上一篇文章我们聊了一下Ray与LLM强化学习框架设计,探讨了其架构的演进,但是没有提到为什么框架会往这个方向逐渐演进而不是一开始就使用现在的设计。这里面自然有实践中不断优化的结果,但是也是和整个LLM RL需求的变化密切相关的。
因此,本文会主要讨论一下LLM强化学习中,算法与系统框架是如何相互影响、协同演化的。首先分析两个相对成熟的协同设计案例,然后讨论几个正在不够成熟、但是在笔者看来很有潜力的优化方向。
算法与框架协同演化的典型案例
先讲两个目前已经相对得到了共识的问题:
案例一:推理模型驱动的分离式架构设计
在前一篇文章中提到过,之前的强化学习还是希望尽量on-policy的,因此早期的强化学习系统倾向于采用on-policy算法配合co-located的架构设计。这种选择有其合理性:算法层面,on-policy确实具备样本效率优势;系统层面,在CoT和Test-time Scaling兴起之前,模型输出长度差异相对较小,推理引擎产生的计算空泡还算可控。尽管资源利用率的问题客观存在,但on-policy算法的优势在一定程度上抵消了这种系统层面的低效。
不过,从去年o1发布开始,业界开始重视Test time scaling,加上R1的发布又给推理模型点了一把火,这种范式的改变打破了之前的平衡:模型在推理阶段生成的文本长度显著增加,且不同样本间的长度差异极为悬殊。在这种新的计算模式下,on-policy的算法优势已无法弥补系统资源的巨大浪费——所有并行环境必须等待最长推理任务完成才能进入下一轮迭代,这种同步约束造成了严重的吞吐量瓶颈和大量计算资源闲置。

正是因为这个挑战,业界逐渐开始转向异步RL框架设计。其核心思想是将Generation与Training完全解耦,构建生产者-消费者的流水线架构。以AsyncFlow和AReaL为例:
-
推理引擎(Rollout Workers):持续异步生成新的数据,彼此间无需同步等待。
-
训练引擎(Trainer Workers):训练节点异步地从共享缓冲区获取数据进行模型更新。
这种流式RL设计有效避免了慢速推理任务对整体流程的阻塞,确保所有计算设备维持高利用率,从而实现训练吞吐量的显著提升。这正是算法演进与系统架构优化协同设计的一个典型案例:新的需求需要新的取舍,进一步催生了新的架构。
案例二:MoE架构与训练推理引擎的精度对齐挑战
另一个挑战出现在系统层面,尤其是在使用超大模型或混合专家(MoE)模型时:训练引擎和推理引擎之间的不匹配。
在RL的训练中,通常为了效率,模型的推理(生成)过程可能会在专门的推理引擎上执行(例如使用vLLM),而梯度计算则在训练后端(例如DeepSpeed)上进行。然而,两者在数值精度(如FP16 vs INT8)、算子融合、批处理调度或MoE门控行为上都可能存在差异,进而导致rollout数据和训练计算之间的分布漂移。
实际上,这个问题并不是在MoE中才刚刚出现,以小红书为例,他们在去年的QCon演讲从0到1构建RLHF系统——小红书大模型团队的探索与实践中就提到了对训推一致性的要求,通过自研框架进行对齐。此外还有一些公司会选择使用推理引擎生产数据,然后通过训练引擎再次推理拿到logit进行概率计算。
但是随着MoE的兴起和推理引擎加速技术的不断发展,精度对齐变得越来越困难,比如MoE的路由层引入的不一致可能远高于Dense Model中的精度不一致。同时由于数据的实际采样概率还是由推理引擎决定,以前主要是不同引擎计算的概率不同,但是现在可能连采样出的token都会有巨大的变化,这让通过训练框架再次对齐也更不够用了。
为了解决这一问题,AREAL框架提出了Decoupled PPO算法,采用了一种巧妙的双引擎协同策略:利用推理引擎输出的概率进行重要性采样(因为它反映了真实的数据采样分布),同时使用训练引擎输出的概率来计算置信域(Trust Region),确保训练引擎对模型更新仍在训练引擎原来的有效范围内进行。

类似的,FlashRL 也在他们的blog中提出了一种截断重要性采样的技术TIS,通过对更新进行重新加权,来修正量化推理(用于采样)和全精度模型(用于优化)之间的策略差异。通过这一技术,即使是高度量化的rollout数据(如INT8/FP8)也能被用于训练,而不会损害最终效果。
可以看到,在这个例子里,研究者们通过算法的设计,来弥合了系统设计导致的训练和推理之间的鸿沟。
(可能的)发展趋势:协同设计的新兴挑战与机遇
讲了有共识的,有相对公认的解决方案的案例以后,我们来看一看有些相对不那么得到共识,或者大家意识到但是解决方案还没有完全收敛的方向:
方向一:Agent RL: 样本效率、环境管理与过程奖励
随着Agent RL的发展,强化学习的过程中,LLM需要升级为能够调用工具、API,并与环境持续交互的自主智能体时,新的挑战也随之浮现。
个人认为,根据当前研究趋势,Agent RL主要可归为两类典型范式:
- Sandbox + Browser:通常用来训练通用Agent,在受控沙箱或浏览器环境中进行任务执行与评估;
- MCP + Tooluse:常见于内部或垂直领域,增强模型使用工具集合使用能力。
以实际场景为例,可以更清晰地看到Agent RL所面临的关键难题。
1. 奖励稀疏性与延迟问题
在复杂任务中,类似o1的结果奖励机制效率极低。例如,Anthropic提到Claude Ops 4可在后台连续运行7小时完成软件开发任务,若仅在最终成败时给予奖励信号,这种延迟且稀疏的反馈使得样本的生成变得越加困难,同时单一的结果奖励几乎无法有效指导学习过程。因此,过程级奖励(Process-level Rewards)或者智能体引导机制(Agent Guidance)可能会重新变得重要。
近期工作如Agent-RLVR 框架,在 RL 训练中引入高层指令提示、动态错误反馈等“教学式”奖励信号,显著提升了智能体在复杂编程任务中的成功率。这类方法模拟人类教学过程,通过中间反馈加速策略收敛。
与之相关的,还有对样本效率的提高:一方面需要构建更高效的样本生成流水线,另一方面要探索高质量数据的重用机制以降低采样成本。相关研究也在逐步涌现,如Sample-efficient LLM Optimization with Reset Replay,为解决Agent RL中的样本稀缺问题提供新的思路。
2. 复杂状态表示与管理
Agent 的状态不仅包括对话历史,还涵盖工具调用输出、环境观测、以及内部思维链等多源异构信息。传统 RL 框架难以有效建模此类高维、长序列的状态空间。
为此,新兴研究开始探索情景记忆模块与状态压缩技术。例如,AGILE 框架表明,为智能体配备显式的记忆存储与反思机制,能显著增强其跨步推理能力和长期任务一致性。
3. 环境可观测性与工具可靠性
Agent RL 通常依赖多种外部工具或服务(如代码解释器、搜索 API等),但这些组件可能存在不可用、响应延迟或返回错误等问题。这使得环境状态难以准确观测,增加了训练的不稳定性和调试难度。如何实现对工具调用链的可观测性监控与容错恢复机制,也会成为系统设计中的关键挑战。
新的RL基础设施
为应对上述挑战,RL 基础设施正朝着更高模块化、更强可扩展性的方向发展。个人认为,未来的 Agent RL 框架需具备:
- 一个支持细粒度追踪的分布式训练引擎,以实现全流程可观测;
- 推理引擎支持持续 partial rollout,即分阶段生成轨迹数据,便于中间干预与数据复用;
- 更加高效的离线强化学习与数据重用机制,缓解采样成本高、高质量轨迹稀缺的问题。
只有构建兼具灵活性、可解释性与工程鲁棒性的新型 RL 架构,才能支撑智能体在真实复杂环境中的持续学习与自主进化。
方向二:生成式奖励模型与进一步的分离式架构
在近期的对齐研究中,另一个相对显著的趋势是生成式奖励模型(GRM),比如DeepSeek-GRM。与传统奖励模型仅输出标量分数不同,生成式奖励模型——本质上也是一个大语言模型——能够生成详细的评估文本或推理轨迹来表达其判断,通过test scaling的方式大大提升了奖励模型的鲁棒性。
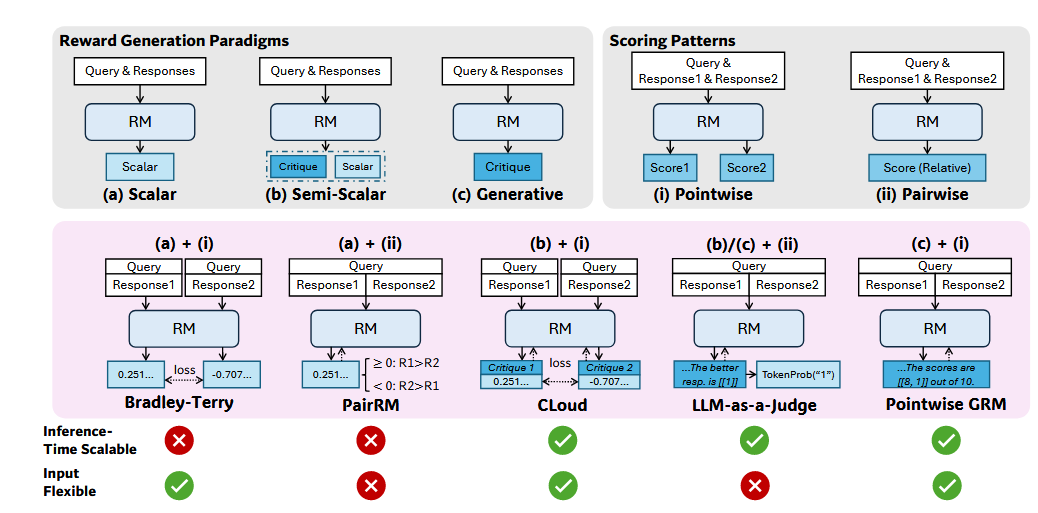
实际上,在几年前OpenAI在Scaling Laws for Reward Model Overoptimization中就强调了scale reward model的重要性,GRM正是这一技术的延伸。
类似于o1/R1放大了Disaggregated架构的重要性,生成式奖励模型的引入会进一步推动RL训练流水线向更加分布式、多模型协同的方向演进。不同于传统的单一策略模型训练模式,新的架构需要支持策略模型、价值模型、奖励模型等多个大型模型的并行交互与动态调度。这对底层框架的资源管理、任务编排以及模型间通信机制提出了更高要求。
可以预见,生成式奖励模型代表了RL与LLM内在推理能力的深度融合,它不仅是算法层面的创新,更是对整个RL基础设施提出的系统性挑战。
写在最后
从技术演进的角度来看,本文讨论的这些案例展现了LLM强化学习领域中算法与系统协同演化的规律。这种演化并非偶然,而是技术发展中系统性约束与算法创新相互作用的必然结果。
成熟案例的启示:异步RL架构与推理时长不确定性的矛盾、MoE模型训推一致性挑战,都体现了一个共同特征——当系统约束成为瓶颈时,算法创新往往会寻找新的理论基础来突破这些限制。Decoupled PPO和截断重要性采样等方法的出现,本质上是将系统工程中的"分治"思想引入算法设计。
新兴趋势的挑战:Agent RL中的环境管理复杂性、生成式奖励模型的多模型协同需求,则预示着未来系统设计将面临更高维度的权衡。过程级奖励机制需要更精细的状态管理,而GRM的引入则要求框架具备更强的多模型编排能力。
协同演化的深层逻辑:这种算法与系统的紧密耦合反映了LLM强化学习的本质特征——它不仅是一个计算问题,更是一个分布式系统工程问题。算法的有效性往往取决于系统能否提供相应的基础设施支撑,而系统的演进方向也会被算法的需求所引导。
从更宏观的视角来看,这种协同演化正在重新定义强化学习系统的边界。传统的单机RL框架设计原则在大规模分布式环境中需要根本性的重新思考。我们未来应该会看到更多系统感知的算法设计,以及更多算法优化的系统架构。
Last modified on 2025-08-14