + offset);
} else {
V_quant_vec v_quant_vec =
*reinterpret_cast<const V_quant_vec*>(v_ptr + offset);
v_vec = fp8::scaled_convert<V_vec, V_quant_vec, KV_DTYPE>(v_quant_vec,
*v_scale);
}
if (block_idx == num_seq_blocks - 1) {
scalar_t* v_vec_ptr = reinterpret_cast<scalar_t*>(&v_vec);
#pragma unroll
for (int j = 0; j < V_VEC_SIZE; j++) {
v_vec_ptr[j] = token_idx + j < seq_len ? v_vec_ptr[j] : zero_value;
}
}
accs[i] += dot(logits_vec, v_vec);
}
}
}
The accumulated results then go through another classic reduction:
#pragma unroll
for (int i = 0; i < NUM_ROWS_PER_THREAD; i++) {
float acc = accs[i];
#pragma unroll
for (int mask = NUM_V_VECS_PER_ROW / 2; mask >= 1; mask /= 2) {
acc += VLLM_SHFL_XOR_SYNC(acc, mask);
}
accs[i] = acc;
}
__syncthreads();
float* out_smem = reinterpret_cast<float*>(shared_mem);
#pragma unroll
for (int i = NUM_WARPS; i > 1; i /= 2) {
int mid = i / 2;
if (warp_idx >= mid && warp_idx < i) {
float* dst = &out_smem[(warp_idx - mid) * HEAD_SIZE];
#pragma unroll
for (int i = 0; i < NUM_ROWS_PER_THREAD; i++) {
const int row_idx = lane / NUM_V_VECS_PER_ROW + i * NUM_ROWS_PER_ITER;
if (row_idx < HEAD_SIZE && lane % NUM_V_VECS_PER_ROW == 0) {
dst[row_idx] = accs[i];
}
}
}
__syncthreads();
if (warp_idx < mid) {
const float* src = &out_smem[warp_idx * HEAD_SIZE];
#pragma unroll
for (int i = 0; i < NUM_ROWS_PER_THREAD; i++) {
const int row_idx = lane / NUM_V_VECS_PER_ROW + i * NUM_ROWS_PER_ITER;
if (row_idx < HEAD_SIZE && lane % NUM_V_VECS_PER_ROW == 0) {
accs[i] += src[row_idx];
}
}
}
__syncthreads();
}
After that, the kernel writes the final output and the whole attention computation is complete.
Closing Notes
That is roughly the full flow. There are still a lot of small design details in the implementation, and I am not sure I explained every one of them perfectly, but if you look at the code with this mental model in mind, the overall logic becomes much easier to follow.
Last modified on 2025-04-20