3月底整理了一个关于经典Paged Attention算法的ppt, 想起这个几年没写过的blog,把PPT改成一篇文章证明我还活着(-_-)。

vLLM 的 Paged Attention
开始前先说明一下,vLLM里的Paged Attention Kernel是有好几个不同的版本的,大概是下面这样子:
vLLM早期版本:
- Prefilling -> Flash Attention的flash_attn_varlen_func
- Dedocding -> 自己实现的Paged Attention
- paged_attention_v1 : 用于比较短的sequence
- paged_attention_v2 : 用于不想用v1的情况 :)
源码大概是这样的:
# NOTE(woosuk): We use a simple heuristic to decide whether to use
# PagedAttention V1 or V2. If the number of partitions is 1, we use
# V1 to avoid the overhead of reduction. Also, if the number of
# sequences or heads is large, we use V1 since there is enough work
# to parallelize.
# TODO(woosuk): Tune this heuristic.
# For context len > 8192, use V2 kernel to avoid shared memory
# shortage.
use_v1 = (max_seq_len <= 8192 and (max_num_partitions == 1 or num_seqs * num_heads > 512))
vLLM 最新版本就已经全部转向Flash Attention, 用cutlass实现了。
背景
多目标优化中有一个很常见的跷跷板问题,就是说在训练时,多个目标会相互影响,导致震荡—你降我升,我升你降。有时间还会出现Nan的结果,需要很仔细的调参测试+清洗数据才能训练出一个理想的模型。
针对这种问题,自然就有了一些尝试,比如从帕累托最优的角度寻找优化方向(阿里PEA),修改模型结构使Shared部分存储更泛化的信息(腾讯PLE)。不过这两个写的人都挺多了,就写一下Google Small Towers的这篇文章吧。
主要问题讨论
文章首先讨论了两个问题:
1. Over-parameterization对多任务模型的适用性
我们都知道over-parameterization对单任务模型是有价值的,那边对多任务模型是否成立?
这里以将多个目标的线性组合作为优化目标的例子,认为over-parameterization能够帮助处理各任务优化目标之间的冲突问题(既减少跷跷板问题的出现)。
2. 大型模型和小型模型的多目标学习表现对比
通过实验对比了大型模型和小型模型进行多目标学习中的不同表现。
实验中,不论是增加任务相关结构的复杂度,还是增加任务共享结构的复杂度,Pareto frontier都会呈现先变好在变差的趋势。
因此,文章认为over-parameterization并不利于多目标学习中的共享性,进而伤害了多目标学习中的泛化能力。因此,在多目标学习中,模型大小实质上是对模型有效性和泛化能力的一种平衡。
To summarize our insights, for a multi-task learning model, small models benefit from good multi-task generalization but hurts Pareto efficiency; big models theoretically have better Pareto efficiency but could suffer from loss of generalization.
Under-parameterized Self-auxiliaries模型结构
文章提出了under-parameterized self-auxiliaries的模型结构:
首先假设模型的共享方式是所有任务共享最下面的表示层(Hard Sharded,MMOE这种,PLE就不行),既对任务t,有:
$$f_{t}(x; \theta_{sh}, \theta_{t})=f_{t}(h(x; \theta_{sh}); \theta_{t}), \forall t$$
其中 $\theta_t$ 是任务相关的参数, $\theta_sh$ 为共享参数, $h(x;\theta_sh)$ 既为共享的表示层输出。
好久没写博客了,今天写一点推荐系统周边设施的东西。
特征管理
特征商店会存储特征元数据,比如特征的计算逻辑、血缘关系、数据类型。 一般来说,这些元数据用于管理特征的生命周期、计算任务和使用方式。
离线训练数据生成
为了保证线上线下数据的一致性,推荐系统的训练数据通常有两个数据流Join得到:
- 在Ranking中即实时打点:数据流以
traceId为Key,排序时特征为Value。 - 客户端日志:记录了
traceId和事件类型(曝光、点击、分享等)
由于客户端日志必然晚于服务端日志,因此两个数据流Join时需要一定的窗口。
训练数据扩展
但是作为调参工程师,我们必然会遇到需要的特征没有记录在实时打点中,导致训练时缺少相关数据的情况,这个时候,就需要想办法来处理这个问题。
按照Uber的方法,我们可以把特征分为三类:
- 离线特征
- 实时特征
- RPC特征
离线特征
对于离线特征:我们可以使用Spark读取数据仓库中的历史数据,以天为单位进行生成历史数据,然后放在一个分区的Hive表中。
实时特征
对于实时特征:基于kappa的思想,我们可以在Flink中编写实时特征计算逻辑,然后启动重跑一段时间以前的历史数据,并记录这个过程中特征的每一次变化(有点类似数据库中的WAL日志流),将其输出到Kafka中去,这样我们也就有一个特征在历史时间段中的值。(这里我们最好有一个服务化的Flink平台,来进行任务的添加、删除、修改等工作)
这里,特征的计算任务就可以通过特征元数据库进行管理。
接下来,我们就可以通过带时间戳的Join来完成训练数据和特征数据的拼接,并将特征回写到训练数据中去了。 需要注意的是,为了保证线上线下数据的一致性,我们需要引入一定的延时机制来模拟客户端日志的延迟。
RPC特征
最后对于来自外部系统的RPC特征:就没有什么好办法了,我们只能在线上添加这个特征的打点,然后跑上一段时间来得到有这个特征的训练数据了。
这里推荐一个比较新的开源项目可以完成类似的工作: Feast
在线特征推送
特征的线上存储可以使用KV数据库比如Redis,数据的来源和上面训练数据的扩展可以使用同一套代码,只需要在计算时根据元数据配置来决定是否推送上线。
另外,这里一般会做很多工程上的优化,比如:
- 把多个特征作为一个特征组存在一个key里减少请求的次数
- 使用一些算法(比如XXHash32)对过长的特征名(比如
spu$realtime$orders_last_2w$spu_id)进行压缩
NPE(NullPointerException)是一个很烦人的问题,这里简单列举了一些语言中对NPE的处理。
1. 通过语法标记进行检查
Kotlin
Kotlin要求可以为null的变量必需在定义时声明,同时在读取该类型变量属性时必须进行空值判断。例:String 和 String?
var a: String = "abc"
a = null // compilation error, a can not be null
var b: String? = "abc"
b = null // ok
val l = b.length // compiler error: variable 'b' can be null
val l = if (b != null) b.length else -1 // ok
Jetbrains annotations for Java
IntelliJ IDEA提供了一些工具,比如可以对@NotNull的参数进行检查,当出现null赋值时在IDE中会给出提示。
import org.jetbrains.annotations.NotNull;
import java.util.ArrayList;
public class Test{
public void foo(@NotNull Object param){
int i = param.hashCode();
}
public void test(){
foo(null); // warn in IntelliJ IDEA
}
}
(类似的,FindBugs也提供了@Nonnull注释,用于检查)
HttpServerModule的请求主要由HttpServer中的HttpServerTransport (默认为NettyHttpServerTransport)类处理。
NettyHttpServerTransport基于netty框架,负责监听并建立连接,信息的处理由内部类HttpChannelPipelineFactory 完成。
每当产生一个连接时,都会发出一个ChannelEvent,该Event由一系列的ChannelHandler进行处理。
为了方便组织,这些ChannelHandler被放在一条“流(pipeline)”里,一个ChannelEvent并不会主动的”流”经所有的Handler,而是由上一个Handler显式的调用ChannelPipeline.sendUp(Down)stream产生,并交给下一个Handler处理。
换句话说,每个Handler接收到一个ChannelEvent,并处理结束后,如果需要继续处理,那么它需要调用sendUp(Down)stream新发起一个事件。如果它不再发起事件,那么处理就到此结束,即使它后面仍然有Handler没有执行。这个机制可以保证最大的灵活性,当然对Handler的先后顺序也有了更严格的要求。
在流Pipeline里有一个Map(name2ctx)和一个链表(记录head和tail),pipeline里面会调度关联的多个channelhandler的运行。
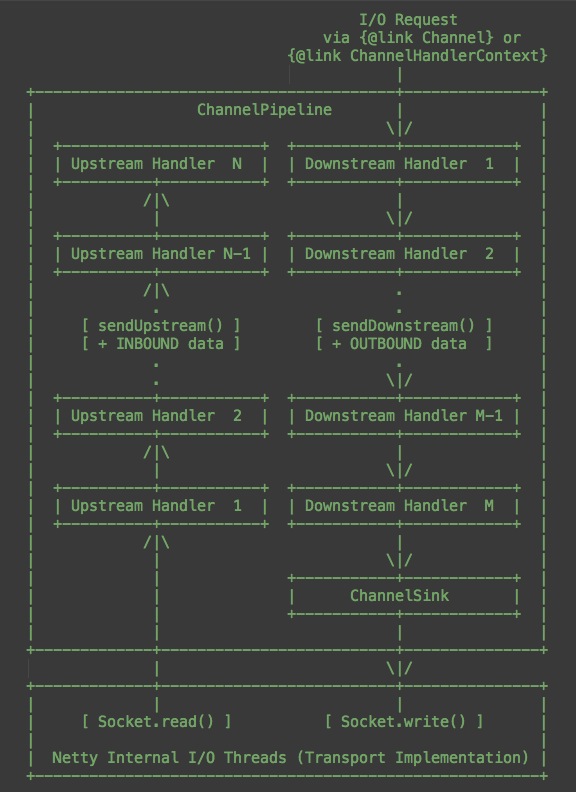
在NettyHttpServerTransport中,会流过的channelhandler就包括解码http请求(把多个HttpChunk拼起来并按http协议进行解析)和http请求处理。
在处理http请求,数据流向为:HttpRequestHandler->NettyHttpServerTransport->HttpServerAdapter(HttpServer的内部类Dispatche)->RestController。
RestController中的处理代码为:
void executeHandler(RestRequest request, RestChannel channel) throws Exception {
final RestHandler handler = getHandler(request);
if (handler != null) {
handler.handleRequest(request, channel);
} else {
if (request.method() == RestRequest.Method.OPTIONS) {
// when we have OPTIONS request, simply send OK by default
// (with the Access Control Origin header which gets automatically added)
channel.sendResponse(new BytesRestResponse(OK));
} else {
channel.sendResponse(new BytesRestResponse(
BAD_REQUEST,
"No handler found for uri [" + request.uri() + "] and method [" + request.method() + "]"
));
}
}
}
private RestHandler getHandler(RestRequest request) {
String path = getPath(request);
RestRequest.Method method = request.method();
if (method == RestRequest.Method.GET) {
return getHandlers.retrieve(path, request.params());
} else if (method == RestRequest.Method.POST) {
return postHandlers.retrieve(path, request.params());
} else if (method == RestRequest.Method.PUT) {
return putHandlers.retrieve(path, request.params());
} else if (method == RestRequest.Method.DELETE) {
return deleteHandlers.retrieve(path, request.params());
} else if (method == RestRequest.Method.HEAD) {
return headHandlers.retrieve(path, request.params());
} else if (method == RestRequest.Method.OPTIONS) {
return optionsHandlers.retrieve(path, request.params());
} else {
return null;
}
}
void executeHandler(RestRequest request, RestChannel channel) throws Exception { final RestHandler handler = getHandler(request); if (handler != null) { handler.handleRequest(request, channel); } else { if (request.method() == RestRequest.Method.OPTIONS) { // when we have OPTIONS request, simply send OK by default (with the Access Control Origin header which gets automatically added) channel.sendResponse(new BytesRestResponse(OK)); } else { channel.sendResponse(new BytesRestResponse(BAD_REQUEST, “No handler found for uri [” + request.uri() + “] and method [” + request.method() + “]”)); } } }
Tornado是一款轻量级的Web服务器,同时又是一个开发框架。采用单线程非阻塞I/O模型(epoll),主要是为了应对高并发 访问量而被开发出来,尤其适用于comet应用。
Tornado服务器3大核心模块:
(1) IOLoop
Tornado为了实现高并发和高性能,使用了一个IOLoop来处理socket的读写事件,IOLoop基于epoll,可以高效的响应网络事件。这是Tornado高效的保证。
tornado.ioloop.IOLoop.instance().start()
IOLoop使用了单例模式,处理所有IO事件,
实现为EPollIOLoop->PollIOLoop->IOLoop->Configurable
IOLoop中有四个重要的数据集: _events 和 _handlers 保存I/O事件和对应的处理器, _callbacks 和 _timeouts 保存(超时)回调。
关键函数:
def initialize(self, impl, time_func=None):
super(PollIOLoop, self).initialize()
self._impl = impl
if hasattr(self._impl, 'fileno'):
set_close_exec(self._impl.fileno())
self.time_func = time_func or time.time
#handlers 是一个函数集字典
self._handlers = {}
self._events = {}
#回调函数集合
self._callbacks = []
self._callback_lock = threading.Lock()
self._timeouts = []
self._cancellations = 0
self._running = False
self._stopped = False
self._closing = False
self._thread_ident = None
self._blocking_signal_threshold = None
self._timeout_counter = itertools.count()
# Create a pipe that we send bogus data to when we want to wake
# the I/O loop when it is idle
self._waker = Waker()
self.add_handler(self._waker.fileno(),
lambda fd, events: self._waker.consume(),
self.READ)
其中,waker是一个发伪数据用的类,在需要时,我们可以用它唤醒空闲的I/O Loop。当我们调用add_callback时,为了让回调函数运行,可能会需要使用它发送一个伪数据。
最近在做搜索,抽空看一下lucene,资料挺多的,不过大部分都是3.x了……在对着官方文档大概看一下。
优化后的lucene索引文件(4.9.0)

一、段文件
1.段文件:segments_5p和segments.gen。
segments.gen保存当前段文件版本信息。
- segments.gen: GenHeader, Generation, Generation, Footer
segments_N(segments_5p)保存最新的段的信息,包括段的个数,每个段的段名、文档数等信息。
-
segments_N: Header, Version, NameCounter, SegCount,
源码参考:SegmentInfos.read(Directory directory, String segmentFileName):
2.段信息:*.si,存储段的基本信息。
- .si: Header, SegVersion, SegSize, IsCompoundFile, Diagnostics, Attributes, Files
只对4.0-4.5使用,新版已经抛弃了,可以无视。