I am planning to organize some notes for DeepSeek’s open-source projects, and I also want to refresh my own memory along the way. I will start with FlashMLA.
FlashMLA is DeepSeek’s open-source MLA operator implementation. It is mainly used for inference decoding. Training and prefilling are handled by different kernels.
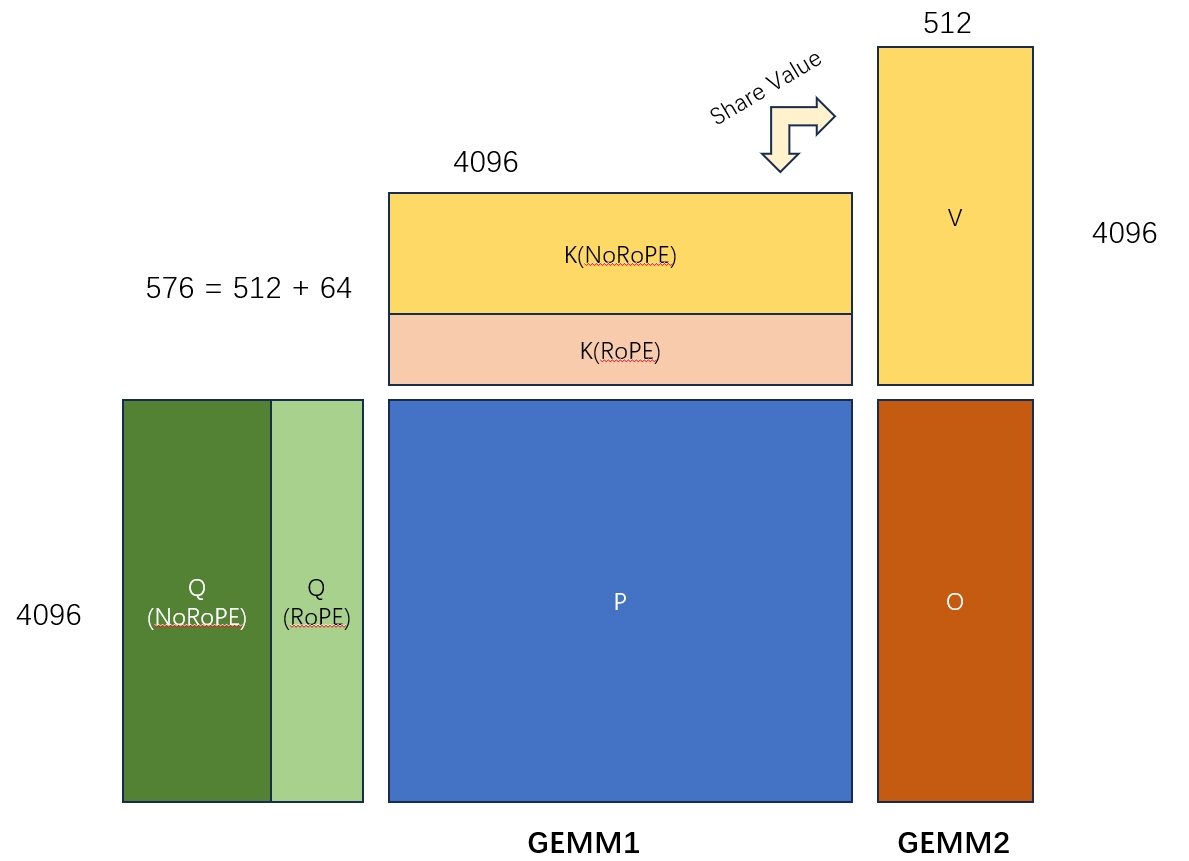
The figure below gives a rough picture of what the MLA operator computes. I will skip the detailed derivation here. Conceptually, it is a fusion of the following two GEMMs. A few details are worth noting:
- The K and V matrices share part of their parameters.
- The figure only shows the computation for one query head and one KV-head pair. In practice there are also
num_kv_headandbatch_sizedimensions. - There is a softmax between the two GEMMs, but online softmax lets us process it block by block, so it does not change the main computation pattern.
The kernel invocation has two major stages:
- Call
get_mla_metadatato compute metadata that helps optimize kernel execution. - Call
flash_mla_with_kvcacheto do the actual computation.
Before we get into the calls themselves, it helps to look at how FlashMLA partitions the work. This is very similar to FlashDecoding. A single thread block is not required to process an entire sequence. Instead, the runtime uses load balancing to group all sequences together, split them into sequence blocks, and then assign those blocks to thread blocks. The partial results are merged at the end.
It looks roughly like this:
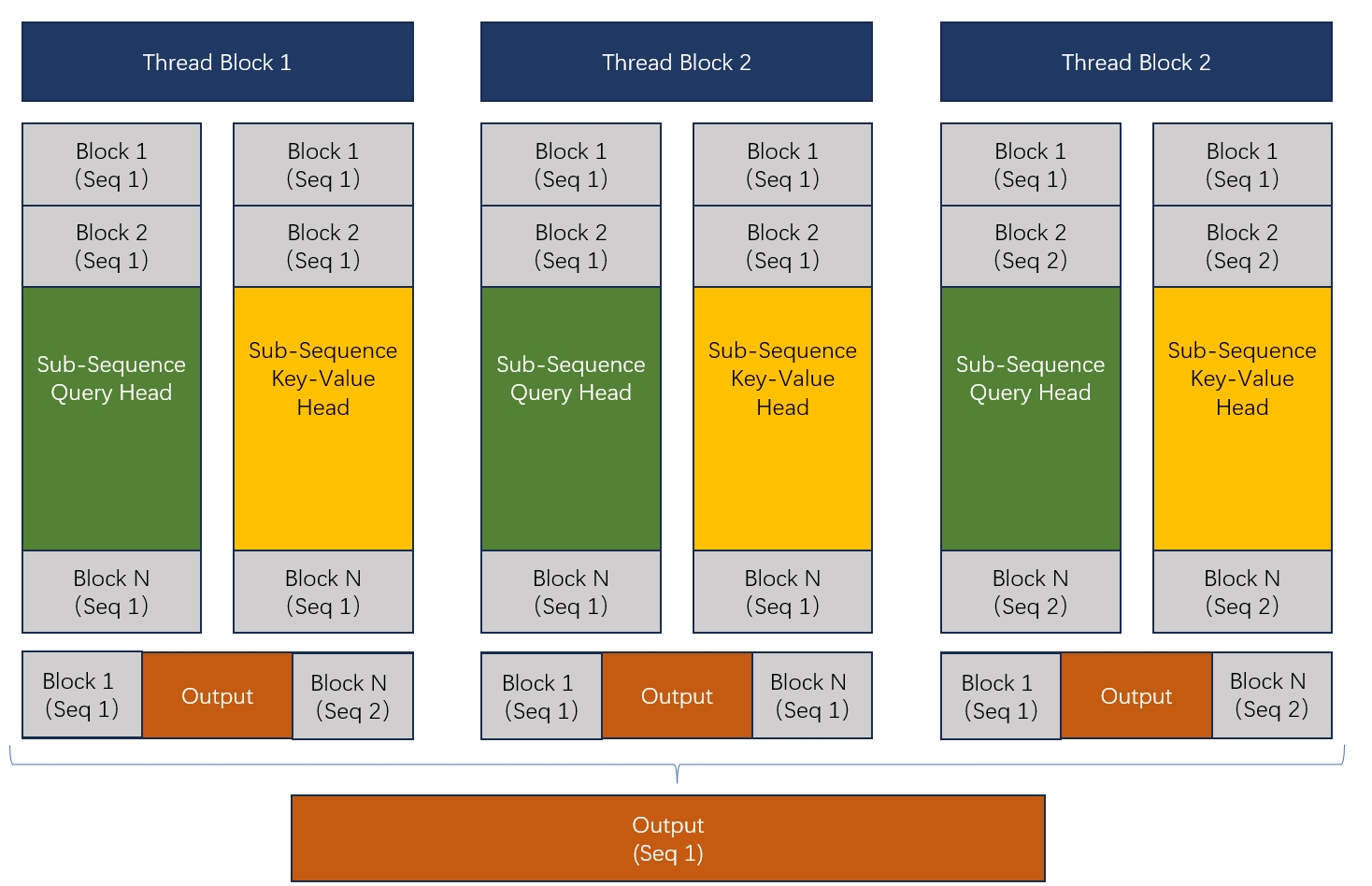
So the first step is to decide which subsequences each block should process. That is exactly what get_mla_metadata does.
get_mla_metadata
Let us start with the metadata returned by get_mla_metadata. The easiest way is to look at the repository’s test code in a simple configuration:
batch_size = 128query_sequence_len = 1mean_key_sequence_len = 4096MTP = 1num_kv_head = 1num_q_head = 16TP = 1hidden_NoRoPE_dim = 512hidden_RoPE_dim = 64varlen = False
# cache_seqlens = tensor([4096, 4096, ..., 4096], dtype=torch.int32),
# size=batch_size, value=sequence_len
# s_q = 1 (query_sequence_len = 1 and MTP = 1),
# h_q = 128 (TP = 1 = 128 / 128), h_kv = 1
tile_scheduler_metadata, num_splits = get_mla_metadata(
cache_seqlens, s_q * h_q // h_kv, h_kv
)
Because this is the decoding step, query_sequence_len = 1. The function takes three inputs:
- The size of the KV cache
- The number of query-head groups per KV head, similar to GQA
- The number of KV heads
get_mla_metadata uses the GPU SM count and the workload size to assign work to each SM. Note that get_mla_metadata_kernel is launched with <<<1, 32, 0, stream>>>, so the whole computation runs inside a single warp.
The key question is how the work is assigned to each SM or SM group.
First, several SMs cooperate on one KV head and one group of query heads:
int num_sm_parts = sm_count / num_heads_k / cutlass::ceil_div(num_heads_per_head_k, block_size_m);
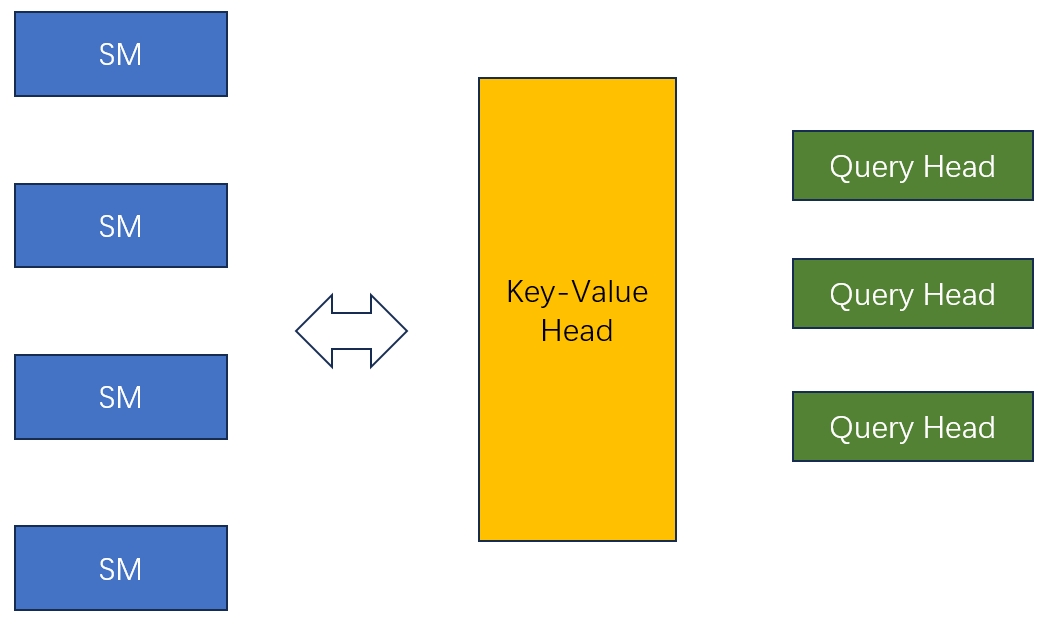
Then the system computes how many blocks each SM group has to handle and distributes those blocks to individual SMs. The overall process is:
- Use the batch size and
mean_key_sequence_lento compute the total number of blocks. - Assign work to each SM, including which tile indices it owns.
- Record the split points of each sequence so the outputs can be merged correctly later.
Once the work partition is done, we can move on to the main compute kernel.
flash_mla_with_kvcache
The flash_mla_with_kvcache function actually consists of two sub-kernels:
flash_fwd_splitkv_mla_kernel: loops over the assigned blocks and computes the per-block GEMMs.flash_fwd_splitkv_mla_combine_kernel: merges the partial results from multiple blocks to produce the final output.
flash_fwd_splitkv_mla_kernel
This kernel launches num_m_block * num_query_head * num_sm_parts thread blocks, where num_m_block = seqlen_q / block_size_m (64).
kernel<<<dim3(num_m_block, params.h, params.num_sm_parts), Kernel_traits::kNThreads, smem_size, stream>>>(params);
Note that seqlen_q here is no longer the original 1. In practice it becomes num_heads_per_head_k because seqlen_q = seqlen_q_ori * ngroups, and under MTP = 1 that equals num_heads_per_head_k.
So we get:
num_m_block = cutlass::ceil_div(num_heads_per_head_k, block_size_m)
If we combine this with the earlier SM-grouping formula:
Number of SMs = num_sm_parts * num_heads_k * ceil_div(num_heads_per_head_k, block_size_m)
= num_sm_parts * ceil_div(num_heads_k * num_heads_per_head_k, block_size_m)
= num_sm_parts * ceil_div(num_query_head, block_size_m)
= num_sm_parts * num_m_block
That means the SM count corresponds to the first and third dimensions of the thread-block grid.
The three dimensions in dim3(num_m_block, params.h, params.num_sm_parts) mean:
- Which query block this thread block handles
- Which query head it handles
- Which SM-group partition it belongs to
Now let us look at what each thread block actually computes. Multiple thread blocks cooperate to finish all the blocks assigned to an SM group.
The code shows two nested loops:
- The outer loop iterates over the query blocks assigned to this SM.
- The inner loop iterates over the KV-cache blocks and computes one block of the output.
- The kernel uses warp specialization with a producer-consumer pattern.
- Warp Group 1 does most of the attention-score computation.
- Warp Group 2 handles double-buffered data loading and also participates in some of the compute.
This part of the code is fairly complex. There are already a few good Zhihu posts explaining it in detail, so I will not reproduce the entire walkthrough here. The following figure captures the main idea.
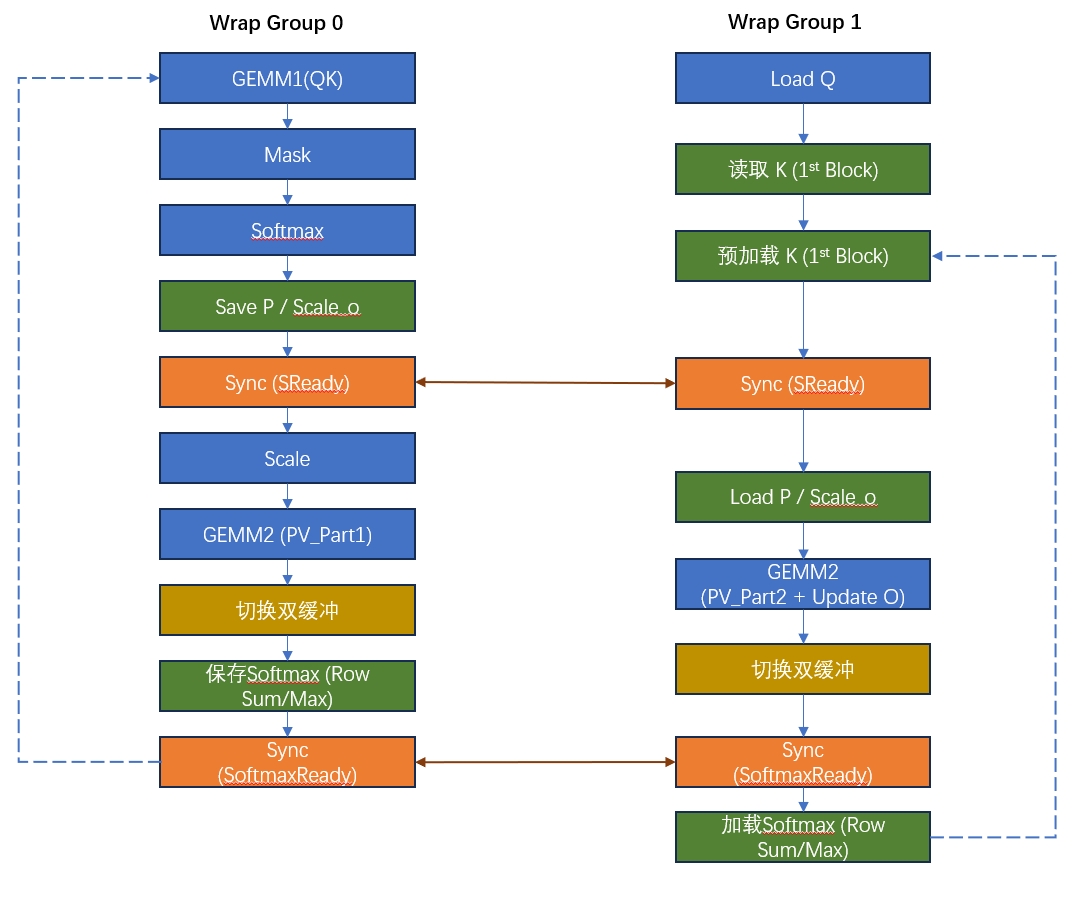
You can see that Warp Group 0 computes GEMM1, while GEMM2 is shared between the two warp groups, each handling half.
Two pieces of logic matter the most here.
- Warp specialization
int warp_group_idx = cutlass::canonical_warp_group_idx();
if (warp_group_idx == 0) {
// Main compute path: matrix multiply, normalization,
// probability matrix, and output.
// thread 0 - 127
....
} else {
// Mainly responsible for data loading.
// thread 128 - 256
}
- The double-buffering logic inside the
elsebranch
template<typename Kernel_traits>
struct SharedStorageMLA {
union {
struct {
...
cute::array_aligned<typename Kernel_traits::Element,
cute::cosize_v<typename Kernel_traits::SmemLayoutK> * 2> smem_k; // Double buffer
...
}
...
}
}
...
if (n_block % 2 == 1) {
constexpr int sK_offset = size(sK);
tSrK.data() = tSrK.data() + sK_offset / 8;
tOrVt.data() = tOrVt.data() + sK_offset / 8;
}
flash_fwd_splitkv_mla_combine_kernel
The final combine kernel is much simpler. It just merges the partial results:
- Warp 0 computes the maximum Log-Sum-Exp value across blocks to get the global normalization term.
for (int i = 0; i < kNLsePerThread; ++i) max_lse = max(max_lse, local_lse[i]);
- Warp 0 computes the scaling factors.
for (int i = 0; i < kNLsePerThread; ++i) {
const int split = i * 32 + tidx;
if (split < actual_num_splits) sLseScale[split] = expf(local_lse[i] - global_lse);
}
- The output blocks are rescaled and accumulated.
for (int split = 0; split < actual_num_splits; ++split) {
...
ElementAccum lse_scale = sLseScale[split];
for (int i = 0; i < size(tOrO); ++i) {
tOrO(i) += lse_scale * tOrOaccum(i);
}
...
}
- Finally the kernel writes the merged output back to global memory.
References
- DeepSeek-V2: A Strong, Economical, and Efficient Mixture-of-Experts Language Model
- DeepSeek: FlashMLA代码解析
- flashMLA 深度解析
Last modified on 2025-05-03