系列的前两篇文章写了线性注意力基本的理论和工程(Kernel),但是相关的内容只是针对开发环境的一些讨论,实际上在大规模部署时,我们为了更好地利用资源,往往需要做很多优化,这篇文章就从这些落地优化的角度聊一下线性注意力,以及为什么我们会认为现在线性注意力的infra只是在初级阶段。
量化
LLM.int8() 和 Massive Activations
早在ChatGPT爆火前,就有一些研究讨论了Full-Attention架构在量化时遇到的问题,在LLM.int8()这篇论文中,就提到在Full-Attention的激活值中有部分离群点会影响量化效果,因此建议把离群点和其他值分开处理:
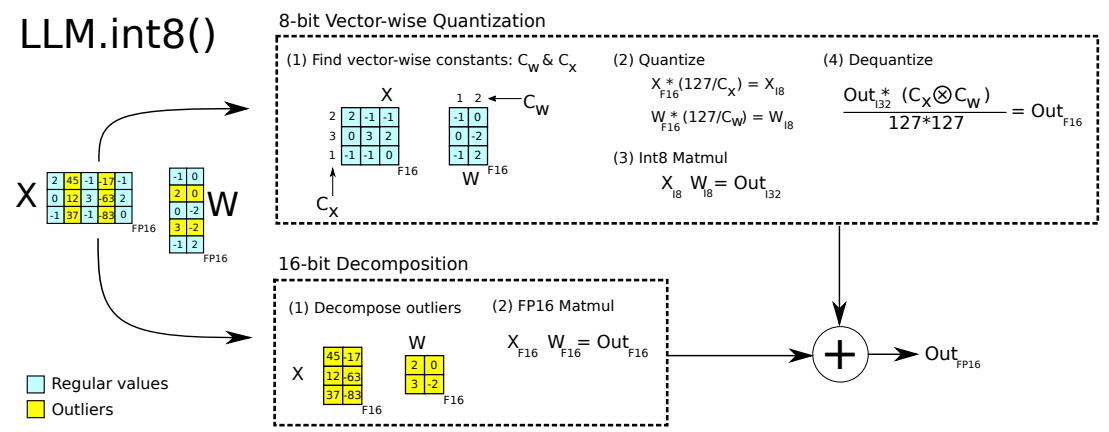
这一现象被称为Massive Activations,目前业界对这个现象进行了大量的研究,其中两个主要因素就是Softmax 和 RoPE。
Softmax 归一化:Softmax有着强制要求“总和为1”的特性,但是在实际的LLM运算中,我们往往有更复杂的需求(比如有时我们输入模型的问题比较简单,一个60层的网络可能在前40层就已经完成了计算,对于后面层我们需要的是一个什么都不做的操作,那么在残差网络的帮助下我们其实需要一个0输出),为了满足这种需求就会出现类似Attention Sink的现象,导致注意力集中于单一无关标记,同时产生massive activation。
RoPE位置编码:在文章Massive Values in Self-Attention Modules are the Key to Contextual Knowledge Understanding就提到:RoPE在Query/Key的通道维度对上应用了带有频率性角度参数的旋转变换,该变换依赖相对位置,同时在某些维度的投影上显著放大或缩小分量,从而导致部分维度“成簇集中”,出现了异常的spike值。 实际上,该文章也在实验中发现凡是采用 RoPE 的模型(如 LLaMA、Qwen、Gemma、Falcon 等)都会展示这种 massive values stripes,而不使用 RoPE 的模型(如 GPT-2、OPT、Jamba)则没有这一现象。
Linear Attention量化
虽然在Linear Attention中没有了Softmax和RoPE的干扰,大大缓解了上面提到的问题。比如A Unified View of Attention and Residual Sinks研究发现:将Full(Softmax) Attention替换为Linear-Attention后,隐藏状态的峰值激活从6000降到510,问题的复杂度似乎减少了很多。
但是,其实问题并没有被彻底解决,在不同的Linear Attention架构中仍然有着不同的问题:
- 状态累积:Linear Attention的递归特性导致数值误差或特定模式在时间步上不断累积。例如Mamba的PScan,在长序列下容易产生“长度诱导”的数值退化。
- 门控放大效应:GLA/Mamba 等架构大量使用的门控机制,其权重往往呈现“稀疏-极端”的双边分布,在不同的channel间拉大值的范围差异。
因此,针对Full-Attention设计的量化方案有些(如LLM.int8())可以用于Linear-Attention,但是也有些(如 SmoothQuant)难以直接迁移到Linear Attention领域,我们会需要针对不同架构设计架构感知的专用量化策略。
不过,相比下面两个领域,Linear Attention在模型量化领域的研究还是最多,相对最成熟的一个。
Prefix Cache
如果说量化并非LLM部署时的必选项,那么Prefix Cache(前缀缓存)一定是大规模部署时绕不过的一个策略。它允许复用之前的计算结果(KV Cache),对于多轮对话或Shared System Prompt场景,能极大地提升首字延迟TTFT和系统吞吐。
然而,Linear Attention并不能直接无缝的集成这一功能:
- In-Place更新:线性注意力的核心优势是将历史信息压缩成一个固定大小的状态矩阵 $h_t$。这意味着我们不再持有完整的历史上前缀token的信息(KV Cache),而只有一个不断原地更新的最新结果。
- 存储成本高:在标准的Full-Attention中,Prefix Cache 只需要按 Token 切分 KV Cache 即可,每个token的状态都非常小(如4KB)。但是在Linear Attention中,State 通常要大得多(如2MB),如果像Full-Attention那样高频保存,会迅速耗尽显存,无法工作。
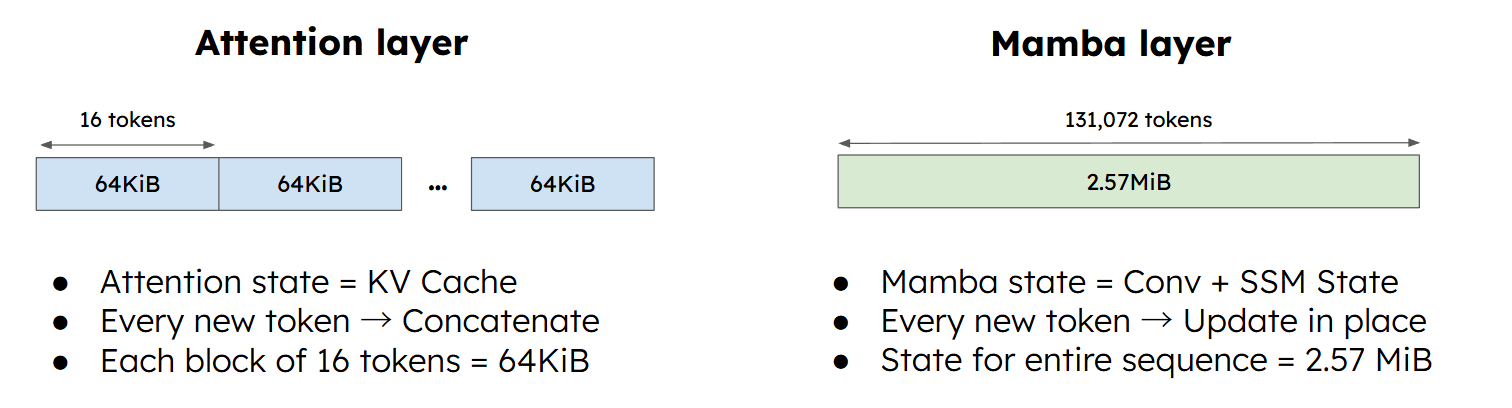
vLLM:Automatic Prefix Caching (APC)
针对这个问题,vLLM 社区(参考 #issues/26201)在推进针对 Hybrid Models的 APC 支持。其核心思路就是在粒度和存储之间进行妥协,通过更大的chunk(block) size来减少保存的成本。
统一 Block 管理
对于混合架构,vLLM 采用了统一的Block Manager。这意味着系统强制使用相同的Block Size(例如512)来管理 Linear Layer 的 State 和 Attention Layer 的 KV Block。
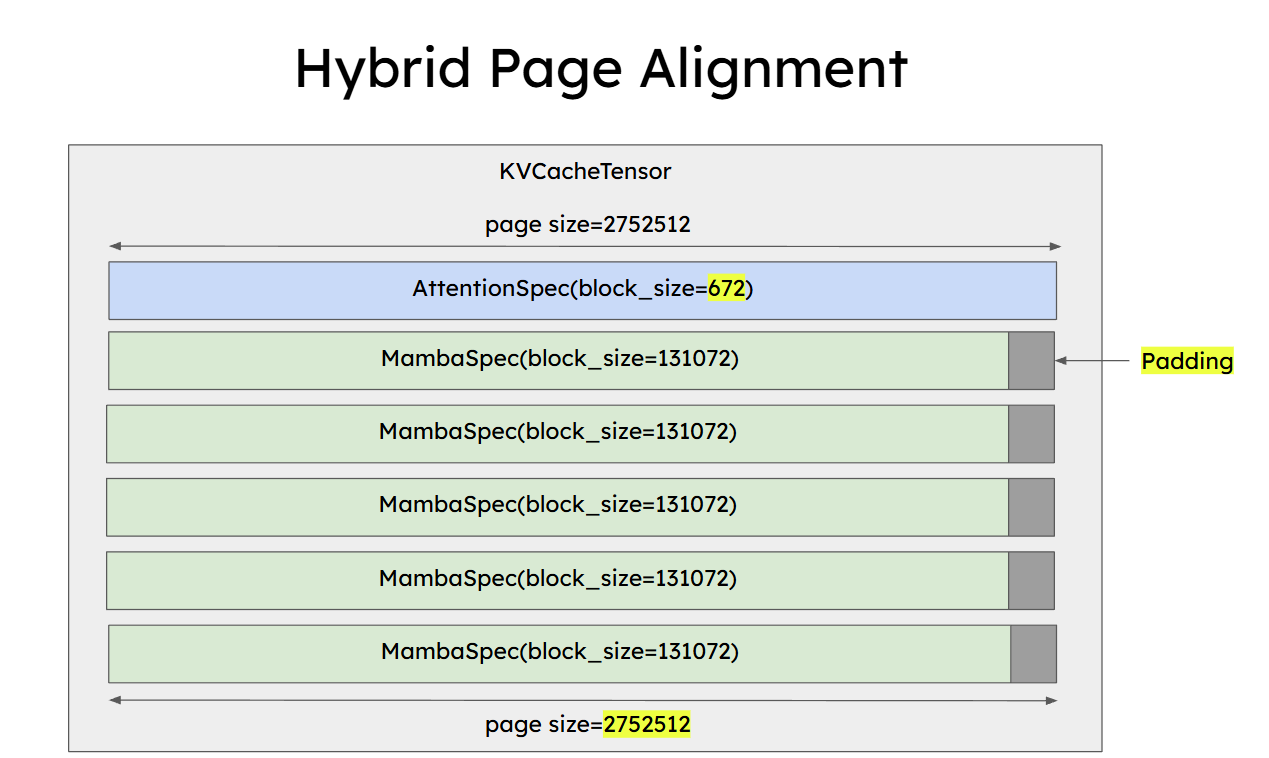
Checkpoint(State Cache)支持
为了实现缓存,vllm要求Linear Attention的算子和系统放弃原先“只保留一个最终 State”的做法,转而采用Checkpoint的方式,用相比Full-Attention更大粒度来进行状态的存储。
Prefill Kernel改造:相比之前的Prefill Kernel会一次性跑完所有Token并输出最终状态。支持 APC 的 Kernel 被改造为每隔一个 chunk_size就输出并保存一次当前的State。(实际上回忆一下我们之前工程篇的内容,这个机制可以很好地匹配原先cuda kernel的实现)
整体而言,由于 State 较大(2MB+),在混合注意力架构中我们往往要使用几百甚至上千的block_size,这会导致缓存命中率低于标准的Full-Attention,但在长文本对话场景中仍然有着很大的收益。
投机采样
虽然没有Prefix Cache那么重要,投机采样仍然是实际部署加速TPOT时候最有效的加速手段。
线性注意力的问题
然而,Linear Attention对投机采样支持存在很大的Gap。回忆我们在工程篇中的分析,Linear Attention 依赖两类核心算子:
- Parallel/Chunkwise Kernel (Prefill):并行度高,适合处理长序列(如 $L=8192$),但在处理投机采样的短序列(如 $K=5$)时,无法很好利用GPU的计算能力,启动开销占比过大。
- Recurrent/RNN Kernel (Decoding):串行计算,依赖上一时刻的 State $h_{t-1}$。如果用它来验证$K$个Token,必须串行执行$K$次,速度无法提升,缺少“并行验证”的能力。
更进一步的,现代的投机采样中往往包括树状结构(如 Medusa、Eagle 等),在标准的Full-Attention中,这一功能可以通过修改Attention Mask来轻松实现。但 Linear Attention没有 Mask机制:它是基于递归状态更新的,难以直接并行处理树状的分支结构。
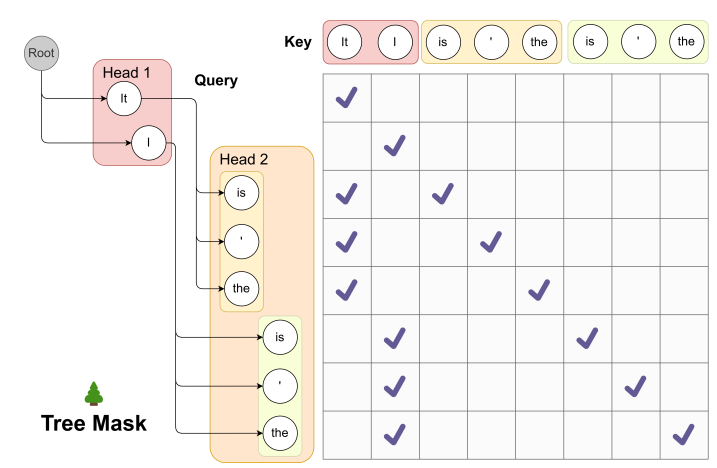
一些探索
目前学术界和工业界在这一领域的研究尚处于早期阶段。虽然像 When Linear Attention Meets Autoregressive Decoding 这样的工作提出了一些针对性的验证思路,但其开源实现只有一个非常简单的PyTorch脚本,并没有真正进行过任何验证。
要在工业界真正落地 Linear Attention 的投机采样,我们需要更加高效的Cuda Kernel:
- Small-Chunk Kernel:我们需要专门针对 $K=5 \sim 10$ 这种“微批次”场景优化的并行算子,并支持共享状态进行树形结构推理,从而最大程度降低Kernel Launch开销并提升Compute的密度。
- State Rollback 机制:由于 Linear Attention 的核心状态(Running State)是 In-place 更新的,当投机验证失败(Rejection)时,如何低成本地回滚状态是一个棘手的工程挑战(可能需要配合 Checkpoint 机制)。
回忆一下现在linear attention仅有的基于triton的flash linear attention,似乎这个距离还相当遥远….
总之,相比于量化和 Prefix Cache,Linear Attention 的投机采样目前还没有得到足够的重视,希望我们在26年能看到更多的成果。
Last modified on 2026-02-10