最近LLM强化学习框架发展特别快,Ray作为被ChatGPT带火的框架,在LLM各个训练阶段中,RL阶段的应用应该是最多的。写篇文章记录一下这块发展的脉络和一些看法。
从Google Pathways说起
讨论Ray和RL系统,得从Google的Pathways系统开始:2021年Google提出了Pathways作为下一代AI架构和分布式ML平台,在相关文献中详细讨论了Single-Controller + MPMD的系统设计。
Single-Controller(单控制器)是指用一个中央协调器来管理整个分布式计算流程的架构模式。在这种设计中,有一个主控制节点负责整个计算图的执行,包括任务分发、资源调度、状态监控等。
Multiple-Controller(多控制器)则是指使用多个分布式控制节点来协同管理计算任务的架构模式。在这种设计中,没有单一的中央协调器,而是由多个控制器节点分别负责不同的子系统或计算子图,通过分布式协调协议来实现全局一致性。
在Ray中的Driver Process就可以被作为一个典型的Single Controller来启动不同的任务程序,而通过torchrun运行的PyTorch DDP分布式计算则是在每个node上各自执行自己的程序则属于典型的Multiple Controller范式。
MPMD(Multiple Program, Multiple Data)是一种分布式计算范式,指在一个计算任务中,不同的节点运行不同的程序来处理不同的数据。这种模式下,各个计算节点执行的代码逻辑可能完全不同,每个节点都有自己特定的任务和职责。
SPMD(Single Program, Multiple Data)则是另一种常见的分布式计算范式,指所有节点运行相同的程序,但处理不同的数据分片。
典型的SPMD任务包括传统的分布式训练,比如PyTorch DDP,每个节点运行相同的程序来处理不同的数据,最多根据rank的值会有一些特别的处理(比如rank=0的节点负责checkpoint)。相比之下,大模型训练包括了流水并行这种更复杂的任务,每个节点组需要运行不同的程序,就更适合用MPMD的方式来实现了。
一般来说,MPMD系统由于包含众多异构组件,各组件间的协调和同步变得相当复杂。为了简化开发复杂度并确保系统执行的一致性,Single-Controller架构成为了自然的选择——通过引入中心化的控制器来统一管理整个分布式计算流程,包括任务调度、状态同步和异常处理等关键环节。
更多的细节就不多说了,有兴趣的话可以去看Oneflow团队当年写的两篇文章,非常深刻:解读谷歌Pathways架构(一):Single-controller与Multi-controller和解读谷歌 Pathways 架构(二):向前一步是 OneFlow。
这与LLM强化学习有什么关系呢?用RL训练LLM本质上是一个多阶段、多节点的复杂分布式任务。典型的RLHF流水线涉及多个不同模型,计算流程分为几个关键阶段:
- 生成阶段:当前策略模型(LLM)对一批输入提示生成响应文本
- 评估阶段:这些响应由奖励模型评分,或通过人类/自动化偏好模型进行比较评估
- 训练阶段:基于获得的奖励信号更新策略模型权重(可能还包括价值函数或评论家网络的更新)
这些阶段之间存在明确的数据依赖关系——训练更新必须依赖于生成的样本及其对应的奖励分数。在朴素的实现中,这些阶段只能串行执行,引入大量上下文切换的同时还要求所有的模型使用相同数量的GPU进行计算,计算效率是相当低下的。因此正如Pathways架构所启发的那样,我们希望在保证正确性的前提下,通过良好的系统设计,尽可能地重叠和并行化这些工作阶段,以最大化计算资源的利用效率。
直接说有点抽象,可以看下面这个从HybridFlow里截的表格,我截了两个最早的RLHF系统,左边的DeepSpeed-Chat实现了SPMD的串行方式,而右边的OpenRLHF则是典型的MPMD系统。
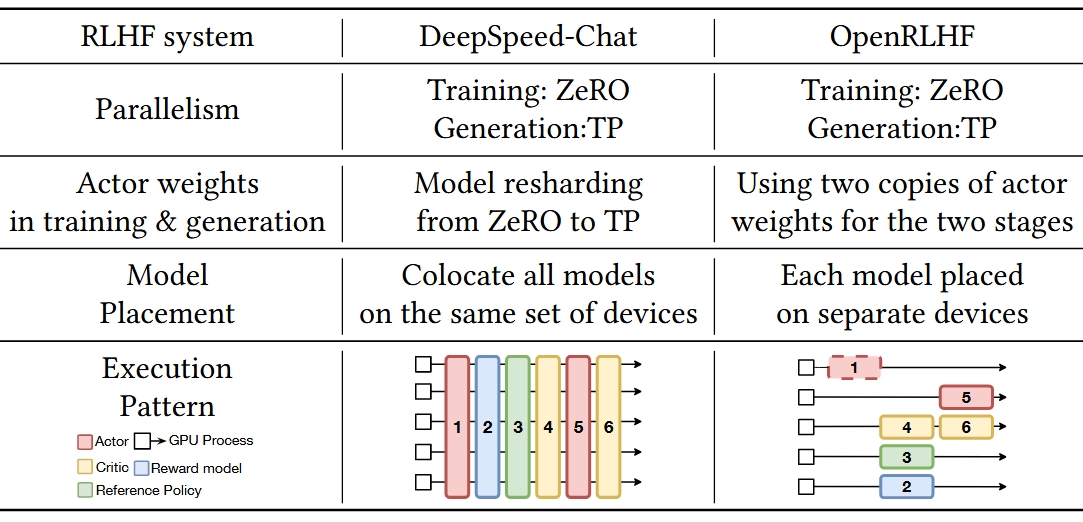
Ray与LLM强化学习框架
其实从前面的内容可以看出来,Ray的设计很适合用来开发Single-Controller + MPMD的程序,也就自然适合LLM强化学习的场景了。
实际上,社区也确实基于Ray开发了大量的强化学习框架,目前主要的设计包括两种:Colocated架构和Disaggregated架构。粗略地说,Colocated架构意味着把生成阶段和训练阶段放在同样的节点上运行;而Disaggregated架构则把它们放在不同的节点上:
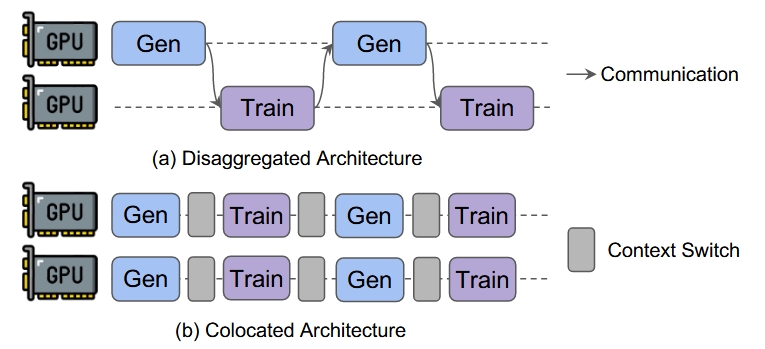
一看这个图,我们会发现Disaggregated Architecture中存在大量的计算bubble,甚至可能比不上之前SPMD模式!这也是为什么很多框架如OpenRLHF、Nemo-aligner、VeRL都是按照Colocated架构来设计的。
需要注意的是,图里的Train和Gen代表的是RLHF的不同阶段,每个阶段内每个GPU可能在运行不同任务,因此整个过程仍然是MPMD的。
以经典的PPO算法为例,整个Train的阶段包括Actor Model(on training Framework)/Reference Model/Reward Model/Critic Model四个模型,Gen阶段包括Actor Model(on inference framework)一个模型,以OpenRLHF为例:

可以看到这里Actor Model会在Deepspeed和vLLM两个引擎间进行切换,因为实际算法需要保存的模型共有5个。
Colocated RL框架 (解法和问题)
接下来继续看这个基于Ray的框架:OpenRLHF使用Ray启动和协调组件,但使用Ray的Placement group实现了Colocated架构,在每个节点上在rollout和训练任务之间分割GPU资源。例如,在给定节点上,框架可能将每个GPU的0.75分配给训练actor,0.25分配给生成actor,这样有效地让一个训练进程和一个生成进程"共享"每个GPU而不互相干扰。
很容易从前面的图看出来,Colocated框架中的资源共享是一个主要的优势,通过设计合适的分组方式,我们可以减少GPU的空闲时间,减少模型offload的频率,同时尽量并行化不同节点的执行,从而最大化提升资源利用效率。
然而,随着模型大小和集群大小的增长,Colocated框架也显示出了自己的局限性:
-
第一个关键问题是StreamRL中提到的资源耦合。虽然Colocated框架比起SPMD的程序提升了计算任务的并行性,并通过分组来允许每组model使用不同的资源,但是这并不能完全消除共享设备带来的问题:因为生成和训练同时共享相同设备,我们不能独立扩展或为每个阶段定制资源。同时训练任务(计算密集)和生成任务(IO密集)的瓶颈并不相同,这不利于GPU资源的利用。
-
另一个问题是,LLM生成的文本长度是不固定的,尤其随着thinking model的大火,生成任务中不同组的模型生成结果的时间可能差异很大。比如我们有32块GPU,每4块GPU为一组进行生成,如果其中一组生成任务过长,会导致其他28块GPU空等造成资源浪费。
总的来说,Colocated框架通过精细的资源管理实现了较高的GPU利用率,相对成熟和稳定,确实许多后续框架都借鉴了类似的设计思路。但是,正如前面提到的资源耦合问题,这种架构在可扩展性方面仍有局限。这也为下一代RL框架的发展指明了方向:能否通过打破严格的串行约束,让生成和训练阶段真正独立地并行执行?
On-Policy和Off-Policy
本文的重点是Ray和LLM RL的框架设计,因此不会在这一部分内容做过多阐述,大概而言:
-
On-Policy: 严格要求使用当前最新策略生成的数据进行训练。在RLHF中,这意味着每次训练迭代都必须等待当前actor模型完成新一轮的文本生成,然后立即使用这些"新鲜"的样本来更新模型权重。这种方式能保证训练数据与当前策略的完全一致性,但代价是强制的同步等待,导致前面提到的大量计算bubble。
-
OffPolicy: 允许使用稍微"陈旧"的策略生成的数据进行训练。在实际系统中,这意味着训练阶段可以使用来自之前几个迭代版本的actor模型生成的样本,而不必严格等待当前版本的生成完成。虽然引入了一定的策略陈旧性(policy staleness),但这种设计允许生成和训练阶段真正并行化,大幅提升系统吞吐量。
On-Policy算法正是前文中Disaggregated Architecture存在大量计算空泡的根本原因:训练阶段只能使用最新策略模型生成的样本,这就强制要求生成步骤必须在训练步骤完成后才能开始下一轮迭代。
从理论角度分析,On-Policy的样本效率确实优于Off-Policy,这主要源于其能够保证训练数据与当前策略分布的完全一致性。在LLM强化学习场景中,策略陈旧性(policy staleness)会引入分布偏移问题——生成数据的策略分布与当前训练策略产生偏差,这种不匹配可能降低训练样本的有效性,并对模型收敛的稳定性和效率产生负面影响。
不过在RL的工业实践中,这种理论差异往往被系统吞吐量的大幅提升所抵消。现代LLM RL系统通过以下几种方式来缓解策略陈旧性的影响:增加Experience Buffer的容量、优化batch sampling策略、以及采用更频繁的模型同步机制。实际部署中,有团队发现通过合理的超参数调整(如学习率衰减、梯度裁剪),Off-Policy系统在保持训练稳定性的同时,能够获得成倍的训练吞吐量提升。这种工程权衡也推动了RLHF向多轮迭代和DPO向Iterative DPO等更适合并行化的算法变种演进。
Disaggregated架构 (从off-policy到Streaming RL)
自然地,业界开始探索在LLM强化学习中采用Off-Policy算法的可能性。ASYNCHRONOUS RLHF的研究为这一方向提供了积极的信号,该研究表明适度的策略陈旧性是可以接受的,并且不会显著影响训练效果。这一重要发现随后在StreamRL的工作中得到了进一步的验证和扩展。 类似的,Meta也在LlamaRL中提出了下面的计算流,我们得到了新的流式的Disaggregated架构:
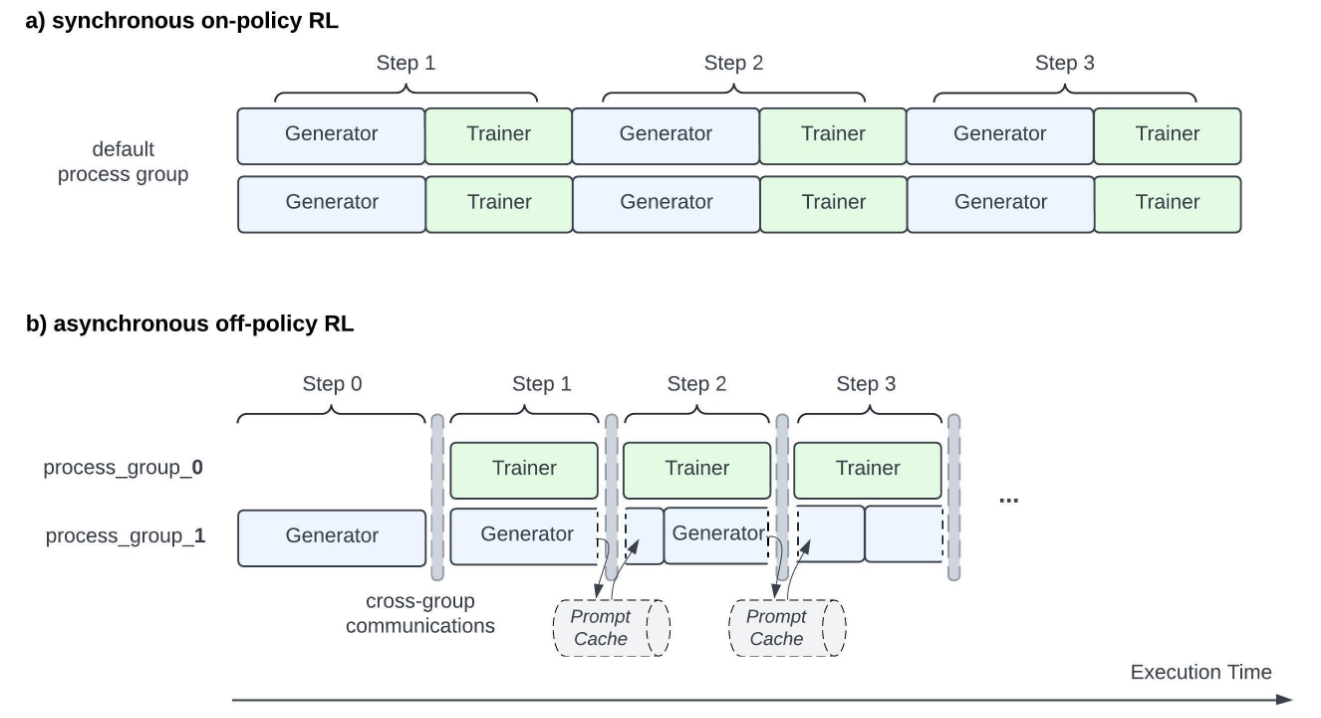
因此,我们观察到,最新的LLM强化学习系统正在移向Disaggregated架构 + Off-Policy的实现,这与MPMD范式一致。想法是将生成和训练阶段分离为不同的服务,它们并发在不同的GPU资源池上运行。我们有,比如说,一个专门用于生成新rollout的GPU资源池和另一个专门用于训练任务的资源池。两个任务在不同的GPU资源上并行操作,样本不断从生成端持续流向训练端。
相比传统的Colocated架构,Disaggregated架构能够真正实现异构资源的独立扩展。举个例子,如果发现生成阶段成为瓶颈(比如复杂推理任务需要更长的生成时间),我们可以单独为生成服务增加更多GPU,而不影响训练集群的配置。相反,如果奖励模型计算或PPO更新成为瓶颈,我们可以针对性地扩展训练侧的资源。这种弹性伸缩的能力在云环境和多租户场景中特别有价值。
通过接受一点陈旧策略的数据,流式框架大大改善了资源利用率。不需要所有GPU在迭代之间同步暂停;相反,生成和训练都可以达到稳定的吞吐量。StreamRL的设计明确解决了困扰同步设计的流水线"空泡"(空闲间隙)和落后任务的长尾。它们实现了完全异步流水线,其中权重更新、生成和训练尽可能重叠。此外,流式框架通常引入弹性优势:可以独立扩展生成服务和训练器服务。例如,如果生成长序列是慢的部分,系统可以为流生成服务分配更多GPU而不增加训练器GPU。或者相反,如果发现奖励模型评分是瓶颈,就扩展那个。这种解耦在多租户或云环境中很强大。
更进一步,为了更好的对训练集群和推理集群进行协调,我们可以引入通过某种数据缓冲区或队列连接来作为两个集群的交互点。这种设计可以实现生成和训练的近乎完美重叠,从而消除流水线中的大部分空闲时间。这里的一个例子是AsyncFlow,这个框架基于TransferQueue来传输数据,并控制训练的执行。
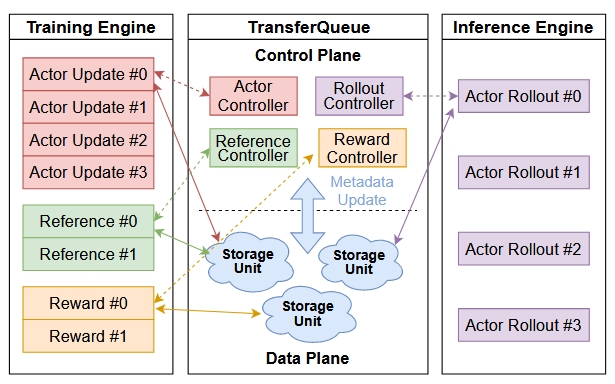
总之,流式RL框架将RL循环解耦为独立组件并利用异步执行来提升吞吐量。它们通过避免资源耦合并允许更细粒度的可扩展性来解决协同定位的缺点。成本是增加的系统复杂性和需要处理离线策略训练——但通过仔细设计(如AsyncFlow、StreamRL等),这些问题是可管理的。
无Ray的RL?
随着LLM强化学习框架的不断演进,似乎有了一个新的趋势:框架对Ray的依赖正在逐渐减少。回顾一下,Ray最初是这些框架快速原型化的理想选择——它能够轻松处理集群配置、进程启动,并提供简洁的远程函数调用和Actor类API。事实上,像OpenRLHF这样的早期项目,中期的VeRL,以及新的Slime和AsyncFlow,都将Ray作为关键的"胶水层"来协调复杂的训练循环。
然而,随着这些系统在生产环境中的大规模部署,Ray的一些固有限制开始显现:
Ray的技术挑战
-
调试复杂性是Ray面临的首要问题。当某个远程Worker深层出现异常时,你往往只能收到一个经过序列化传输的模糊错误信息,很难追踪问题的真正根源。
-
通信开销同样是Ray架构中的一个关键瓶颈。Ray的核心设计依赖Python对象序列化和gRPC通信,这在RLHF场景下面临巨大压力。想象一下,每个experience batch可能包含数万个token的生成文本、完整的logits分布、以及各种奖励和价值函数的输出——这些数据的体积是相当可观的。当这样的大负载需要在生成阶段和训练阶段之间频繁传输时,序列化开销就变得不可忽视了。
虽然Ray社区在通过各种优化手段(如Ray Flow Insight、Compiled Graph和GPU Objects等)尝试缓解这些问题,但目前这些技术并不成熟也不够好用。
缓冲区驱动的无Ray架构趋势
鉴于这些问题,我们已经在社区看到了很多关于无Ray设计的讨论。Meta的LlamaRL完全建立在原生PyTorch上并在405B的模型上做了验证。其他的框架也会有一些关于去Ray化的讨论,比如VeRL。
那么这个是否可行呢?仔细想想RL框架的发展趋势,新的Streaming based RL框架的核心概念数据缓冲区——本质上是一个专用模块,它保存当前rollout集合并将它们提供给训练工作器。我们可以将其视为经验的消息队列或共享内存。框架在生成任务中不断将数据放入缓冲区,并在训练任务中不断从缓冲区拉取数据进行消费。两个阶段的解耦程度已经非常高了,我们似乎并不需要一个复杂的调度层来管理所有的任务。
不过,完全抛弃Ray也不是没有成本的。有些框架还是选择留着Ray,主要是因为它在一些地方确实挺好用的:集群管理、进程启动、故障恢复和资源调度。拿字节跳动的HybridFlow团队来说,他们当时也想过用PyTorch原生的TorchRPC来替换Ray,而且确实也跑起来了。但真正部署的时候,他们发现TorchRPC的维护并不是很积极,还会有一些奇怪的边界情况问题:虽然通过精心的工程设计,我们可以得到更好的性能,但Ray在构建稳定的分布式应用时确实能省不少开发和维护的功夫。
此外,我觉得另一个问题是训练的规模,随着后训练算力的投入,Ray的核心作用也许会从控制流编排转向容错和动态的资源分配管理:RL比起预训练要灵活得多,我们在预训练中都有通过Ray来优化训练稳定性的例子(虽然用得不多),那么在RL中这个作用应该会变得愈加明显。不过可惜的是这种只有头部公司才玩得起了。
写在最后
从技术演进的角度来看,LLM强化学习框架在过去一年多的发展轨迹清晰地展现了分布式系统设计的经典权衡。
早期的Colocated架构通过资源共享实现了较高的GPU利用率,但随着模型规模和集群规模的增长,资源耦合问题逐渐凸显。Streaming RL的出现标志着系统设计思路的根本性转变——通过系统和算法的co-design,从on-policy策略向off-policy策略迁移,通过接受有限的策略陈旧性来换取更好的可扩展性和资源利用效率。
Ray作为这一代框架的重要基础设施,在快速原型开发和集群管理方面发挥了关键作用。然而,随着系统复杂度的提升和性能要求的提高,其在调试复杂性和通信开销方面的局限性也日益明显。这促使社区开始探索更加专门化的解决方案,包括基于原生PyTorch的实现和混合架构设计。
从系统架构的发展趋势来看,未来的LLM强化学习框架可能会继续朝着更细粒度的解耦和专门化方向发展。核心计算组件将更多地依赖高效的原生实现,而集群管理和容错机制则可能继续依托成熟的分布式框架。这种分层设计既能满足性能要求,又能保持系统的可维护性。
值得注意的是,这个领域的快速迭代反映了LLM训练工程化的不断成熟。随着模型规模和训练复杂度的持续增长,我们预期会看到更多针对特定场景优化的专门化框架,以及更加标准化的系统接口和协议。
Last modified on 2025-07-27