这段时间主要在做推理加速相关的工作,也做了一些实验,准备写点文章做一些记录。这篇文章就从“移动计算”和“移动存储”的视角开个头,聊聊并行策略的动态切换和KV Cache 流动管理的一些实践,梳理一下在 Agentic Workflow 日益普及的当下,我们能否通过对算力、存储与带宽的调度,在大规模集群上更好地提升推理效率。
在传统的大数据时代,“计算中心”还是“数据中心”一直是个有趣的问题。随着技术的发展,大家也逐渐总结出了 “Move Compute to Data” 的实践经验:因为 SSD 很贵、IO 很贵、带宽也很贵。相比之下,不如把代码调度过去,使用本地的 CPU 进行计算。因此,调度器的核心任务是保证 Data Locality,尽量把计算分发到数据所在的硬盘旁边。
但在 LLM 的时代,我们面对的是超大模型在 GPU 上的推理,移动计算已经变成了移动模型(权重)这个巨无霸。相比之下,似乎还是移动数据(KV Cache)更现实一些——但什么才是最合适的解法呢?
1. 需求的演变:从 Chat 到 Agent
系统架构的演进,必然是随着业务不断演变的。
第一阶段:单轮指令
- 特征:用户发送一句指令任务(如翻译、总结),模型执行并回复。请求之间几乎独立。
- 瓶颈:纯粹的算力(Prefill)或显存带宽(Decoding)。
- 调度:最简单的加权轮询。此时 KV Cache 的存在感很低,除了每台机器都有的 System Prompt,几乎没有状态复用的需求,我们可以随意把请求调度到任一台机器上执行。
第二阶段:多轮对话
- 特征:多轮对话可以通过 Prefix Caching 复用前面上文。Context 越来越长,每次对话对应一次交互。
- 瓶颈:显存容量 –> Prefill 时间
- 调度:开始引入 Affinity(亲和性) 调度——为了命中 Cache,我们尽量把请求发给存储了该用户历史数据的节点。也就是 “Move Compute to Data”,因为此时 Prefill(重算数据)太贵,而搬运 KV Cache 也还没在大规模集群中普及。但是这也会导致热点问题。
第三阶段:Agentic Workflow
- 特征:系统提示词、工具定义、思维链、上下文可以在并行的分支任务中共享,多轮对话可以并行执行,但对应一次交互(用户从感知多次交互变成感知任务完成)。
- 瓶颈:极其复杂的依赖关系,以及直接复用 KV Cache 带来的负载不均衡。
- 调度(面临的问题):如果 “Move Compute to Data” 会导致严重的热点问题——存有热门 Context 的节点会被打爆,而其他空闲节点却因为没有数据而帮不上忙。
可以看到,随着需求的变化,我们不再只关注单次请求的 TTFT/TPOT,而是开始关注整个 Agent 任务的 任务完成时间 以及系统的 总吞吐量。
2. 核心命题:移动计算 vs 移动存储
为了解决 Agent 时代的冲突,我们必须重新审视 调度策略的核心权衡。在大数据时代,移动数据(IO)是昂贵的;但在 LLM 时代,事情变得愈加复杂:
- 移动计算(权重)也变得更加复杂(移动权重、计算图编译等)。
- 计算资源逐渐替代存储成为主要成本(某存储团队原话:我们终于不是最贵的了)。
- NVLink/RDMA 让移动数据(KV Cache)变得越来越便宜。
此外,对于 LLM 来说,不同的并行策略会带来不同的性能表现,并适配不同的请求类型(比如 batch 大小、提示词长度、预填充、解码等),因此这里我们可以定义两种“移动计算”方式:
- 把计算移动到更合适、已经部署了模型的节点(如 PD 分离),无需移动权重。
- 把计算移动到新的、空白的节点(其实就是传统的 Auto Scaling)。
在目前的实践中,我们发现,在前面第 1 种约束下,后面这一种移动计算的成本巨大。再加上我们希望最大化系统资源利用率,通常只有在任务无法被当前系统处理时,才会把它作为最终手段。所以这里先不展开,重点放在第一种移动计算上,用它来约束移动计算的成本。
这样一来,调度器就面临一个二选一的困境:
| 策略 | A. 优先调度算力效率高的节点 (Compute-First) | B. 优先调度存储效率高的节点 (Data-First) |
|---|---|---|
| 代价 | 需要移动数据(KV Cache 迁移,消耗带宽) | 可能需要等待计算(排队)或进行低效计算 |
| 适用场景 | 带宽充足、延迟敏感、算力稀缺 | 带宽紧张、吞吐优先、算力充足 |
| 经典案例 | PD 分离、过热点保护 | 多轮对话(KV Cache 复用) |
这个权衡并非一成不变,它取决于以下几个关键变量:
-
算力 vs 带宽的相对稀缺性:
- 如果 GPU 算力极度紧张(如高峰期),让算力空转等待 Cache 命中是巨大浪费,此时应倾向于 A。
- 如果跨节点带宽是瓶颈(如跨机房),频繁移动 KV Cache 会引入不可接受的延迟,此时应倾向于 B。
-
Batching 策略:
- 大 Batch / 高吞吐场景:可以容忍一定的调度延迟来凑齐 Batch,倾向于 B。
- 小 Batch / 低延迟场景:每一毫秒都很宝贵,必须立即找到可用算力,倾向于 A。
-
延迟 vs 吞吐的优化目标:
3. Shift Parallelism:节点内的移动计算
Snowflake 提出的 Shift Parallelism 是一个非常巧妙的设计,通过对计算进行预先编排(移动计算),把运行时移动数据的成本降到了 0。
传统的推理部署要么是 TP(Tensor Parallelism,低延时),要么是 SP/DP(Sequence/Data Parallelism,高吞吐):
- 低负载时:我们想要 TP 来降低 Latency。
- 高负载时:我们想要 SP 来提升 Throughput。
Shift Parallelism 的核心观点是:与其移动数据(KV Cache),不如改变计算方式(并行策略)。
存储共享:KV Cache Invariance
Shift Parallelism 通过对不同并行策略的研究,发现 Ulysses SP 策略下 KV Cache 的内存布局与经典 TP 模式下完全一致。这意味着在运行时从 TP 切换到 SP 时,KV Cache 无需移动或重排,可以通过巧妙的计算编排,避免对存储进行移动。
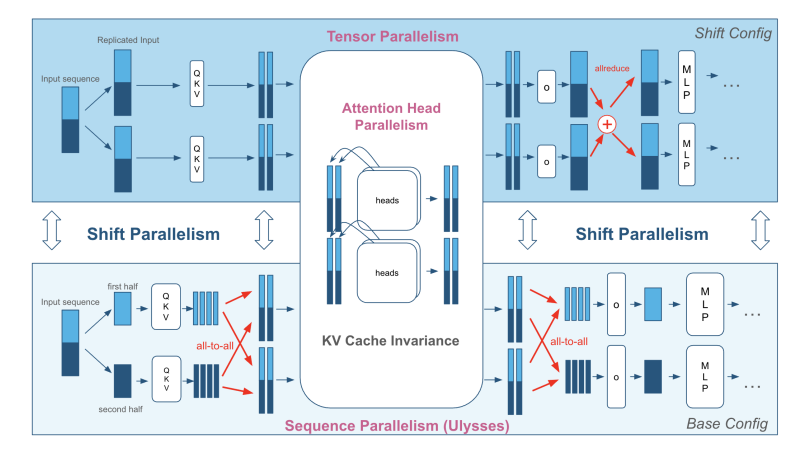
可以看出来,Shift Parallelism 选择了“存储共享”:通过预先对计算进行编排,把计算从一个进程移动到另一个进程来提升整体算力,降低计算能力的稀缺性。
不过,为了支持 TP 和 SP 的无缝切换,GPU 必须同时存储 TP 和 SP 所需要的不同权重。
一些实验观察: 我也基于相关代码 ArcticInference 做了一些实验和分析。在目前的实现中,TP 和 SP 实际上是存了两份权重,其中在每块 GPU 上,SP 所需要的权重又是 TP 的超集。
虽然理论上可以只保留 SP 一份权重,但对性能会有极大的损耗,这里主要问题在于 GEMM 计算时对权重矩阵连续性的要求:
- 计算 Kernel(如 cuBLAS)通常要求输入 Tensor 在内存中是连续的,直接切分 SP 的权重矩阵无法满足这一要求。
- 虽然理论上可以通过编写定制的 CUDA Kernel 来处理这种复杂的非连续内存映射,但工程复杂度较高,而且分散的内存读取极易破坏合并访问,仍然会导致实际带宽利用率下降。
因此,Shift Parallelism 使用 显存空间(冗余权重) 换取了 计算移动的灵活性(动态并行策略),从而避免了高昂的运行时数据搬运。
4. llm-d:集群间的“数据流”
如果说 Shift Parallelism 延续的是“让计算适应数据”的思路,那么 llm-d 则提出了“让数据移向计算”:作为 Agentic Runtime,主张 KV Cache 在集群间流动。
打破 Data Locality 执念
前文提到,Agent 工作流的负载较为复杂,而且极不均衡。llm-d 作为集群的入口,不再只关心单次请求的流量,而是希望整体优化任务完成时间。其社区最新的提案中,提倡利用 P2P NVLink/RDMA 实现 KV Cache 的快速流转。这意味着调度器可以更自由地选择最空闲或逻辑最近的计算节点,而不是被历史遗留的 Cache 死死绑在某个过载的节点上。
这让人想起云原生数据库从“Shared-Nothing”走向“存算分离(Shared-Storage/Memory)”的演进路线。未来的推理集群,很可能是一个巨大的、通过高速总线互联的共享显存池。
语义化 KV Cache
为了让这种“流动”更高效,社区认为 llm-d 不能傻傻地移动所有数据,而是应该让集群调度器理解 Agent 工作流,理解 KV Cache:
- System Prompt / Tool 定义:高频复用的“静态”数据 -> **主动复制(推送)**到多个节点。
- Reasoning Branch:用完即弃的“瞬态”数据 -> 低优先级驱逐。
这里又回到了权衡:对于高频数据,我们通过复制来减少传输;对于低频数据,我们通过传输来平衡算力。
这实际上对 llm-d 的调度提出了更高的要求:KV Cache 的复制不再是请求到来时的被动转移,系统需要具备类似于指令预取的调度预测能力,通过提前对 KV Cache 进行编排来保证缓存的可用性。
5. 思考与未来:重构推理系统的时空观
将两者的思路结合来看,未来的推理系统架构可能会展现出以下特征:
- 层次化的灵活性:
- 在节点内部: 利用类似 Shift Parallelism 的技术,保持 KV Cache 不动,动态调整计算图(TP/SP),平衡延迟与吞吐。
- 在集群层面: 利用语义化 KV Cache 和 P2P 网络,主动移动 KV Cache,平衡节点间的负载。
- KV Cache 从“静态缓存”变为“流动的数据”: 它不再是单纯被动被命中的 Cache,而是被系统调度的核心资源。它可以作为静态数据驻留,也可以按照实际需求动态流转。
- 智能调度与流量塑性: 为了更智能地进行调度,未来的调度策略不会只停留在被动转发流量,而是需要主动参与数据聚合和 KV Cache 的流动,让不同类型的负载在时间维度上更好地重叠与错峰,从而摊薄一些难以避免的开销。
- 计算语境的代价与以空间换时间:
无论是 Shift Parallelism 中冗余的权重,还是 llm-d 中主动复制的上下文,其本质都在说明:权重和上下文本质上都是计算语境的一部分。
- 运行时重构语境(重新切分权重、重算上下文)极其昂贵(占用 SM、需要重新编译 CUDA 图)。
- 因此,“以空间换时间” 将成为常态。即使显存昂贵,但为了更好更便利的计算流动性,我们依然愿意支付这份“存储税”。
最后简单提一下百度最新的研究(如 SPS)。文章中提出的策略已经不再是简单的实时流量转发,而是通过感知负载的方式对流量进行重组:调度器可以把请求缓存在本地,等满足一定条件后再统一下发,主动将负载塑造成适合当前系统状态的形式。这相当于把原来在服务端做的动态攒批能力,上移到了网关调度层。
延续这些研究的思路,未来推理系统与调度服务之间的边界会变得越来越模糊,“网关 + 推理引擎”这两层调度器之间也会越来越紧密。调度的思路也会从被动处理请求,转向主动管理计算和数据:在上游通过攒批塑造流量形态,在中游通过并行策略切换匹配算力形态,在下游通过 KV Cache 的流动与复制打通存储形态。
看上去推理加速正在从单纯的“算子优化”走向“系统级编排”,这个演变的核心,仍然围绕着计算和存储的移动。在叠加多模态、稀疏注意力、线性注意力、Engram 等架构优化之后,我们以后看到的也许是一个巨大的推理集群,而不再是一个“网关 -> 推理引擎”的两层服务。
总之我们在 26 年还有很多可以继续探索的空间。
Last modified on 2026-01-29