准备写一些关于线性注意力的文章,对相关理论和工程(Kernel)做一些梳理,这一篇是关于基础理论的。
Softmax Attention到线性注意力
Softmax Attention与O(N^2)复杂度
标准的Transformer使用的是Softmax Attention。给定查询(Query)、键(Key)、值(Value)矩阵 $Q, K, V \in \mathbb{R}^{N \times d}$,其中 $N$ 是序列长度,$d$ 是特征维度(通常 $d \ll N$)。Attention的计算公式为:
$$ Attention(Q, K, V) = \text{softmax}\left(\frac{QK^T}{\sqrt{d}}\right)V $$
让我们仔细分析一下这个计算过程的维度变化:
- 计算相似度矩阵:$QK^T$。
- $Q$ 是 $N \times d$,$K^T$ 是 $d \times N$。
- 相乘得到 $N \times N$ 的矩阵。这一步的计算复杂度是 $O(N^2 d)$。
- 应用Softmax:对每一行进行归一化,维度不变,仍为 $N \times N$。
- 加权求和:乘以 $V$。
- $N \times N$ 的矩阵乘以 $N \times d$ 的矩阵 $V$。
- 结果是 $N \times d$。这一步的计算复杂度也是 $O(N^2 d)$。
瓶颈所在: 由于Softmax是非线性的,我们必须先完整地计算出 $N \times N$ 的Attention Matrix。
- 计算复杂度:$O(N^2 d)$。随着序列长度 $N$ 的增加,计算量呈平方级增长。
- 显存占用:$O(N^2)$(如果不使用FlashAttention等优化)。需要存储 $N \times N$ 的矩阵。
- KV Cache:在推理时,为了避免重复计算,我们需要缓存所有的 $K$ 和 $V$,显存占用为 $O(Nd)$。
之前大部分情况下这个问题不大, 但是随着Agent能力的发展,Context越来越长,这个 $O(N^2)$ 的复杂度就变得有些过高了。
线性注意力 (Linear Attention)
线性注意力的核心思想是:如果我们能去掉Softmax,或者将其替换为某种核函数 $\phi(\cdot)$,我们就可以利用矩阵乘法的结合律优化计算。
假设我们将相似度函数定义为 $\text{sim}(q, k) = \phi(q)^T \phi(k)$,其中 $\phi(\cdot)$ 是一个特征映射函数(Feature Map),将输入映射到某个特征空间。那么Attention公式变为:
$$ Attention(Q, K, V) = \left( \phi(Q) \phi(K)^T \right) V $$
这里 $\phi(Q)$ 和 $\phi(K)$ 的维度仍然是 $N \times d$(假设特征映射不改变维度,或者映射到 $D$ 维)。
基于结合律的化简: 矩阵乘法满足结合律 $(AB)C = A(BC)$。我们可以改变计算顺序:
$$ Attention(Q, K, V) = \phi(Q) \left( \phi(K)^T V \right) $$
(注:标准的Linear Attention公式通常包含一个分母归一化项 $\phi(Q) (\phi(K)^T \mathbf{1})$ 以保持数值尺度,此处为了简化推导过程省略了该项。)
让我们看看现在的计算过程:
- 先计算 $\phi(K)^T V$:
- $\phi(K)^T$ 是 $d \times N$,$V$ 是 $N \times d$。
- 相乘得到一个 $d \times d$ 的矩阵。我们称之为 状态矩阵 (State Matrix) 或 KV Memory。
- 计算复杂度:$O(N d^2)$。
- 再左乘 $\phi(Q)$:
- $\phi(Q)$ 是 $N \times d$,状态矩阵是 $d \times d$。
- 相乘得到 $N \times d$ 的结果。
- 计算复杂度:$O(N d^2)$。
优势:
- 总复杂度:$O(N d^2)$。由于 $d$ 通常是一个较小的常数(如64, 128),这相对于序列长度 $N$ 是线性的。
- 显存占用:我们只需要维护一个 $d \times d$ 的状态矩阵,与 $N$ 无关。
循环神经网络 (RNN View)
线性注意力不仅计算高效,而且可以写成RNN的形式,这对于自回归生成(Inference)非常友好。
我们可以将上述矩阵运算写成累加的形式。对于第 $t$ 个时刻的输出 $o_t$:
$$ o_t = \sum_{i=1}^t \text{sim}(q_t, k_i) v_i = \sum_{i=1}^t (\phi(q_t)^T \phi(k_i)) v_i $$
提取出与 $i$ 无关的项 $\phi(q_t)$:
$$ o_t = \phi(q_t)^T \sum_{i=1}^t \phi(k_i) v_i^T $$
我们可以定义状态 $S_t = \sum_{i=1}^t \phi(k_i) v_i^T$。这个状态 $S_t$ 是一个 $d \times d$ 的矩阵。 显然,它可以递归地计算:
$$ S_t = S_{t-1} + \phi(k_t) \phi(v_t)^T $$ $$ o_t = \phi(q_t)^T S_t $$
这就是线性注意力的RNN形式:
- 更新 (Update):用当前的 $k_t$ 和 $v_t$ 更新状态 $S$。
- 查询 (Query):用当前的 $q_t$ 从状态 $S$ 中提取信息。
这解释了为什么线性注意力在推理时极其高效:它不需要像Softmax Attention那样重新访问所有的历史KV Cache,只需要维护一个固定大小的状态 $S$。
线性注意力的设计思路与框架
经典的线性注意力虽然看上去可行,但是效果并不好,需要找到一些入手点,在整个公式的这个基础上进行进一步的优化。
常见的线性注意力有多种不同的叙事方式,这里用比较有名的Mamba(SSM)和DeltaNet举例说明:
状态空间模型 (SSM)
Mamba系列的架构基于状态空间模型(State Space Models, SSM),这个模型起源于控制理论,用来描述连续空间上的状态变化。
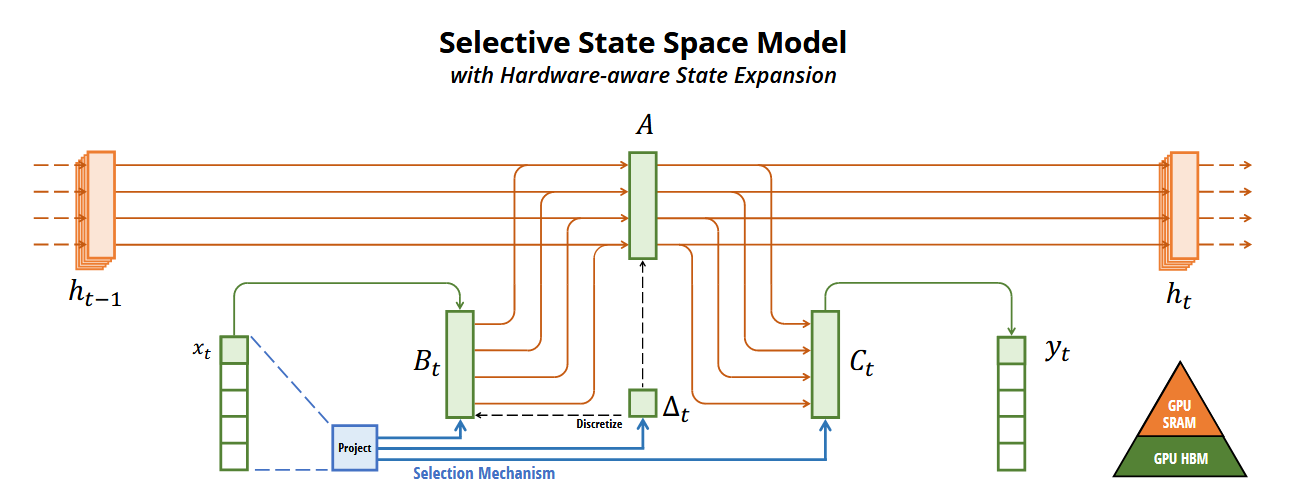
Mamba SSM Architecture
连续时序空间:SSM通常定义在连续时间上,描述了一个系统如何根据输入 $x(t)$ 更新其内部状态 $h(t)$ 并产生输出 $y(t)$: $$ h’(t) = A h(t) + B x(t) $$ $$ y(t) = C h(t) $$ 其中 $A$ 是状态转移矩阵,$B$ 是输入投影,$C$ 是输出投影。
到离散状态空间:为了在计算机上处理离散的序列数据(如文本),我们需要将连续系统离散化。常用的方法是零阶保持 (ZOH)。 基于该方法离散化后,我们去掉了导数,公式变为递归形式: $$ h_t = \bar{A}t h{t-1} + \bar{B}_t x_t $$ $$ y_t = C h_t $$
其中 $\bar{A}_t$ 和 $\bar{B}_t$ 是 $A, B$ 和采样步长 $\Delta_t$ 的函数。例如,在ZOH下,$\bar{A}_t = \exp(\Delta_t A)$。
与Linear Attention的联系: 仔细观察离散化后的SSM公式,它与Linear Attention的RNN形式惊人地相似:
- Linear Attention: $S_t = I \cdot S_{t-1} + \phi(k_t) \phi(v_t)^T$
- SSM: $h_t = \bar{A} h_{t-1} + \bar{B} x_t$
如果我们将Linear Attention中的状态衰减看作 $\bar{A}$,将键值对的更新看作输入项,两者在数学形式上是高度统一的。 Mamba 的创新之处在于引入了选择性机制(Selection Mechanism),让参数 $B, C, \Delta$ 成为输入 $x_t$ 的函数(即 $B(x_t), C(x_t), \Delta(x_t)$)。这使得模型能够根据当前的内容动态地决定“记住什么”和“忽略什么”,从而解决了传统LTI(线性时不变)系统无法进行上下文推理的问题。
半可分离矩阵
接下来我们对Mamba架构进行进一步推导:
先不考虑随着时间变化的$\Delta(x_t)$,对于整个序列 $x = [x_1, \dots, x_L]$ 和输出 $y = [y_1, \dots, y_L]$,把Mamba的公式展开,我们会发现这个变换可以写成 $y = M x$,其中 $M$ 是一个下三角矩阵。
可以得到一个半可分离矩阵 (Semiseparable Matrix) 的形式。(推导过程略)
$$ M = \begin{pmatrix} C_0 B_0 & 0 & \dots & 0 \\ C_1 A_1 B_0 & C_1 B_1 & \dots & 0 \\ \vdots & \vdots & \ddots & \vdots \\ C_L A_L \dots A_1 B_0 & \dots & \dots & C_L B_L \end{pmatrix} $$
矩阵 $M$ 的第 $(i, j)$ 个元素($i \ge j$)表示第 $j$ 个输入对第 $i$ 个输出的影响: $$ M_{ij} = C_i (A_i A_{i-1} \dots A_{j+1}) B_j $$
在Mamba中,为了计算效率,矩阵 $A$ 通常被设计为对角矩阵。
当 $A_t$ 是对角矩阵时,矩阵乘法满足交换律。我们可以把累乘项 $A_{i} \dots A_{j+1}$ 分解。 定义 $L_t = \prod_{k=1}^t A_k$ 为从时刻 1 到 $t$ 的累积衰减。那么对于 $i > j$,有: $$ A_{i} \dots A_{j+1} = L_i L_j^{-1} $$
代入 $M_{ij}$ 的公式: $$ M_{ij} = C_i (L_i L_j^{-1}) B_j = (C_i L_i) (L_j^{-1} B_j) $$
如果我们定义:
- $Q_i = C_i L_i$
- $K_j = (L_j^{-1} B_j)^T$
- $V_j = x_j$ (这里输入 $x$ 扮演 Value 的角色)
那么输出 $y_i = \sum_{j=0}^i M_{ij} x_j$ 就可以写成: $$ y_i = \sum_{j=0}^i (Q_i K_j^T) V_j $$
注意:该推导对于随着时间变换的 $\Delta(x_t)$ 同样有效: $\Delta(x_t)$ 作为采样步长是一个标量,而对角矩阵的exp仍然是对角矩阵。
这正是前文线性注意力的形式!
通过这种变换,Mamba2揭示了 SSM (State Space Models) 和 Attention 之间的对偶性。
- SSM视角:通过递归公式 $h_t = A_t h_{t-1} + B_t x_t$ 进行 $O(N)$ 的推理。
- Attention视角:通过矩阵乘法 $Y = \text{CausalMask}(QK^T)V$ 进行并行训练。
Mamba2 SSD Architecture
Mamba2在SSM的基础上提出了新的SSD(State Space Duality)架构: 从公式外观上看,Mamba2延续了Mamba的基本形式,但它通过引入更严格的结构约束,对底层架构进行了重构。Mamba2的核心设计目标是最大化硬件效率,特别是针对GPU Tensor Cores的利用率。
与Mamba1的关键区别:
Mamba2的架构被称为SSD,可以认为是SSM的一种特例:
-
矩阵 $A$ 的约束:
- Mamba1: 通常每个 $A_t$ 都是对角矩阵,每个特征维度(Channel)拥有独立的衰减参数。
- Mamba2: 将每个 $A_t$ 进一步限制为标量(Scalar),即在每个Head内部,所有特征维度共享同一个衰减参数 ($A_t = a_t I$)。
-
计算范式:
- Mamba1: 主要依赖并行扫描 算法。这是一种内存密集型操作,难以利用GPU上专为矩阵乘法设计的Tensor Cores。
- Mamba2: 得益于 $A$ 的标量化和SSD对偶性,Mamba2可以将计算重写为分块矩阵乘法。这使得计算可以运行在Tensor Cores上,极大地提高了训练吞吐量。
总的来说,Mamba2是为了算法-硬件协同设计优化硬件利用效率,对Mamba1表达能力的“简化”(从对角矩阵简化为标量)。虽然Mamba2牺牲了一些自由度,但是换取的工程效率提升可以用来扩展状态的维度d,因此在实践中性能反而会有所提高,也使得模型能够扩展到更大的参数规模和更长的序列长度。
Mamba3进一步优化
Mamba3是对SSM的进一步优化,旨在解决Mamba2为了硬件效率(标量化A)而牺牲的部分表达能力。它主要引入了以下几个关键改进(本文只阐述思路,细节可以参考论文):
-
复数状态空间: Mamba2中的状态转移矩阵 $A$ 是实数标量,只能表达指数衰减。Mamba3将 $A$ 扩展为复数,引入了旋转机制。这使得状态不仅能衰减,还能像RoPE一样在复平面上旋转,从而更好地捕捉周期性模式和长距离依赖。
-
梯形法则离散化: 之前的SSM的离散化使用的是最简单的零阶保持 (ZOH) 假设(假设信号在采样间隔内不变)。而Mamba3改用了精度更高的梯形法则(假设信号线性变化),能够更准确地追踪快速变化的信号。
-
Multi-Input Multi-Output: Mamba2在SSM层面上是SISO的,即各个通道间独立演化。Mamba3通过把状态更新中的外积换成矩阵乘来允许不同通道的信息交互实现MIMO,提高对Tensor Core的利用效率。
Key的正交假设与Delta Rule
Delta Rule从另一个角度对线性注意力进行了推演。
在标准的线性Attention更新规则 $S_t = S_{t-1} + k_t v_t^T$ 中,我们简单地将新的键值对叠加到状态矩阵中。 这种更新方式类似于神经科学中的 Hebbian Learning(赫布学习规则):“Cells that fire together, wire together”。我们简单地增加 $k_t$ 和 $v_t$ 之间的关联强度。
潜在问题: 这隐含了一个假设:Key之间是正交的。 如果 $k_t$ 与之前的 $k_{t-1}$ 高度相似(不正交),那么 $S_{t-1} k_t$(即模型对当前Key的旧预测)将不为零。简单的叠加会导致信息的冗余和干扰,使得检索时出现噪声。这里有两种常见的信息冲突:
-
单个Key的多义性: 在长序列中,同一个Key(或者语义上非常相似的Key)可能会出现多次,但对应不同的Value。例如,单词 “Apple” 可能在一段话中指代水果,在另一段话中指代公司。 在简单的线性叠加 $S_t = \sum k_i v_i^T$ 中,这些不同的Value会被直接相加。当我们用 “Apple” 去查询时,得到的是所有历史Value的混合(平均),而不是特定上下文下的那个Value。这导致了语义的模糊。
-
不同Key的相关性: 理想情况下,我们希望Key之间是正交的,这样更新一个Key不会影响其他Key。但实际上,Key向量通常存在复杂的协方差结构(Covariance)。 如果 $k_t$ 与之前的 $k_{j}$ 高度相关(非正交),那么向状态 $S$ 中添加 $k_t v_t^T$ 不仅更新了 $k_t$ 的方向,也会改变 $k_{j}$ 方向上的投影。这意味着,新信息的写入会干扰旧信息的读取,产生“串扰” (Crosstalk)。
Transformer的处理方式
标准的Softmax Attention通过加权平均来处理这种冲突。它显式地计算 Query 与所有历史 Key 的相似度,然后对 Value 进行加权。
- 对于多义性,Softmax可以通过上下文(Query)和位置编码来区分同一个Key的不同实例,给予不同的权重。
- 对于相关性,Softmax是非线性的,它不需要将历史压缩成一个线性算子,因此不存在“写入新Key破坏旧Key结构”的问题(它只是增加了一个新的参考点)。
而Linear Attention试图将所有历史压缩进一个固定大小的线性算子 $S$,就必须面对这种压缩带来的冲突。
Delta Rule (DeltaNet)
为了解决这个问题,DeltaNet 等工作引入了 Delta Rule(也称为Widrow-Hoff规则或LMS算法)。 更新公式变为: $$ S_t = S_{t-1} + \beta_t (v_t - S_{t-1} k_t) k_t^T $$
让我们分解这个公式:
- 预测:$S_{t-1} k_t$ 是模型根据旧状态对当前Key $k_t$ 的预测值(Retrieve Value)。
- 误差:$e_t = v_t - S_{t-1} k_t$ 是真实值 $v_t$ 与预测值之间的差异。
- 修正:我们只将这个“误差”部分更新到状态矩阵中。
在下一个章节中,我们会提到:这本质上是在进行一步在线梯度下降,试图最小化当前输入下的重构误差。这使得模型在有限的容量($d \times d$)下,能够更精确地存储和检索信息,避免了重复信息的累积。
类似的加权平均
如果我们观察状态 $S$ 在 $k_t$ 方向上的投影(假设 $k_t$ 是单位向量),更新公式可以近似理解为: $$ \text{NewValue} \approx (1 - \beta_t) \cdot \text{OldValue} + \beta_t \cdot v_t $$ 这实际上是一个指数移动平均 (Exponential Moving Average, EMA)。
- Softmax Attention:是空间上的加权平均。在推理时(基于新的Query),它同时看到所有历史,并根据相似度分配权重。
- Delta Rule:是时间上的加权平均。在更新时,它通过 $\beta_t$(类似于学习率)动态决定是“保持旧记忆”还是“重写为新记忆”。
- 当同一个Key出现多次(多义性)时,Delta Rule 允许模型根据 $\beta_t$ 逐渐遗忘旧的含义,聚焦于最新的含义,从而在效果上实现了对不同Value的“选择”或“加权”。
状态的遗忘机制
标准的线性Attention(如Linear Transformer)通常对所有历史一视同仁,即 $S_t = \sum k_i v_i^T$,通过位置编码来解决不同位置的重要性问题。而在线性注意力中,通常会使用衰减的机制达成类似的效果:在语言建模中,局部性 通常很重要:最近的上下文往往比遥远的上下文更相关。
RetNett 引入了类似下面的指数衰减机制: $$ S_t = \gamma S_{t-1} + k_t v_t^T $$ 其中 $\gamma \in (0, 1)$ 是衰减因子。
类似的,Gated DeltaNet在DeltaNet的基础上引入衰减机制,而Kimi Delta Attention使用对角矩阵 $Diag(r_t)$ 进行更细粒度的衰减,增强了模型了表达能力。
直观理解:
- 相对位置编码:这种机制巧妙地编码了相对位置信息。对于第 $n$ 个位置的查询 $q_n$ 和第 $m$ 个位置的键 $k_m$ ($m < n$),它们之间的相互作用会被乘以 $\gamma^{n-m}$。这自然地表达了“距离越远,影响越弱”的归纳偏置。
- 软滑动窗口:这相当于给历史信息加了一个指数衰减的权重窗口。越久远的信息,权重越小($\gamma^k$),逐渐被“遗忘”。
这种遗忘机制不仅提高了模型对局部信息的关注度,还增强了数值稳定性,防止状态 $S_t$ 的值无限增长。
此外,我们还可以通过对不同的head引入不同的衰减系数来捕捉不同的时间尺度敏感性。
Test Time Regression (TTR) 框架
关于TTR视角有一篇很好的论文:《Test-time regression: a unifying framework for designing sequence models with associative memory》,该视角将Attention机制视为在测试时(Inference time)进行的回归任务。这个框架帮助我们理解为什么Linear Attention在某些任务上表现不如Softmax Attention。
我们将Attention看作是学习一个函数 $f: \mathbb{R}^d \to \mathbb{R}^d$,使得 $f(k_i) \approx v_i$。
Nonparametric Regression (Full Attention)
Full Attention对应于非参数回归(Nonparametric Regression),或者称为对偶形式 (Dual Form)。
- 机制:模型显式地存储了所有的历史训练样本 $(K, V)$。
- 预测:当一个新的查询 $q$ 到来时,它通过计算 $q$ 与所有样本 $k_i$ 的相似度(核函数 $K(q, k_i)$)来加权平均 $v_i$。 $$ o = \sum_i \frac{K(q, k_i)}{\sum_j K(q, k_j)} v_i $$
- 特点:
- 背诵:直接利用原始数据不进行任何压缩。
- 容量:随着序列长度 $N$ 线性增长。理论上,只要 $N$ 足够大,它可以完美回忆起任何见过的细节。
- 代价:推理成本高昂 ($O(N)$),因为每次都要遍历所有样本。
Parametric Regression (Linear Attention)
Linear Attention对应于参数回归(Parametric Regression),或者称为原始形式 (Primal Form)。
- 机制:我们不再存储所有的原始数据,而是维护一个固定大小的参数矩阵 $S$(即RNN状态)。
- 学习:这个过程可以看作是使用在线梯度下降来更新模型参数 $S$,使其能够拟合历史数据 $(k, v)$ 的映射关系。 $$ S_t = S_{t-1} + k_t v_t^T $$
- 预测:当查询 $q$ 到来时,我们直接使用学习到的模型进行预测: $$ o = S q $$
- 特点:
- 拟合:它试图将所有历史信息压缩进一个固定大小的矩阵 $S$ 中,学习一个函数来通过key来提取value。
- 容量:受限于状态 $S$ 的大小($d \times d$)。如果历史信息过于复杂或庞大,状态矩阵可能会饱和,导致旧信息的灾难性遗忘。
- 代价:推理成本固定 ($O(1)$),极其高效。
梯度下降视角的详细推导
为了更深入地理解这一点,我们可以显式地写出优化目标。 假设我们的目标是学习一个矩阵 $S$,使得对于所有的历史时刻 $i$,都有 $S k_i \approx v_i$。 我们可以定义在时刻 $t$ 的瞬时损失函数为最小二乘误差: $$ L_t(S) = \frac{1}{2} | S k_t - v_t |^2 $$
我们使用随机梯度下降 (SGD) 来更新 $S$: $$ S_t = S_{t-1} - \eta \nabla_S L_t(S_{t-1}) $$
计算梯度: $$ \nabla_S L_t(S) = (S k_t - v_t) k_t^T $$
代入更新公式(设学习率 $\eta$ 为步长): $$ S_t = S_{t-1} + \eta (v_t - S_{t-1} k_t) k_t^T $$
这就是前文中Delta Rule的形式。
-
标准Linear Attention的特例: 如果我们假设 $S_{t-1}$ 初始化为0,或者更强地假设 Key之间是正交的(即 $S_{t-1} k_t \approx 0$,旧状态对当前Key没有响应),那么公式简化为: $$ S_t = S_{t-1} + \eta v_t k_t^T $$ 这正是标准的Linear Attention更新规则(通常 $\eta=1$)。
-
结论:
- 标准Linear Attention 对应于假设了Key正交性的“懒惰”更新。
- DeltaNet 对应于完整的梯度下降更新,它显式地计算并消除了预测误差(残差)。
RWKV-7 与 TTT (Test-Time Training): 最新的 RWKV-7 和 TTT-Linear 等架构进一步深化了这个视角。它们将RNN的推理过程明确建模为测试时的训练过程。
- TTT框架认为,Hidden State本质上是一个小模型的参数,而处理序列的过程就是在这个小模型上进行梯度下降。
- RWKV-7 引入了更加动态的状态演化机制,其状态更新不再是简单的线性累加,而是包含了更复杂的、数据依赖的衰减和更新项。这可以被理解为一种广义的、带有自适应学习率的在线优化过程,使得模型在处理长上下文时,能够更智能地决定哪些信息该“学进”状态里,哪些该忽略。
实际上,从这个视角出发,使用不同的优化算法如带动量的SGD、L2正则化等策略,可以推导出其他一些linear attention的算法架构。
最后,这个视角其实也解释了Linear Attention在处理“大海捞针”任务时的劣势。因为压缩必然带来有损,当需要精确检索某个特定的历史细节时,参数化的Linear Attention可能无法从压缩的状态中完美还原,而非参数化的Softmax Attention则可以直接查阅原始记录。
一些Trick与优化
最后聊一聊为了弥补Linear Attention相对于Softmax Attention的不足(如缺乏局部关注能力、数值稳定性等),研究者们引入的一些Trick或优化思路。
因果卷积与Token-Shift
问题: Softmax Attention由于指数函数的存在,天然倾向于关注局部(最近的邻居通常相似度较高)。而Linear Attention的关注分布通常比较平滑,容易忽略局部的细节。 此外,RNN形式的状态 $S_t$ 只能捕捉到 $t$ 时刻之前的信息,对于“当前时刻”的局部特征捕捉能力较弱。
解决方案: 像Mamba、RWKV和RetNet等模型通常会在进入状态空间之前,先对输入进行一个短窗口的因果卷积(Causal Conv1d)。
- RWKV-4 (Token Shift): RWKV-4率先引入了极其轻量级的 Token Shift 机制(也称为Time Mixing的一部分)。它简单地将当前时刻的输入 $x_t$ 与上一时刻的输入 $x_{t-1}$ 进行线性插值:$x’t = \mu x_t + (1-\mu) x{t-1}$。这可以看作是核大小为2的因果卷积,极低成本地实现了相邻Token的信息交互。
- Mamba: 使用了显式的1D卷积层(通常kernel size=4),在进入SSM状态方程之前混合局部信息。
$$ x’t = \text{Conv1d}(x{t-k:t}) $$
作用:
- 增强局部性:这相当于显式地让模型“看到”最近的几个Token。
- 平移不变性:卷积操作具有平移不变性,有助于捕捉局部的n-gram特征。
- 弥补RNN缺陷:它充当了一个“预处理”步骤,捕捉高频的局部特征,而让RNN状态专注于捕捉低频的全局依赖。
DPLR (Diagonal-Plus-Low-Rank) 矩阵
问题: 在SSM中,我们需要处理长序列。如果状态转移矩阵 $A$ 初始化不当,梯度可能会在反向传播中消失或爆炸。此外,计算 $A$ 的幂次或卷积核需要高效的算法。
解决方案: HiPPO理论指出,特定的矩阵结构可以最优地记忆历史。S4模型提出将 $A$ 参数化为对角矩阵加上低秩矩阵(DPLR)的形式: $$ A = \Lambda - pp^* $$
作用:
- 计算效率:这种结构减少了参数量,也允许我们利用Woodbury矩阵恒等式和Cauchy Kernel等算法,大幅降低矩阵逆运算和卷积的计算复杂度。
- 数值稳定性:它使得矩阵 $A$ 的特征值分布在左半复平面,保证了系统的稳定性(不会发散)。
虽然在Mamba中,为了硬件效率,作者简化为了纯对角矩阵,但DPLR在理论推导和早期SSM模型中起到了至关重要的作用。
位置编码
现在的Linear Attention都是使用NoPE的策略,但是这不意味着Linear Attention就一定不可以使用位置编码:
RetNet 提出了一种方法,将位置编码融入到状态的衰减中。通过给 $S_t$ 乘以一个复数衰减因子 $e^{i\theta}$,实现了类似RoPE的效果,同时保持了递归形式的高效性。 $$ S_t = \gamma e^{i\theta} S_{t-1} + k_t v_t^T $$ 这种方法被称为 xPos 的变体或其在RNN中的自然延伸。它使得模型能够根据Token之间的相对距离动态调整关注强度。
ROSA
最后,ROSA是RWKV-8提出的策略,其目的是通过外挂历史输入数据库的方式帮助模型检索历史信息。 由于RWKV-8的论文尚未发表,目前只能通过一些零散的信息和github上的代码(话说还有最近的RWKV Devday活动)来对这个方案给出一些描述。
不同于传统 RNN 仅依赖隐状态压缩历史信息,ROSA 在推理过程中在线构建后缀自动机。它不仅作用于输入 Token,更通过二值化机制在每个隐藏层建立特征索引——相当于每一层都维护了一套动态的“特征码表”。
在推理时,ROSA 能够利用自动机特性,瞬间检索出当前上下文在历史中最长的匹配片段,并将当时的后续状态直接用于下一个token的预测。
目前看起来,ROSA是一种对历史信息进行记忆的新的思路,跳出了TTT的框架,也许有很大的潜力,等论文和Scale上去的实验结果出来后非常值得深入研究一下。
Last modified on 2025-12-16