3月底整理了一个关于经典Paged Attention算法的ppt, 想起这个几年没写过的blog,把PPT改成一篇文章证明我还活着(-_-)。

vLLM 的 Paged Attention
开始前先说明一下,vLLM里的Paged Attention Kernel是有好几个不同的版本的,大概是下面这样子:
vLLM早期版本:
- Prefilling -> Flash Attention的flash_attn_varlen_func
- Dedocding -> 自己实现的Paged Attention
- paged_attention_v1 : 用于比较短的sequence
- paged_attention_v2 : 用于不想用v1的情况 :)
源码大概是这样的:
# NOTE(woosuk): We use a simple heuristic to decide whether to use
# PagedAttention V1 or V2. If the number of partitions is 1, we use
# V1 to avoid the overhead of reduction. Also, if the number of
# sequences or heads is large, we use V1 since there is enough work
# to parallelize.
# TODO(woosuk): Tune this heuristic.
# For context len > 8192, use V2 kernel to avoid shared memory
# shortage.
use_v1 = (max_seq_len <= 8192 and (max_num_partitions == 1 or num_seqs * num_heads > 512))
vLLM 最新版本就已经全部转向Flash Attention, 用cutlass实现了。
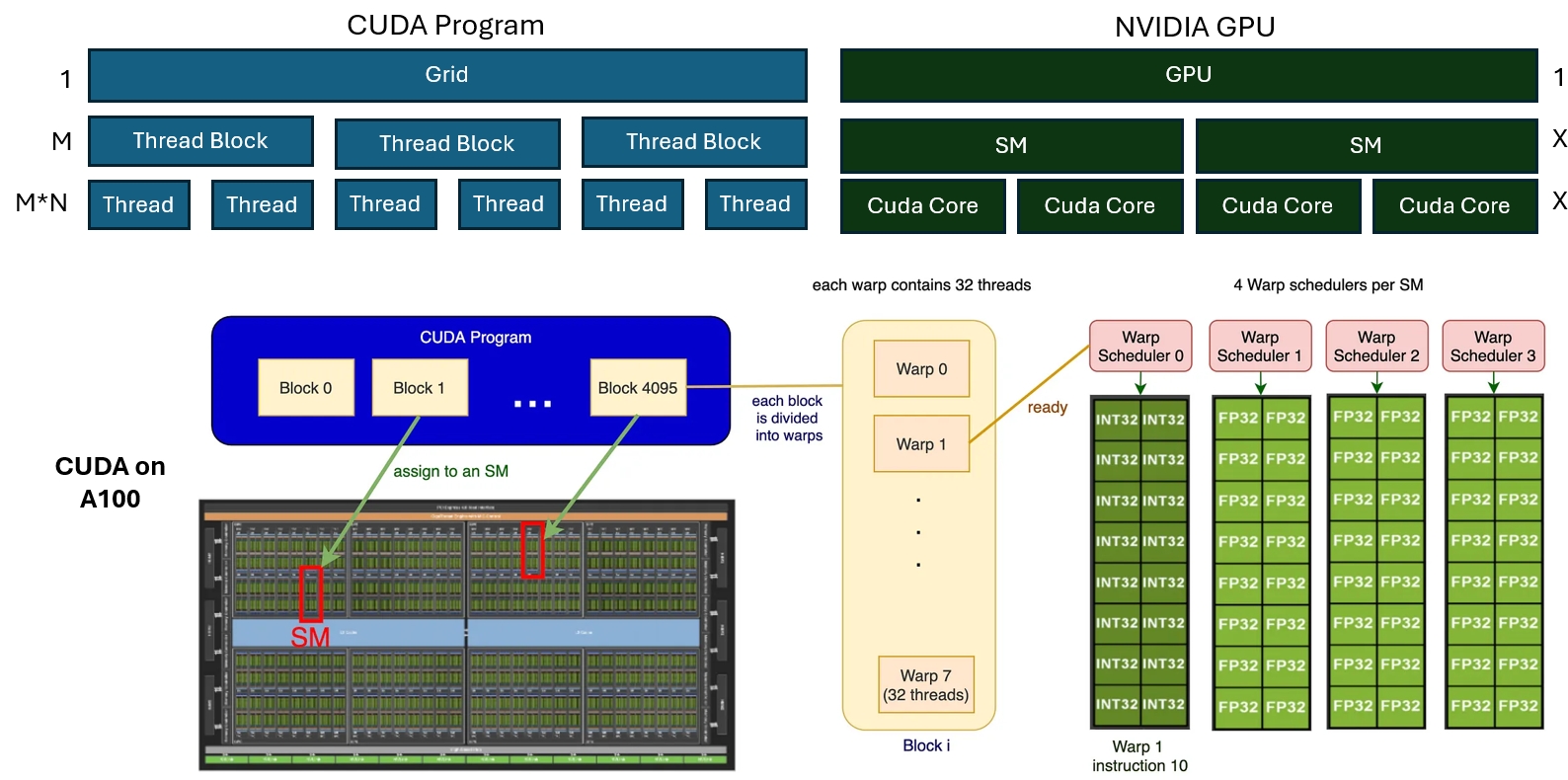
NVIDIA GPU 基础
在深入 Paged Attention 的实现之前,我们需要了解 NVIDIA GPU的基本架构。(这里我们主要讲A100)
在做开发时,GPU 的 CUDA 程序包括 Grid -> Thread Block -> Threads三层架构。 这三层架构对应到GPU的硬件:GPU -> SM -> Cuda Core
在实际执行的时候,Threads会以每32个为一组执行,因此这里还多了一层:Thread Wrap,因此结构变成:
- CUDA程序:Grid -> Thread Block -> Thread Wrap -> Threads四层架构。
- GPU硬件:GPU -> SM(多次执行) -> SM(一次执行) -> Cuda Core,也是四层。
在 A100 GPU 上,我们有:
- 108个SM
- 每个SM有4个Wrap scheduler
- 最多有4个Thread Wrap同时在一个SM上执行
- 每个Wrap scheduler有一个长度为16的调度队列
- 一个SM上最多可以调度64个Thread Wrap
基本上这些数字在设计Kernel的时候都可以被考虑到,从而最大化一个Kernel的硬件利用率。
vLLM Kernel 映射
现在我们看一下vLLM Kernel的设计:(处于简化的目的,我们认为没有TP)
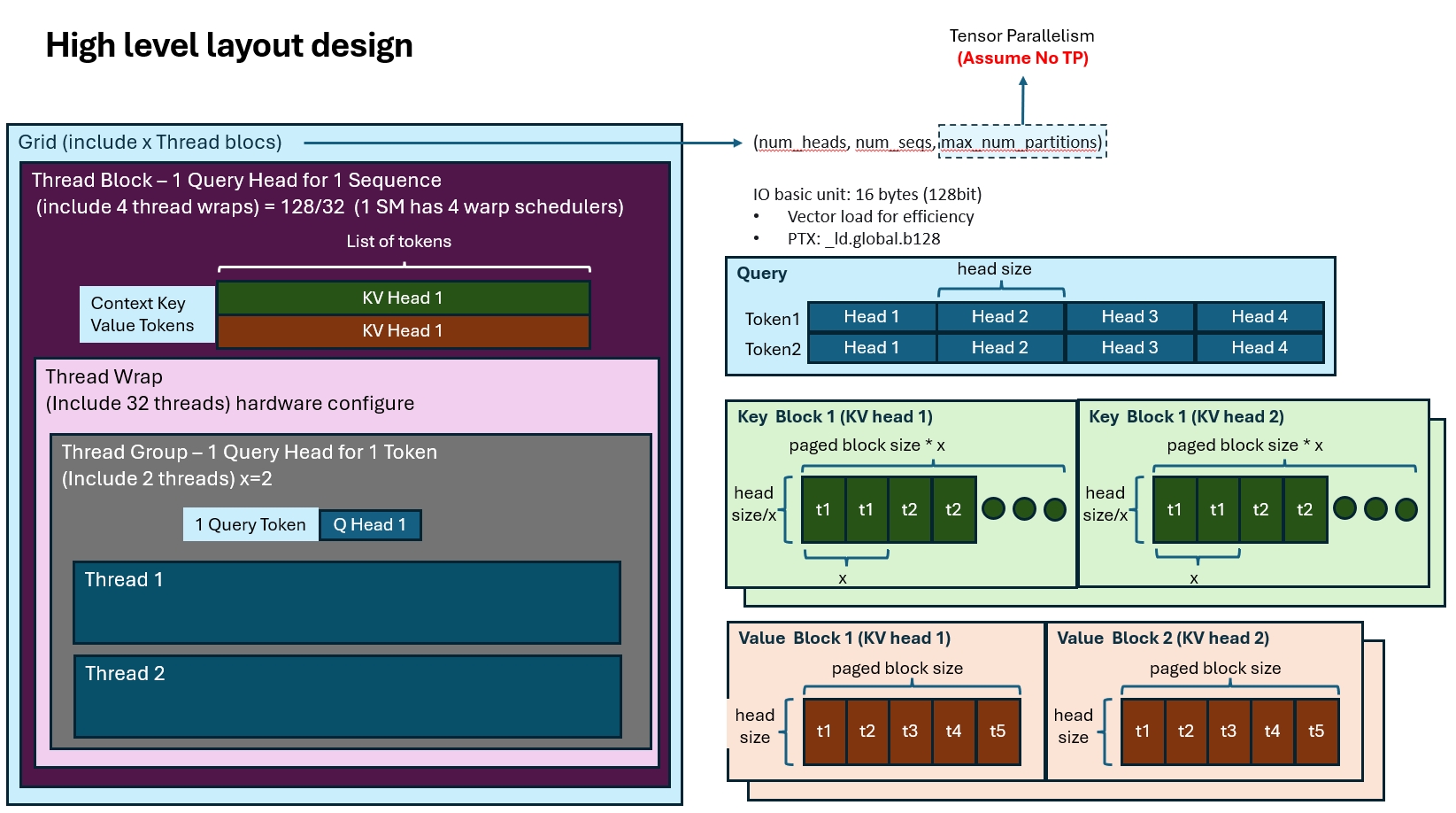
设计Kernel的第一步是把程序拆分成不同的Thread Block来简化问题,vLLM中每个Thread Block会负责1个Query Token的一个Query Head的计算。
这个设计其实比较粗糙。不过没关系,Flash Attention里有更多优化。
设计好计算粒度后,是内存布局的优化,vLLM的Kernel对Q,K, V使用了不同的内存布局,看代码:
const scalar_t* __restrict__ q, // [num_seqs, num_heads, head_size]
const cache_t* __restrict__ k_cache, // [num_blocks, num_kv_heads,
// head_size/x, block_size, x]
const cache_t* __restrict__ v_cache, // [num_blocks, num_kv_heads,
// head_size, block_size]
内存设计的时候,我们一般要考虑的是如何能够更好的做到:1. 每次读取连续的内存块(向量读指令,最好能翻译成_ld.global.b128,以128bit也就是16Bytes为单位);2. 降低不同thread的读冲突。QKV的内存布局基本上也是考虑这些来做的:
- Q的布局是最简单的,序列长度->head数量->head维度。
- K的布局比较复杂,最外层的num_block和num_kv_heads比较好理解,对应了一块KV Cache。但是在没有按照head_size连续存储,还引入了一个参数x。这个布局其实是为了优化K的读取效率,我们在后面再讲。
- 最后是V的布局,比K要直接一些,没有额外的维度x。
基于这个设计,在列一下相关的代码:
// 我们希望能用一个thread wrap一次处理一个KV cache block,这里block_size一般是4/8/16这样子。
// 因为wrap_size=32,大于cache block size,我们就可以给一个token多分配几个thread来加速计算。
// 用wrap size 处理 cache_block_size,这样就知道一个wrap thread可以用几个Thread来处理一个token。
// 这里数字被记作thread group size
[[maybe_unused]] int thread_group_size = MAX(WARP_SIZE / BLOCK_SIZE, 1);
assert(head_size % thread_group_size == 0);
...
# 这里的Num threads是128,最后算出来4个wrap,应该也是对应了A100个一个SM有4个wrap scheduler。
constexpr int NUM_WARPS = NUM的_THREADS / WARP_SIZE;
...
# 没啥好说的,就是一个thread block用128个thread,处理一个token的一个head
dim3 grid(num_heads, num_seqs, 1);
dim3 block(NUM_THREADS);
随着Thread Group的提出,这个CUDA Kernel的架构变的更复杂了 :(
- CUDA程序:Grid -> Thread Block -> Thread Wrap -> Thread Group -> Threads五层架构。
Query数据访问
讲了这么多终于开始计算了,先拿张图演示一下Query Token的访问:
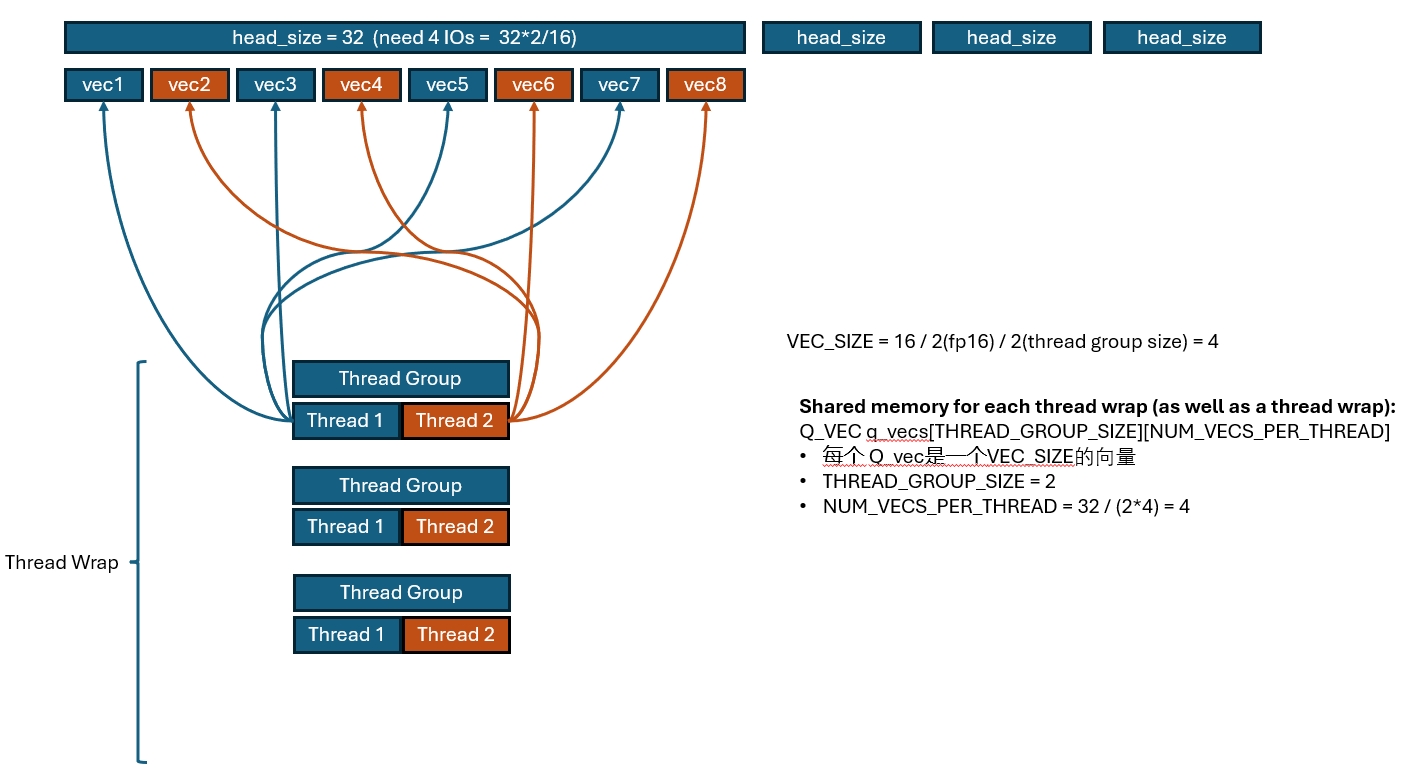
constexpr int VEC_SIZE = MAX(16 / (THREAD_GROUP_SIZE * sizeof(scalar_t)), 1);
constexpr int NUM_ELEMS_PER_THREAD = HEAD_SIZE / THREAD_GROUP_SIZE;
constexpr int NUM_VECS_PER_THREAD = NUM_ELEMS_PER_THREAD / VEC_SIZE;
const scalar_t* q_ptr = q + seq_idx * q_stride + head_idx * HEAD_SIZE;
__shared__ Q_vec q_vecs[THREAD_GROUP_SIZE][NUM_VECS_PER_THREAD];
#pragma unroll
for (int i = thread_group_idx; i < NUM_VECS_PER_THREAD;
i += NUM_THREAD_GROUPS) {
const int vec_idx = thread_group_offset + i * THREAD_GROUP_SIZE;
q_vecs[thread_group_offset][i] =
*reinterpret_cast<const Q_vec*>(q_ptr + vec_idx * VEC_SIZE);
}
对着这块代码讲一下: 可以看到这里因为一个block是专门处理一个token的一个head的,因此把这块数据存在了shared memory里,这样方便复用。
然后这里又引入了一个叫VEC_SIZE的东西,这里其实就是说如果我想一次读16Bytes(_ld.global.b128), 那每个thead一次要读几个元素(因为一共有thread group个线程一起读)。
然后就用各种size来算一下每个thread要读多少次vec,这多么元素又对应多少个VEC,我们就知道一个thread具体要读哪些数据了。
这里thread每次读取的粒度是vec, 而每个thread group每次则读取16Bytes,最后就可以合并成一个向量读的指令来优化IO。
按这个方式把数据都读进来吗,这里其实很多thread要读的数据是一样的,只要有一份数据完成读取,然后其他thread group就可以直接复用这个数据了
Key Cache数据访问
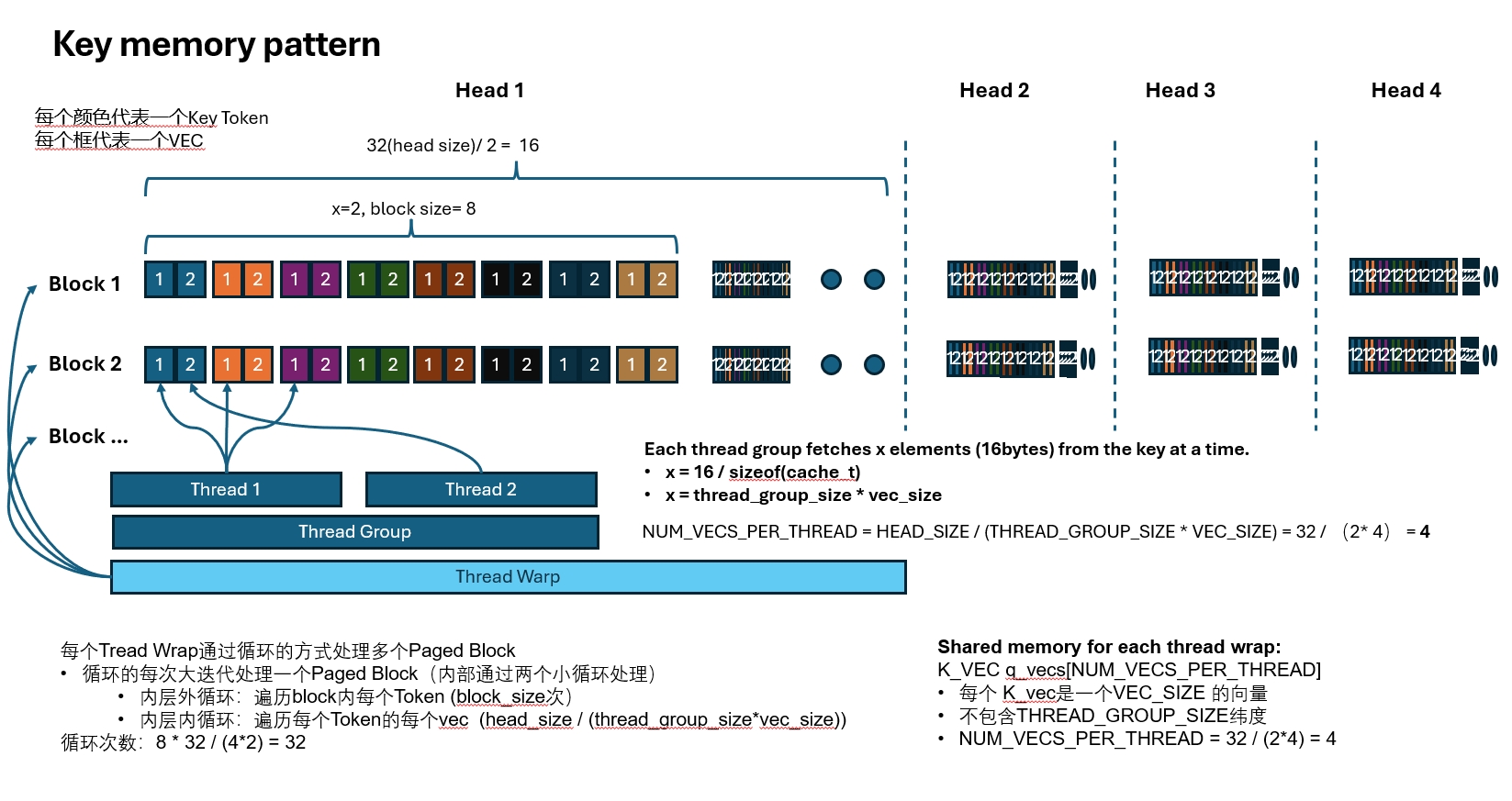
和Query一样,每个thread按VEC访问数据,也是希望一次访问16Bytes,这也是Query最内层有一个X维度的原因。
我们每x个元素的大小是16Bytes,那么每个Thread就可以按16Bytes的方式对数据进行读取。
因为我们需要处理Query Token和所有Key Token的乘积,因此这里要一个block一个block的把所有Key Token读进来。 整个读取过程大概是这样一个三层循环:
每个Thread Wrap通过循环的方式处理多个Paged Block
- 循环的每次大迭代处理一个Paged Block(内部通过两个小循环处理)
- 内层外循环:遍历block内每个Token (block_size次)
- 内层内循环:遍历每个Token的每个vec (head_size / (thread_group_size*vec_size))
- 内层外循环:遍历block内每个Token (block_size次)
同样,只要一个Thread Wrap完成读取,Thread Block里其他Thread Wrap会复用这个读取结果。
看一个这个三重循环的代码:
// 外层大循环:4个wrap一起遍历所有所有paged blocks
// 每次循环:每个wrap处理一个paged block
// 4 个wrap同时执行 (并行度)
// wrap_idx = thread_is / wrap_size
for (int block_idx = start_block_idx + warp_idx; block_idx < end_block_idx;
block_idx += NUM_WARPS) {
...
// Load a key to registers.
// Each thread in a thread group has a different part of the key.
// For example, if the the thread group size is 4, then the first thread in
// the group has 0, 4, 8, ... th vectors of the key, and the second thread
// has 1, 5, 9, ... th vectors of the key, and so on.
// 内层外循环:遍历所有paged blocks
// 每次循环:32个thread一起遍历当前paged block内所有token
// NUM_TOKENS_PER_THREAD_GROUP = DIVIDE_ROUND_UP(BLOCK_SIZE, WARP_SIZE);
// 每个thread group负责一个token(token_idx)
for (int i = 0; i < NUM_TOKENS_PER_THREAD_GROUP; i++) {
const int physical_block_offset =
(thread_group_idx + i * WARP_SIZE) % BLOCK_SIZE;
const int token_idx = block_idx * BLOCK_SIZE + physical_block_offset;
K_vec k_vecs[NUM_VECS_PER_THREAD];
#pragma unroll
// 内层内循环:按 VEC_SIZE 遍历Token内的所有fp16
// 每次循环:32个thread一起遍历paged block内每个token
// NUM_ELEMS_PER_THREAD = HEAD_SIZE / THREAD_GROUP_SIZE;
// NUM_VECS_PER_THREAD = NUM_ELEMS_PER_THREAD / VEC_SIZE;
// 每个thread group 为一组,处理同一个token
// 每个threa一次读取一个VEC
// 每个thread group一共负责 NUM_VECS_PER_THREAD 个VEC
// K_vec k_vecs[NUM_VECS_PER_THREAD]; (1 Paged Block)
for (int j = 0; j < NUM_VECS_PER_THREAD; j++) {
const cache_t* k_ptr =
k_cache + physical_block_number * kv_block_stride +
kv_head_idx * kv_head_stride + physical_block_offset * x;
const int vec_idx = thread_group_offset + j * THREAD_GROUP_SIZE;
const int offset1 = (vec_idx * VEC_SIZE) / x;
const int offset2 = (vec_idx * VEC_SIZE) % x;
if constexpr (KV_DTYPE == Fp8KVCacheDataType::kAuto) {
k_vecs[j] = *reinterpret_cast<const K_vec*>(
k_ptr + offset1 * BLOCK_SIZE * x + offset2);
} else {
// Vector conversion from Quant_vec to K_vec.
Quant_vec k_vec_quant = *reinterpret_cast<const Quant_vec*>(
k_ptr + offset1 * BLOCK_SIZE * x + offset2);
k_vecs[j] = fp8::scaled_convert<K_vec, Quant_vec, KV_DTYPE>(
k_vec_quant, *k_scale);
}
}
// Compute dot product.
....
}
QK 计算
Query和Key都读进来了,下一步自然就是矩阵乘了,还是先上个图:
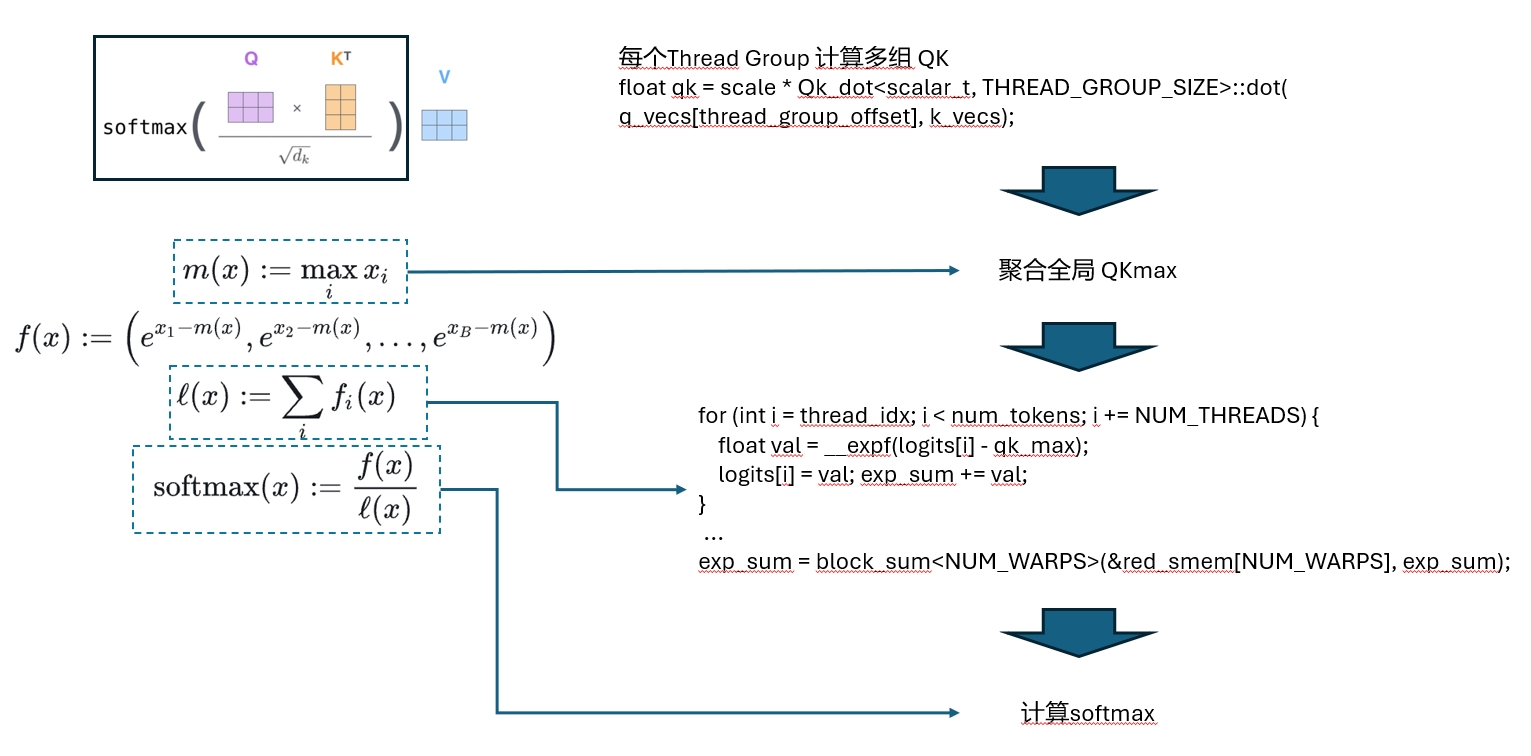
基础的计算的逻辑就是上面代码里省略的部分
// Compute dot product.
// This includes a reduction across the threads in the same thread group.
float qk = scale * Qk_dot<scalar_t, THREAD_GROUP_SIZE>::dot(
q_vecs[thread_group_offset], k_vecs);
// Add the ALiBi bias if slopes are given.
qk += (alibi_slope != 0) ? alibi_slope * (token_idx - seq_len + 1) : 0;
if (thread_group_offset == 0) {
// Store the partial reductions to shared memory.
// NOTE(woosuk): It is required to zero out the masked logits.
const bool mask = token_idx >= seq_len;
logits[token_idx - start_token_idx] = mask ? 0.f : qk;
// Update the max value.
qk_max = mask ? qk_max : fmaxf(qk_max, qk);
}
}
然后要做reduce,因为所有qk的乘积是分布在多个Thread里面的,我们要把Thread block里所有的数据都聚合起来,才好算最后的softmax,这里是经典的两层reduce算法,细节就不解释了。
// Perform reduction across the threads in the same warp to get the
// max qk value for each "warp" (not across the thread block yet).
// The 0-th thread of each thread group already has its max qk value.
#pragma unroll
// 经典的Thread Wrap内reduce算法
for (int mask = WARP_SIZE / 2; mask >= THREAD_GROUP_SIZE; mask /= 2) {
qk_max = fmaxf(qk_max, VLLM_SHFL_XOR_SYNC(qk_max, mask));
}
if (lane == 0) {
red_smem[warp_idx] = qk_max;
}
__syncthreads();
// 经典的Thread Block内reduce算法
// TODO(woosuk): Refactor this part.
// Get the max qk value for the sequence.
qk_max = lane < NUM_WARPS ? red_smem[lane] : -FLT_MAX;
#pragma unroll
for (int mask = NUM_WARPS / 2; mask >= 1; mask /= 2) {
qk_max = fmaxf(qk_max, VLLM_SHFL_XOR_SYNC(qk_max, mask));
}
// Broadcast the max qk value to all threads.
qk_max = VLLM_SHFL_SYNC(qk_max, 0);
// 计算softmax
// Get the sum of the exp values.
float exp_sum = 0.f;
for (int i = thread_idx; i < num_tokens; i += NUM_THREADS) {
float val = __expf(logits[i] - qk_max);
logits[i] = val;
exp_sum += val;
}
exp_sum = block_sum<NUM_WARPS>(&red_smem[NUM_WARPS], exp_sum);
// Compute softmax.
const float inv_sum = __fdividef(1.f, exp_sum + 1e-6f);
for (int i = thread_idx; i < num_tokens; i += NUM_THREADS) {
logits[i] *= inv_sum;
}
__syncthreads();
跑到这里以后,softmax就算完了,剩下来的就是在乘一下V Cache,这块就比较简单了。
Value访问和Attneion计算
Value的访问比较直接,直接上图,就是大家一起把所有Value都读进来。
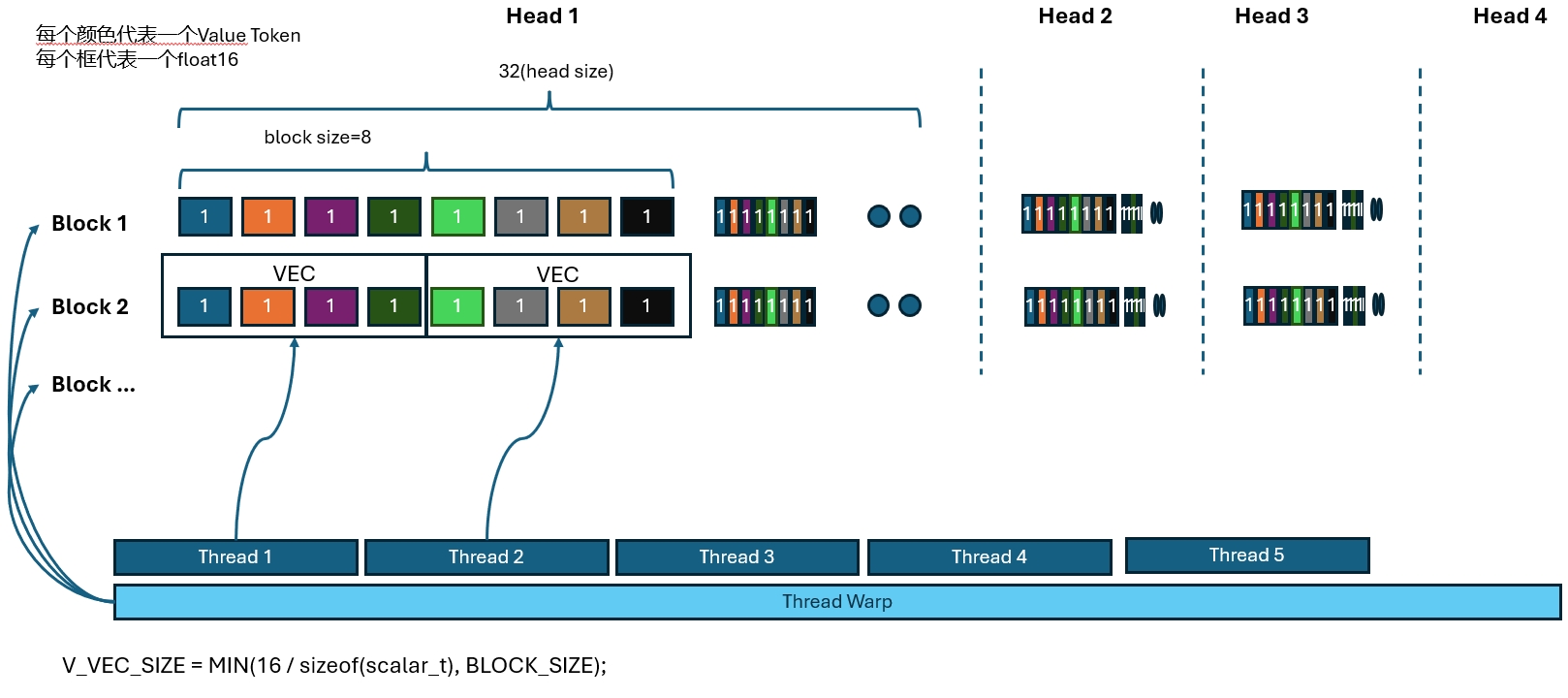
同时边读边计算,都在这个图里了:
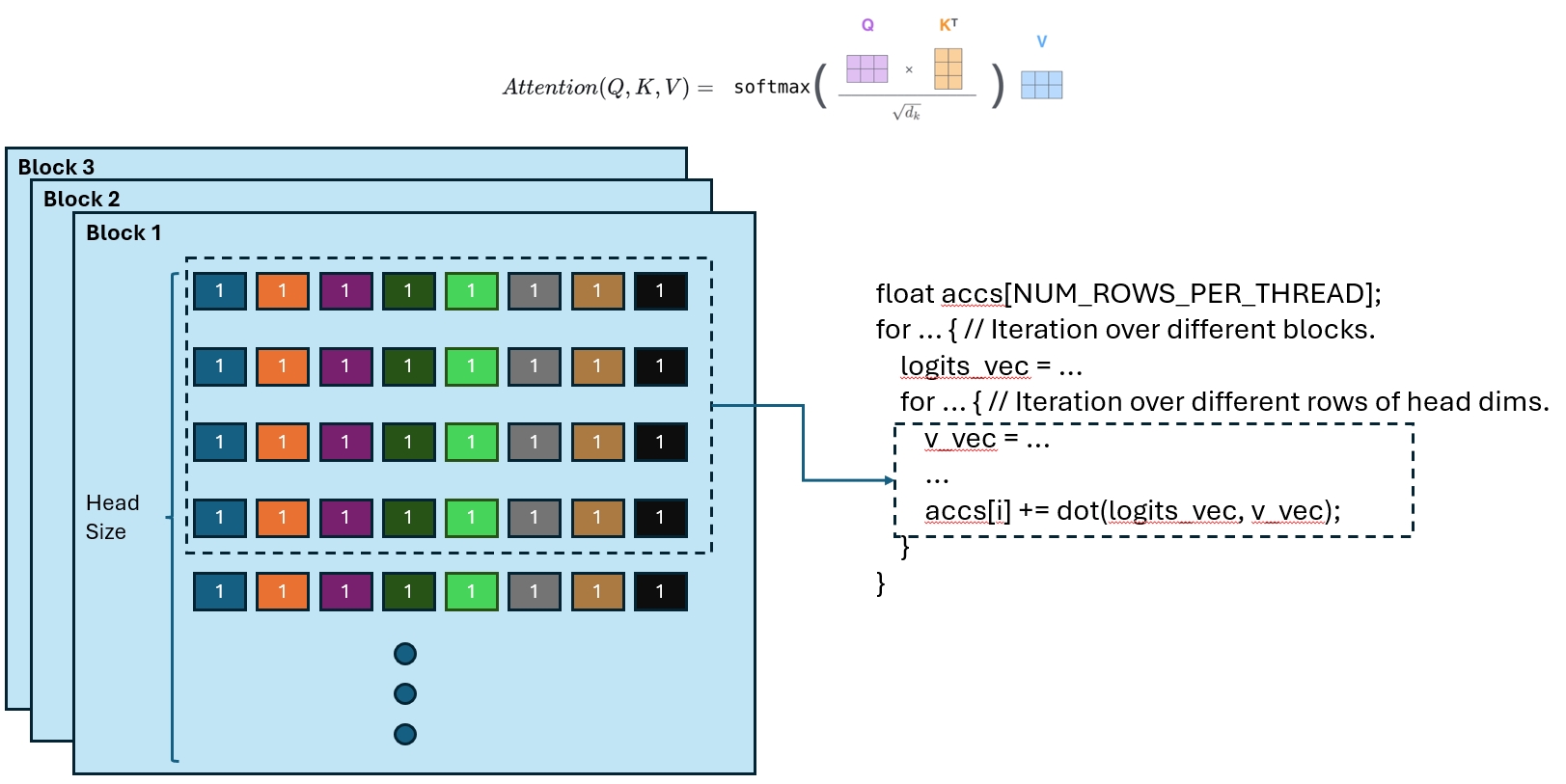
就是先按block进行遍历,然后每次重block里读所有token的一部分维度进行计算,把所有维度都算出来,分散的存在各个thread里。
// 一样的外层大循环:4个wrap一起遍历所有paged blocks
for (int block_idx = start_block_idx + warp_idx; block_idx < end_block_idx;
block_idx += NUM_WARPS) {
// NOTE(woosuk): The block number is stored in int32. However, we cast it to
// int64 because int32 can lead to overflow when this variable is multiplied
// by large numbers (e.g., kv_block_stride).
const int64_t physical_block_number =
static_cast<int64_t>(block_table[block_idx]);
const int physical_block_offset = (lane % NUM_V_VECS_PER_ROW) * V_VEC_SIZE;
const int token_idx = block_idx * BLOCK_SIZE + physical_block_offset;
L_vec logits_vec;
from_float(logits_vec, *reinterpret_cast<Float_L_vec*>(logits + token_idx -
start_token_idx));
const cache_t* v_ptr = v_cache + physical_block_number * kv_block_stride +
kv_head_idx * kv_head_stride;
#pragma unroll
// NUM_V_VECS_PER_ROW = BLOCK_SIZE / V_VEC_SIZE;
// 一个Paged Block有几个VEC
// NUM_ROWS_PER_ITER = WARP_SIZE / NUM_V_VECS_PER_ROW;
// 一个WRAP可以同时处理几个 Paged Block
// NUM_ROWS_PER_THREAD = DIVIDE_ROUND_UP(HEAD_SIZE, NUM_ROWS_PER_ITER);
// 遍历所有head纬度需要几个迭代
for (int i = 0; i < NUM_ROWS_PER_THREAD; i++) {
const int row_idx = lane / NUM_V_VECS_PER_ROW + i * NUM_ROWS_PER_ITER;
if (row_idx < HEAD_SIZE) {
const int offset = row_idx * BLOCK_SIZE + physical_block_offset;
V_vec v_vec;
if constexpr (KV_DTYPE == Fp8KVCacheDataType::kAuto) {
v_vec = *reinterpret_cast<const V_vec*>(v_ptr + offset);
} else {
V_quant_vec v_quant_vec =
*reinterpret_cast<const V_quant_vec*>(v_ptr + offset);
// Vector conversion from V_quant_vec to V_vec.
v_vec = fp8::scaled_convert<V_vec, V_quant_vec, KV_DTYPE>(v_quant_vec,
*v_scale);
}
if (block_idx == num_seq_blocks - 1) {
// num_seq_blocks = DIVIDE_ROUND_UP(seq_len, BLOCK_SIZE);
// 对最后一个Paged Block特殊处理,防止越界
// NOTE(woosuk): When v_vec contains the tokens that are out of the
// context, we should explicitly zero out the values since they may
// contain NaNs. See
// https://github.com/vllm-project/vllm/issues/641#issuecomment-1682544472
scalar_t* v_vec_ptr = reinterpret_cast<scalar_t*>(&v_vec);
#pragma unroll
for (int j = 0; j < V_VEC_SIZE; j++) {
v_vec_ptr[j] = token_idx + j < seq_len ? v_vec_ptr[j] : zero_value;
}
}
// 按Vec分段计算和V的乘积:由多个thread计算,后续需要进一步聚合。
accs[i] += dot(logits_vec, v_vec);
}
}
}
等算法以后再进行reduce把结果聚合,得到最后的结果。这个是经典的reduce算法:
// Perform reduction within each warp.
// 经典in wrap规约算法
#pragma unroll
for (int i = 0; i < NUM_ROWS_PER_THREAD; i++) {
float acc = accs[i];
#pragma unroll
for (int mask = NUM_V_VECS_PER_ROW / 2; mask >= 1; mask /= 2) {
acc += VLLM_SHFL_XOR_SYNC(acc, mask);
}
accs[i] = acc;
}
// NOTE(woosuk): A barrier is required because the shared memory space for
// logits is reused for the output.
__syncthreads();
// Perform reduction across warps.
// 经典树状cross wrap规约算法
float* out_smem = reinterpret_cast<float*>(shared_mem);
#pragma unroll
for (int i = NUM_WARPS; i > 1; i /= 2) {
int mid = i / 2;
// Upper warps write to shared memory.
if (warp_idx >= mid && warp_idx < i) {
float* dst = &out_smem[(warp_idx - mid) * HEAD_SIZE];
#pragma unroll
for (int i = 0; i < NUM_ROWS_PER_THREAD; i++) {
const int row_idx = lane / NUM_V_VECS_PER_ROW + i * NUM_ROWS_PER_ITER;
if (row_idx < HEAD_SIZE && lane % NUM_V_VECS_PER_ROW == 0) {
dst[row_idx] = accs[i];
}
}
}
__syncthreads();
// Lower warps update the output.
if (warp_idx < mid) {
const float* src = &out_smem[warp_idx * HEAD_SIZE];
#pragma unroll
for (int i = 0; i < NUM_ROWS_PER_THREAD; i++) {
const int row_idx = lane / NUM_V_VECS_PER_ROW + i * NUM_ROWS_PER_ITER;
if (row_idx < HEAD_SIZE && lane % NUM_V_VECS_PER_ROW == 0) {
accs[i] += src[row_idx];
}
}
}
__syncthreads();
}
算完以后就是把结果写到output了,这块就不贴了。
收尾
大概流程就是这样,整个流程还是设计不少细节的,我也不知道写清楚没有,不过对着代码多看几遍总能看明白的。
Last modified on 2025-04-20