背景
从年初 R1 火起来以后,看到了很多关于智能本质的讨论,目前大部分讨论似乎都认为:语言才是智能的基础,是通往 AGI 的路径。
比如张小珺[1-3]今年采访了很多大佬,就有两个这样的例子:
-
杨植麟[1]:认为在现有范式下,多模态能力往往难以提升模型的“智商”,甚至可能损伤模型已有的语言智能。他在接受采访时提到:“如果你想给模型加多模态能力,你需要确保这个多模态能力不要损伤它的‘脑子’。多模态能做到不损伤已经很好了。”他指出,在多模态模式下希望模型和纯文本模式共用一个“大脑”——也即多模态部分应尽量借用文本模型已有的智力,而不是开启另一套全新参数,否则可能丢掉原来文本部分学到的能力。
-
姚顺雨[2]也强调语言在通向通用智能方面更具潜力。他起初从事计算机视觉研究,但后来直觉告诉他语言才是更核心、更有潜力的方向,因此读博后转向了语言模型的研究。他指出,语言是人类为了实现认知泛化而发明的最重要工具,具有生成和推理的闭环特性,这使其成为构建通用智能系统的关键媒介。
不过还是有一些其他的观点,认为多模态能力的潜力可能被训练范式所限制,而非多模态本身毫无助益。例如阶跃星辰的张祥雨[3]就提到:
-
图文数据效果不好的原因是噪声数据:如果简单用图文混合数据进行训练,但不解决思维链(CoT)推理或任务复杂度的问题,模型的学习可能是有害的。在缺乏正确推理指导的情况下,模型每一步可能得不到有效信息,产生错乱的梯度,训练效果要么毫无提升,要么甚至更糟。这与他在一个万亿参数多模态模型项目中的发现一致:模型规模增大后,其数学和逻辑推理能力不仅没有提升,反而在达到平台期后开始下降。原因在于模型倾向于跳步直接给出答案而非踏实推演,从而累积误差。简单扩大模型或混合数据并不能自然地融合视觉与文本能力,背后缺少关键环节。
-
图文推理的能力同样需要预训练的激活:例如,OpenAI 的 O3 模型在推理过程中能够将图像直接融入思维链,通过动态操作图像(旋转、裁剪等)来辅助解题,在视觉推理基准 V⋆Bench 上取得了 95.7% 的高准确率,刷新了多模态推理上限。令人意外的是,O3 所采用的一些方法(如对原图进行局部放大裁剪)看似原始,却在许多问题上效果很好。他认为:这可能是因为在海量预训练语料中,存在大量图像附带局部放大及文字解释的模式。例如在电子维修论坛中,经常有人上传一张设备照片提问“哪里出了问题”,回答者会圈出图片局部并放大,说明某个电容烧了等。模型在预训练中已经隐式学习了这种“先整体看图 → 再局部看图解释”的模式。因此,像 O3 那样在推理时按需裁剪图像,严格遵循了预训练语料中的分布模式,反而取得了出色效果。
针对这个问题,想写一些自己对这个领域的了解和看法。
Vision LM 的推理能力研究
在开始讨论前,我先对智商这个事情做一个定义:通常我们可以把模型的能力分为理解、推理、生成三种,我们认为其中推理能力是智商的表现。
Vision CoT
链式思维(CoT)是大模型提升复杂推理最早被证明有效的范式之一;其视觉扩展(Vision CoT / Visual CoT)在 2023 年起就开始出现。早期的工作以语言+图像作为输出,但是以CoT只会以文本给出,这个时候图像不参与推理的过程,图像带来的推理能力自然就无从谈起。
后来O3的兴起带火了一个新的方向:thinking with images,其核心思想:不要把“看图”当成一次性输入,而是让图像参与到逐步推理循环中,成为中间状态的生成与消费对象。也就是说图像开始参与了推理的过程,因此我们就从这里作为了解Vision LM推理能力的起点。
(下图是thinking with images的例子)
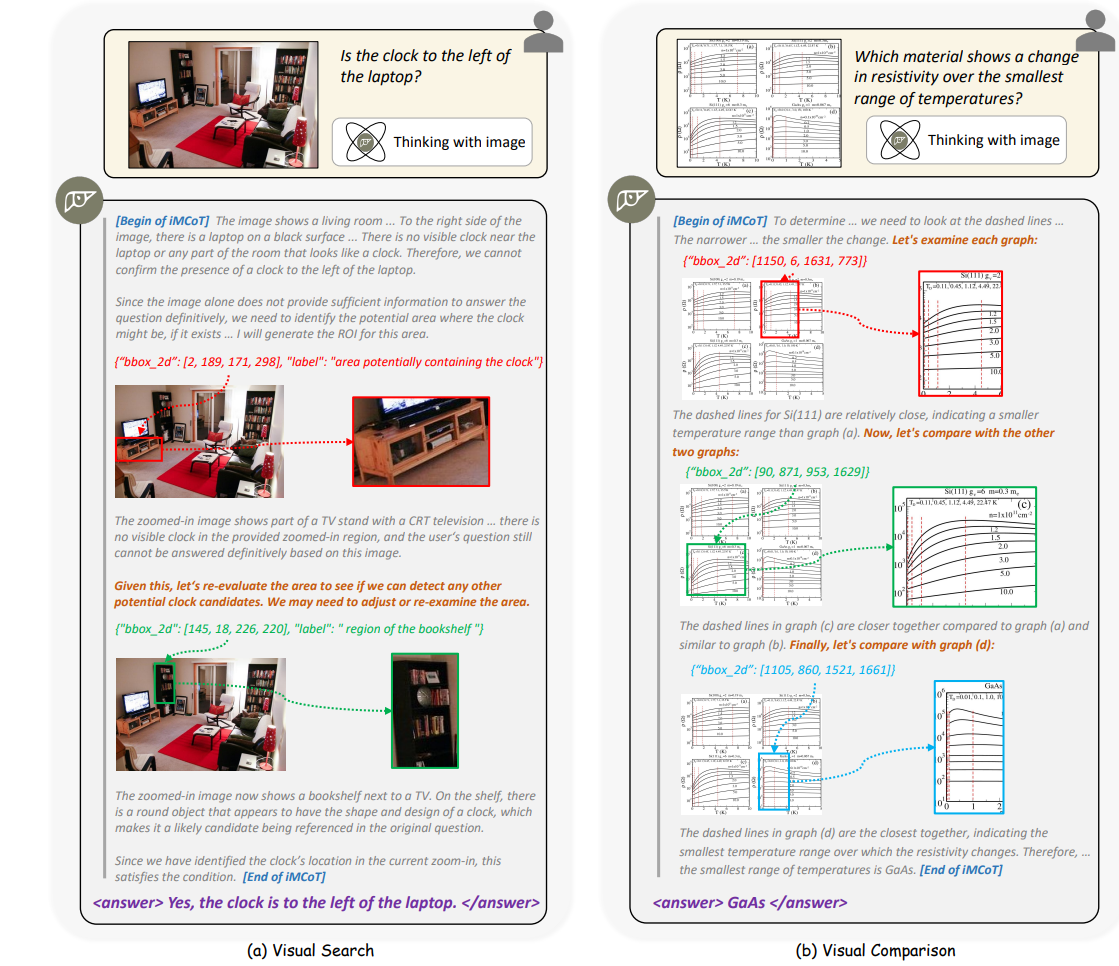
OpenAI O1 / O3 系列
OpenAI 在 GPT‑4 之后推出 o1 系列[4],算是第一次验证了Test Time Scaling和推理能力的关系。更进一步的 O3 模型在 demo 中展示了新的模式:除了“会看图”理解,还会“用图思考”。推理过程中模型可以:
- 主动定位相关区域(放大公式、框选局部结构、旋转视角);
- 将局部视觉观察嵌入后续思维链进行推理; O3 在视觉推理基准 V⋆Bench 上达到 95.7% 的成绩,也算是验证“显式把视觉纳入思维链”是可以提升推理能力的研究方向。
DeepEyes
DeepEyes[6] 应该是第一个开源再现“thinking with images”能力的项目。它不依赖额外人工 SFT,而是直接用 RL 激活模型的视觉逐步聚焦行为。模型可以按照:生成初始思维链 → 判断是否缺细节 → 自主调用“放大 / 裁剪”工具 → 将裁剪区域重新编码 → 继续推演。循环执行形成类似 O3 的效果,并且得到了验证:
- 7B 规模在细粒度视觉推理任务上击败更大(32B)模型。
- 在与图片相关的数据集上数学与抽象推理同步提升,显示视觉思维链对语言主干能力存在正迁移。
Pixel-Reasoner
类似的研究还有 Pixel-Reasoner[7],研究把视觉操作本身(ZoomIn / 选帧 / 划区域等)显式当作“推理 token”,把原本文本空间的推理延伸到像素空间。训练分两阶段:
- 模板化合成数据指令微调 —— 教会模型视觉操作语法与调用格式;
- 好奇心驱动 RL —— 通过探索奖励克服“只靠语言偷懒”惯性,促使其在必要时调用视觉函数。 结果:7B 模型在 V⋆Bench (84%)、TallyQA-Complex (74%)、InfographicsVQA (84%) 等指标上达到 / 逼近开源最优水平,凸显“显式视觉操作”对细节敏感推理的价值。
小结
从这些 Vision CoT 的研究我们看到,把视觉嵌入到思维链中,似乎是可以提升模型的推理能力的,至少模型在图文数据集上的能力都得到了显著提升。那么为什么很多人仍然认为只有语言才是推理的核心呢?带着这个问题,我们进入下一章节。
视觉调用链:再看几眼,还是“用图思考”?
刚刚讨论了很多很多thinking with images的例子,看上去主要的方式还是通过对图像进行不同的操作,来验证推理的流程。那么这种能力是真正的用图思考么? 这里我们回顾一个纯文本CoT的项目作为对比:
以 R1-V[9] 项目为例,文章在 VLM 上运行了 RLVR(不过推理过程仅仅使用文字),也得到了很大的提升:
- R1-V:仅 2B 级模型 + 约 100 步 RL 训练,在 OOD 视觉计数任务上超越未 RL 的 72B 模型;
- 核心收益来自:让小模型学会逐步核对视觉线索 → 减少一次性“胡猜” → 在分布偏移场景下保持鲁棒。
一个R1-V期望的效果的例子(项目中SFT部分用来蒸馏的数据):
R1-Distilled Answer:
Okay, let’s look at the problem. The user is asking about the number of purple metallic balls in the described scene. First, I need to go through each object in the image to check their attributes. The objects listed are: 1. A large blue rubber sphere. 2. A small brown rubber cube. 3. A small green metal cylinder. 4. A large blue metal cube. Each object has details about color, material, shape, rotation, coordinates, etc. The key attributes here are color (“purple”), material (“metallic”), and shape (“ball” or sphere). Looking at each object: - The first is a sphere, which is a ball shape, but it’s blue and made of rubber. So color and material don’t match. - The second is a cube, so shape doesn’t match. Also, it’s brown and rubber. - Third is a cylinder, so shape is not a ball. It’s green and metal, so color is wrong. - Fourth is a cube again, shape not matching. It’s blue and metal, so color is incorrect. None of the objects are purple metallic balls. There’s a blue rubber sphere and a blue metal cube, but no purple metallic spheres. The answer should be zero since none fit all three criteria.
这个实验证明:当我们可以把“多步思考”推广到视觉的有效性,模型可以通过文本的方式,反复聚焦局部、换角度、验证计数、尝试多条视觉解释分支,再进行语言归纳输出。
通过对这个项目的思路,我们发现其实即使只使用文本作为CoT过程,模型推理的思路和thinking with images也没有太大的不同。即使仅使用文本,模型也在推理过程中逐步核对视觉线索,从而对推理能力带来帮助。那么看上去在thinking with images的方法中,图片带来的并不是新的推理能力,而是更有效的信息。而对信息的选择能力,还是通过语言进行的(“First, I need to go through each object in the image to check their attributes.”)。
如开头所说,通常我们可以把模型的能力分为理解、推理、生成三种。那么当我们集中在模型推理能力时,问题就变成:视觉到底是提升了推理能力,还是只是作为一个新的信息渠道(或者说工具)给模型提供了更多的信息?
看一下之前分析过的一些例子:
自适应视觉调用
Pixel-Reasoner 显示:初始阶段模型倾向忽略新视觉操作——语言路径是一条低阻力捷径。好奇心奖励迫使它探索视觉调用空间;策略成熟后,行为由“盲目多放大”转向“目标化少放大”,视觉操作次数下降但有效信息密度提升,说明视觉步骤被内化为高价值资源。
分步求解与跨时间推理
O3、DeepEyes、Kimi-VL 等研究也证明:长时间链 + 中间验证 → 更稳健的整体理解。视觉 test-time scaling 带来的效果似乎还是类似于:允许“再看几眼 + 再算几轮”,提升答案置信度与纠错概率。
小结
分析下来,现在主流的“视觉推理”其实还是类似这样的范式:优化图片的注意力(可以使用工具,比如生成 HTML[8]、使用 resize / crop 操作等[6])→ 补充新信息(矫正注意力) → 优化推理思维链,本质是信息补全,不是真正的“用图思考”,而且可以通过提供图片剪裁、放大等工具来进一步提升模型对视觉信息的理解。
Benchmark:视觉对推理的两面性
大致分析了视觉起到的作用后,可以再从这个角度分析一下:视觉信息的引入是否只会带来提升?是不是还会引入其他的问题?这似乎取决于:模型是否学会“有条件、选择性”地把视觉纳入推理主干。
实际上前面提到的论文里也都有一些相关的讨论:
正向:提供新增证据面
典型增益来源:
- 还原模糊或格式不规则的符号(手写算式、标注、路牌文字);
- 弥补题干省略的结构/空间/数量信息(图表、拓扑、布局关系);
- 给出可核对的外部世界细节(位置、颜色、相对关系)。 DeepEyes 在局部裁剪后解决文本模型无法回答的细节问题;O1 开启视觉后科学问答提升;这些都说明视觉是“信息补全器”。
负向:制造噪声与注意力稀释
常见失败模式:
- Bypassing:模型直接按语言惯性输出答案,视觉输入被旁路;
- Forced Attention:被迫描述图片却抓不到关键细节,反增幻觉;
- Gradient Noise:噪声图文对使得多步 CoT 每步有效信息稀释,梯度扰动放大;
- Shortcut Overfitting:依赖统计先验跳步作答,反而在 OOD / 细节题失效。
缓解策略
针对这些问题的一些解决方案。
- 数据筛选:删“过易/过难/无视觉增益”样本(DeepEyes);
- 工具奖励:正确 + 合理调用工具才给额外分(R1-V);
- 行为激励:好奇心 / 探索奖励鼓励早期广撒网,后期渐收敛(Pixel-Reasoner);
- 显式动作 API:把视觉调用结构化,降低黑箱融合混淆;
- 失败链过滤:去除绕开视觉的思维轨迹,提升监督信号纯度。
小结
既然我们把视觉作为一种新的信息,那么似乎很自然,我们的研究方向会往降低干扰、教会模型在正确的时机使用正确的数据发展。因此我们在这里做了一些简单的讨论,而很多研究的重点也从“堆多模态数据”转向“学何时、如何、高效地看”。
视觉与智能的关系
这一部分想讨论两个问题:
- 为什么“视觉强 + 语言强” ≠ “推理显著提升”?
- 目前视觉在大模型中到底是“协同认知模块”还是“外接工具层”?
能力独立性:理解、 生成、推理不能互补
考虑一下理解、推理、生成三种能力,对于文本任务来说它们似乎是天然互惠的,但是对于图像数据这些能力目前似乎还是一个非常割裂的状态。 比如早期实践里(张祥雨回顾)即使加入海量图文混排预训练,图像理解与生成也只是两个“平行模块”:一种能力的增强并不带来另一种能力的提升。而蚂蚁 Ming-Omni 等模型也采用“先感知 / 再生成”双阶段[10]训练模式,在生成训练阶段会冻结主干来避免生成训练污染推理链,进一步说明这二者尚未形成内部循环增益。
追究其原因,可能包括:
- 语言与视觉的冲突:视觉稠密、局部性强;语言稀疏、语义压缩,两者共享同一优化节奏易冲突。
- 导致视觉 embedding 的表示能力不足:跨模态对齐多停留在 embedding / 投影层,没有在策略(如何拆解 / 规划)层深度共享。
- 预训练数据中角色分工固化:语言承担抽象组织、验证、反思;视觉更多提供原材料。于是“能生成图” ≠ “内部推理图像化”。
结论:当前视觉的理解、生成和推理能力更像一些协作插件,我们目前训练大模型的方式和数据不足以支持图片数据对推理能力的提升。
工具属性:视觉仍主要扮演可调用外设
DeepEyes、Pixel-Reasoner 等工作把“看图”拆成显式动作(裁剪 / 放大 / 选帧 / 重定位),本质是把视觉转译为一组离散工具 token。这种模式是一种白盒的方法:
- 可控:何时调用、调用几次是显式决策,而非黑箱融合;
- 可解释:推理轨迹里留有“检视—确认”痕迹,利于审计;
- 可优化:奖励函数直接作用在“是否调用 + 是否有效”上(RL 信号更干净)。
但是这种白盒的方法也表明,视觉还是只是作为“取证阶段”的插件,模型的核心推理能力还是需要通过语言产生。我们还做不到让视觉参与“假设生成—反事实构造—策略分支”。现有闭环多数是“语言提出疑问 → 视觉取证 → 语言归纳”,链条方向单向,尚未形成“视觉驱动新假设”的双向循环。
小结
回顾视觉与智能的当前关系,视觉似乎还是只能作为辅助来帮助 LLM 进行推理,但视觉本身并不能帮助模型能力走到下一个阶段。相反,因为模型需要分配参数来帮助自己理解图像,那么很自然就可以得出,多模态在非图文数据下,能不降低模型能力就算成功了。
其他一些研究和人的看法
其他研究
我们前面一直在说没有“用图思考”,那什么才是真正的用图思考?其实除了上面的主线外,也有一些这方面更“激进”的探索,试图直接在视觉域中产生与执行推理,尽量减少甚至摆脱语言的中介,从而验证图像产生智能的能力。比较有代表性的文章如下:
-
像是 Thinking with Generated Images [12] 让模型在推理过程中主动生成中间图像作为“视觉化的思维步骤”,并在图文之间往返验证与修正,从而原生地跨模态思考;与传统“先看图再用文字想”的范式不同,这一方法把“用图像来想”纳入了推理主回路。不过这种方式看上去还是把图像生成当作一种中间草稿能力,并非推理链路本身。
-
更进一步的,Visual Planning: Let’s Think Only with Images [11] 则提出完全基于图像序列(如下图)来进行规划与推理:模型以一连串“中间图像状态”表达和推进思考,通过强化学习在视觉导航等任务中取得相对语言式规划更优的效果,论证了“语言并非所有推理任务的最优载体”,尤其在空间与几何场景中更是如此。该工作明确主张“只用图像来想”。
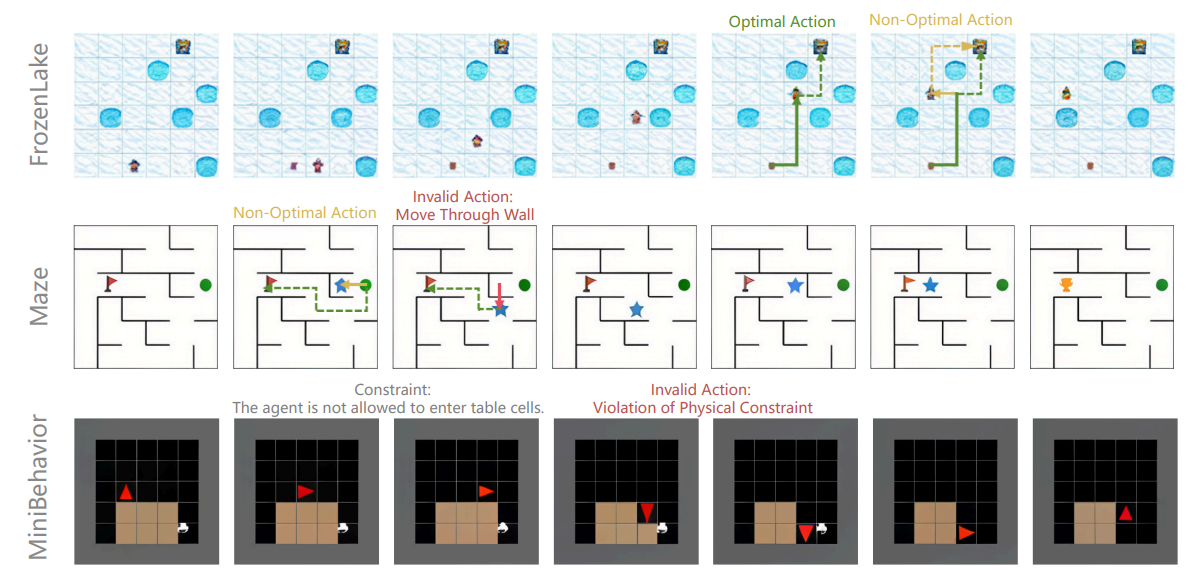
总的来说,这些研究希望让视觉更进一步参与到推理的逻辑中,但是因为数据、任务等限制,这些能力还是难以被应用在大规模 scaling 的场景。
最后补一句个人看法
个人感觉,在目前的方案中,图片确实不能用来提升推理能力,而只能作为一种特殊的工具进行辅助。想要达到真正通过图像等多模态数据提升推理能力这个目标,我们还是需要有合适的任务/数据能完成视觉等模态信息对“理解、生成、推理”一体化,然后才能通过 scaling law 进行智能的扩展。也许在 “the Era of Experience” 的时代,具身智能通过与现实世界真实的交互所引入的新任务和数据,可以解决这个问题吧。
参考文献
[1] 和杨植麟时隔1年的对话:K2、Agentic LLM、缸中之脑和“站在无限的开端” https://www.xiaoyuzhoufm.com/episode/68ae86d18ce45d46d49c4d50
[2] 对OpenAI姚顺雨3小时访谈:6年Agent研究、人与系统、吞噬的边界、既单极又多元的世界 https://www.xiaoyuzhoufm.com/episode/68c29ca12c82c9dccadba127
[3] 和张祥雨聊,多模态研究的挣扎史和未来两年的2个“GPT-4时刻” https://www.xiaoyuzhoufm.com/episode/683d2ceb38dcc57c641a7d0f
[4] OpenAI o1 System Card - arXiv https://arxiv.org/abs/2412.16720
[5] Thinking with images https://openai.com/index/thinking-with-images/
[6] DeepEyes: Incentivizing “Thinking with Images” via Reinforcement Learning https://arxiv.org/abs/2505.14362
[7] Pixel Reasoner: Incentivizing Pixel-Space Reasoning with Curiosity-Driven Reinforcement Learning https://arxiv.org/abs/2505.15966v2
[8] Self-Imagine: Effective Unimodal Reasoning with Multimodal Models using Self-Imagination https://arxiv.org/abs/2401.08025v2
[9] R1-V: Reinforcing Super Generalization Ability in Vision Language Models with Less Than $3 https://github.com/StarsfieldAI/R1-V
[10] Ming-Omni: A Unified Multimodal Model for Perception and Generation https://arxiv.org/abs/2506.09344
[11] Visual Planning: Let’s Think Only with Images https://arxiv.org/abs/2505.11409
[12] Thinking with Generated Images https://arxiv.org/abs/2505.22525
Last modified on 2025-09-15