准备对DeepSeek的开源项目整理一些文档,也顺便强化一下记忆,先从FlashMLA开始。
FlashMLA是DeepSeek开源的MLA算子实现,这个实现主要给inference decoding用的,Training和prefill应该是另外一个算子。
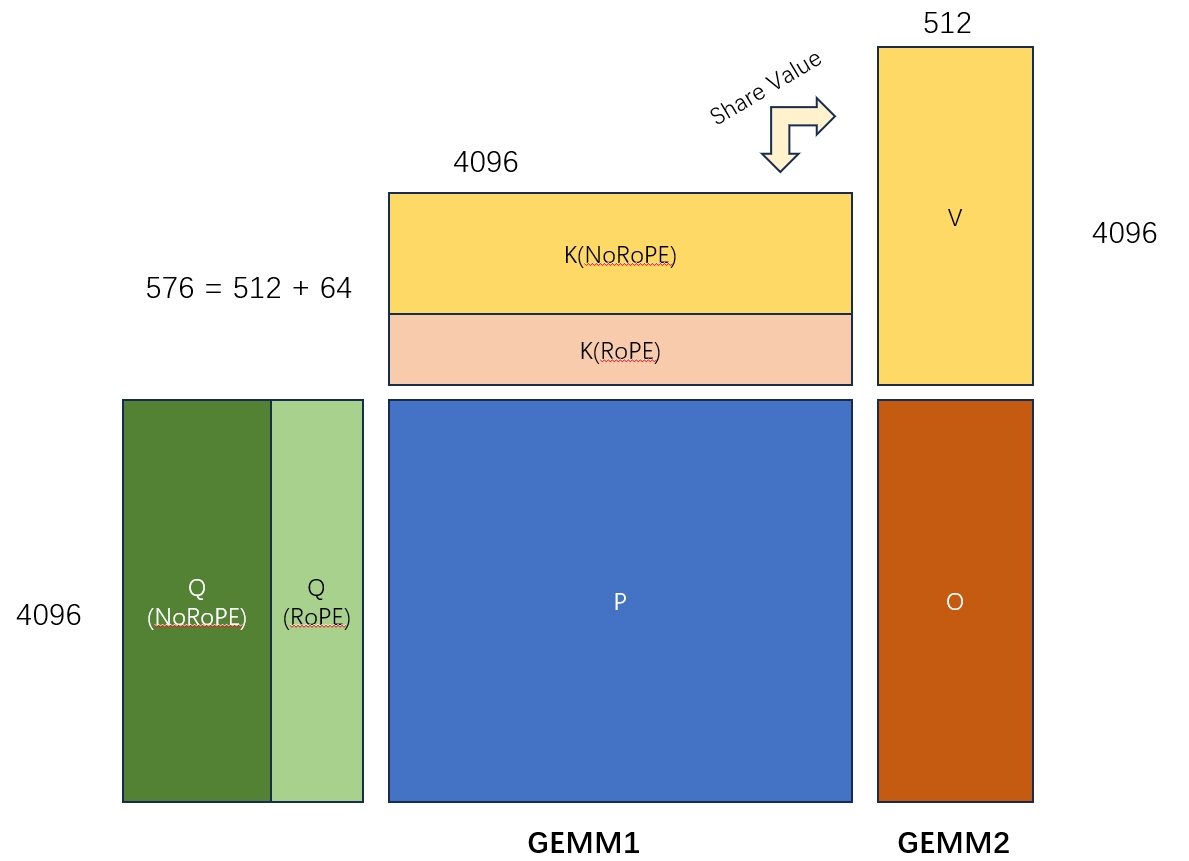
先拿下面的图表示一下MLA算子是在计算一个什么东西,这篇文章就不讲具体的推导了,反正这个算子大概就是下面的2个GEMM算子的融合。需要注意的是:
- 这里矩阵K和矩阵V的共享一部分参数。
- 图里只画显示了一个Query Head和一对KV Head的计算。在实际计算中还要num_kv_head和batch_size两个维度。
- 两个GEMM中间其实还有一个sotfmax,不过这里可以通过online softmax算法把这块逻辑独立处理分块处理,所以不影响主流程。
Kernel的调用主要分两部分
- 调用
get_mla_metadata来计算一些metadata,用来优化kernel的执行 - 调用
flash_mla_with_kvcache进行计算
在进入调用前,先大概说一下FlashMLA计算的拆分逻辑。这块和FlashDecoding很像,并没有要求一个thread-block必须处理一个完整的sequence,而是通过一个负载均衡算法,把所有的sequence放到一起,然后拆分成一个个的sequence-block,然后每个thread-block就去处理分配给它的那些block的计算,最后再把这些thread-block的结果用合并,得到正确的输出。
大概是下面这个图的样子:
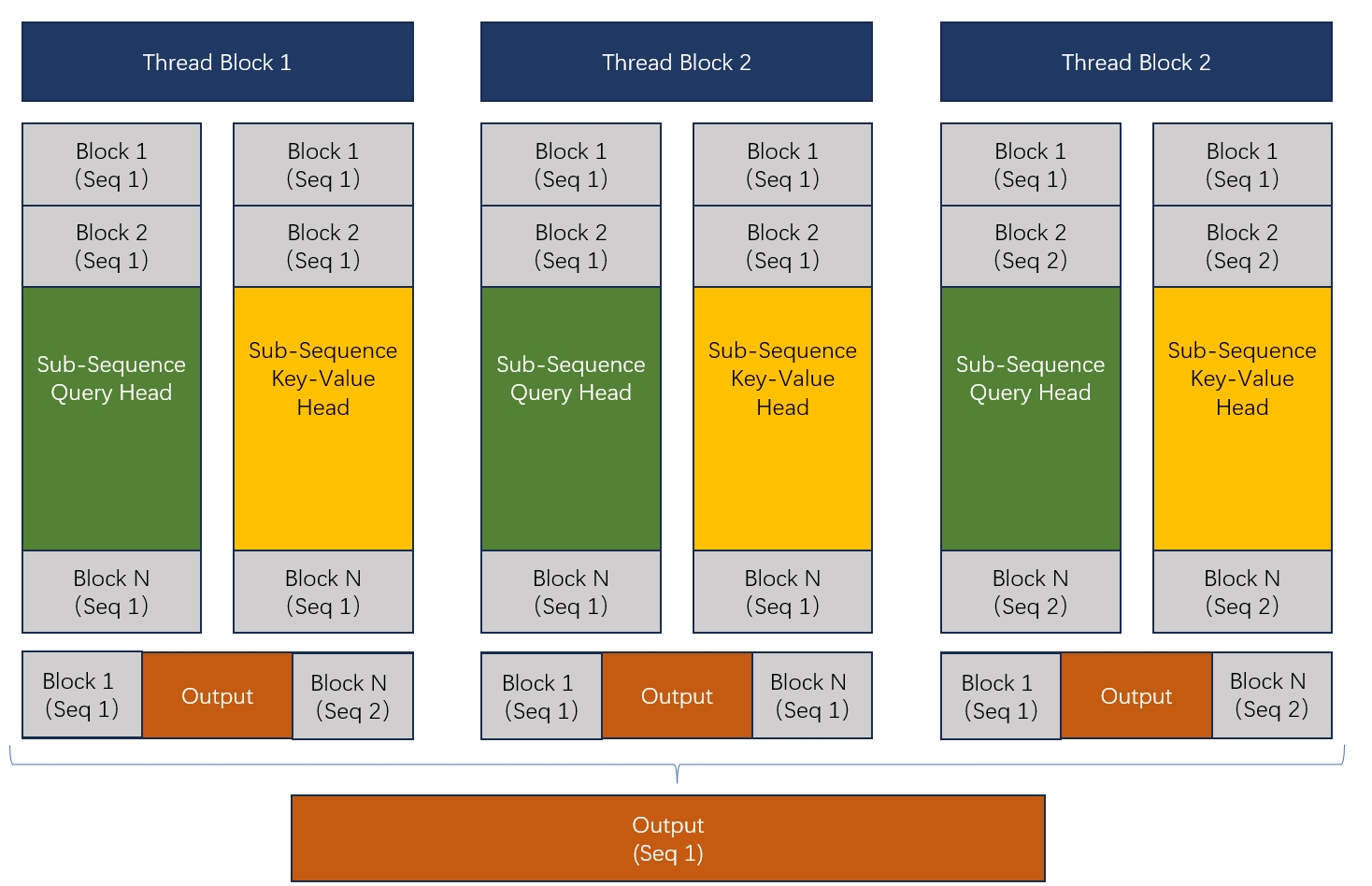
所以为了完成计算,第一步就是决定每个block需要处理哪些sub-sequence,也就是get_mla_metadata要完成的事情。
get_mla_metadata
先看get_mla_metadata具体提供了哪些元数据,我们从repo提供的测试代码入手,考虑最简单的情况(batch_size=128, query_sequence_len=1, mean_key_sequence_len=4096, MTP=1, num_kv_head=1, num_q_head=16, TP=1, hidden_NoRoPE_dim=512, hidden_RoPE_dim=64, varlen=False)。
# cache_seqlens = tensor([4096, 4096, ..., 4096], dtype=torch.int32),
# size=batch_size, value=sequence_len
# s_q=1 (query_sequence_len=1且MTP=1), h_q(num_q_head)=128 (TP=1=128/128) h_kv(num_kv_head)=1
# 基于这些配置,计算mla kernel的metadata
tile_scheduler_metadata, num_splits = get_mla_metadata(cache_seqlens, s_q * h_q // h_kv, h_kv)
因为这里我们是在测试decoding步骤,所以有query_sequence_len=1,可以看到三个入参:
- kv cache的大小
- 类似GQA的Group数量,这个参数表示每个kv head对应多少个query head。
- kv head的数量
get_mla_metadata会根据GPU中SM的数量和要处理的数据的大小,给每个SM分配任务。这个注意get_mla_metadata_kernel的参数为<<<1, 32, 0, stream>>>,因此所有计算会在1个warp中完成。
这里的关键就是具体怎么给每个(每组)SM分配工作的.
首先,每几个SM会一起处理一个kv head和一组query head的计算:
int num_sm_parts = sm_count / num_heads_k / cutlass::ceil_div(num_heads_per_head_k, block_size_m);
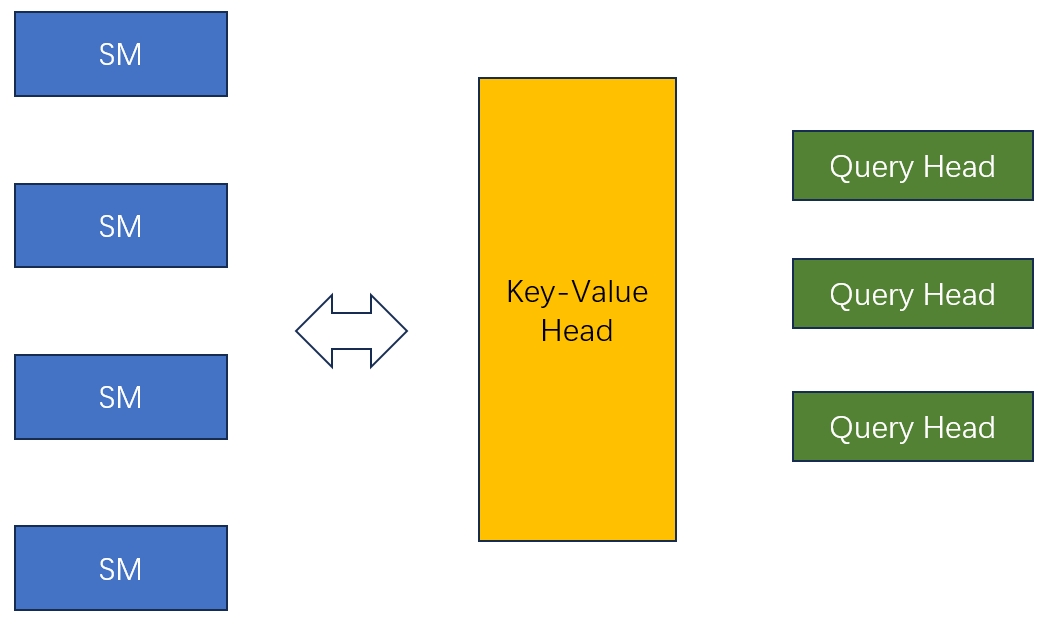
然后,我们计算每组SM需要处理多少个block,然后把block分配到每一个SM,具体任务的分配过程为:
- 根据batch size和
mean_key_sequence_len计算出一共有多少个block。 - 给每个SM分配工作,包括每个SM要处理的tile的索引和位置。
- 记录一下每个sequnce的切分点的位置,用于在计算时把结果正确的合起来才能得到完整的注意力输出。
OK, 这样我们就完成了对任务的划分,接下来进入关键的计算kernel。
flash_mla_with_kvcache
flash_mla_with_kvcache函数内部其实也是由2个子kernel组成的
flash_fwd_splitkv_mla_kernel: 通过for循环的方式,计算每个SM分配到的block的GEMM乘法。flash_fwd_splitkv_mla_combine_kernel: 负责把多个block的计算结果合起来,得到最终的结果。
flash_fwd_splitkv_mla_kernel
先看flash_fwd_splitkv_mla_kernel,这个kernel包括num_m_block * num_query_head * num_sm_parts 个thread-block。其中num_m_block=seqlen_q/block_size_m(64)。
kernel<<<dim3(num_m_block, params.h, params.num_sm_parts), Kernel_traits::kNThreads, smem_size, stream>>>(params);
注意,这里的seqlen_q并不是一开始的1了,实际上它等于num_heads_per_head_k (seqlen_q = seqlen_q_ori * ngroups, 在MTP=1的情况下等于num_heads_per_head_k)
这样我们会发现:num_m_block=cutlass::ceil_div(num_heads_per_head_k, block_size_m);
回忆之前的SM分组公式,有
SM数量 = num_sm_parts * num_heads_k * ceil_div(num_heads_per_head_k, block_size_m)
= num_sm_parts * ceil_div(num_heads_k * num_heads_per_head_k, block_size_m)
= num_sm_parts * ceil_div(num_query_head, block_size_m)
= num_sm_parts * num_m_block
因此SM的数量对应了thread-block的第一维和最后一维。
dim3(num_m_block, params.h, params.num_sm_parts)的这三个维度分别表示:
- 这个thread-block处理哪一个block。
- 这个thread-block应该处理哪的一个query head。
- 这个thread-block在对应的SM Group内的编号。
我们来看每个thread-block会计算什么,我们知道多个thread-block会共同完成分配给一个SM的block的计算。 看代码发现这里其实有2重循环:
- 外层循环会遍历所以分配给这个SM的query block。
- 内层循环会遍历对应的KV cache block,计算出O的一个block。
- 使用了Warp Specialization的策略,通过生产者–>消费者的方式进行计算。
- Warp Group 1:主要计算线程,负责大部分的注意力得分计算。
- Warp Group 2:使用double buffer的技术进行数据的加载,也参与一些计算。
这块代码比较复杂的,zhihu上有几篇文章写的挺清楚的,我就不一点点写分析了,画个图过来表示一下计算过程,对细节感兴趣的可以去看后面的几个参考的文章。
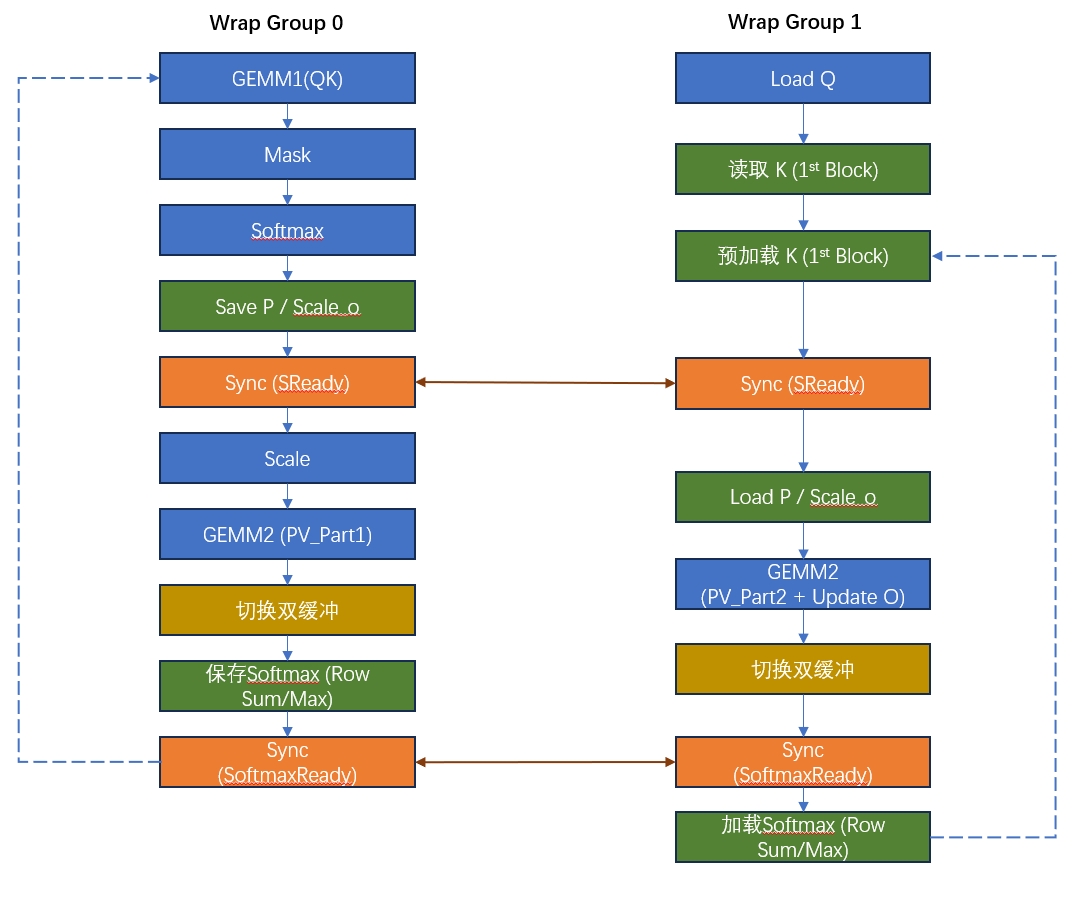
这里可以看到,Warp Group 0会计算GEMM1,但是GEMM2是由两个Warp Group共同计算的,每个Wrap计算其中一半。
这里比较重要的几块逻辑:
- Warp Specialization
int warp_group_idx = cutlass::canonical_warp_group_idx();
if (warp_group_idx == 0) {
// 主要计算逻辑,包括矩阵乘法、归一化、概率矩阵的计算和输出
// thread 0 - 127
....
} else {
// 主要负责加载数据
// thread 128 - 256
}
- 上面else逻辑中的双缓冲
// 双缓冲区数据结构定义
template<typename Kernel_traits>
struct SharedStorageMLA {
union {
struct {
// 存储 Query、Key 和中间结果
...
cute::array_aligned<typename Kernel_traits::Element,
cute::cosize_v<typename Kernel_traits::SmemLayoutK> * 2> smem_k; // Double buffer
...
}
...
}
}
...
// 双缓冲策略(在warp group 1的代码里):切换到第二个缓冲区
if (n_block % 2 == 1) {
// Double buffer for sK
constexpr int sK_offset = size(sK);
tSrK.data() = tSrK.data() + sK_offset / 8;
tOrVt.data() = tOrVt.data() + sK_offset / 8;
}
flash_fwd_splitkv_mla_combine_kernel
最后的flash_fwd_splitkv_mla_combine_kernel比较简单,就是负责数据的合并:
- 在Warp 0中计算各个block的Log-Sum-Exp最大值,获取全局归一化系数。
for (int i = 0; i < kNLsePerThread; ++i) max_lse = max(max_lse, local_lse[i]);
- 在Warp 0中计算缩放因子。
for (int i = 0; i < kNLsePerThread; ++i) {
const int split = i * 32 + tidx;
if (split < actual_num_splits) sLseScale[split] = expf(local_lse[i] - global_lse);
}
- 按照缩放因子,合并Output的输出,完成计算。
for (int split = 0; split < actual_num_splits; ++split) {
...
ElementAccum lse_scale = sLseScale[split];
for (int i = 0; i < size(tOrO); ++i) {
tOrO(i) += lse_scale * tOrOaccum(i);
}
...
}
- 把结果写回全局内存。
参考文章:
- DeepSeek-V2: A Strong, Economical, and Efficient Mixture-of-Experts Language Model
- DeepSeek: FlashMLA代码解析
- flashMLA 深度解析
Last modified on 2025-05-03