今天收拾资料,发现了以前刚接触粗糙集时写的一个综述,好久没写博客,发上来充数好了
一、粗糙集模型1
粗糙集是Pawlak于上世纪八十年代提出的一种不确定数学模型。该模型以有限集合上的等价关系为基础,定义了上下近似两个基本操作。该模型与它的其他一般化或变种形式有着较为广泛的应用。
Pawlak粗糙集模型是以一个有限集合与集合上的一个等价关系为基础的。所谓的二元等价关系是一种满足自反性,对称性和传递性的关系的二元关系。因为这些性质,一个二元等价关系将一个集合分割成一到多个互不相较子集,形成了集合的一个分割,记为U/R,其中的元素与他们的并被称为精确集。
在这一基础上,Pawlak提出了近似的概念,所谓近似,是通过一个已有集合U的一个分割中的集合的并集对一个U的任意子集X进行逼近,作为X的近似。包括上近似于下近似两种。如,设R是U上一个等价关系,则,X的上下近似分别为:

通过2中近似,我们可以把U分为三个部分,分别称为正域POS(X),边界域BND(X),和负域NEG(X),这三个域都是U/R上一些集合的并,也就是可以用R精确表示的精确集:分别表示一定属于X,可能属于X,和一定不属于X三种定义。

进一步的,对于任意两个等价关系R,D定义:

可以证明的是,在Pawlak粗糙集模型中 。
。
1.2变精度粗糙集模型(VPRT)2
在原有粗糙集模型的基础上,又可以引入变精度粗糙集的概念,变精度粗糙集通过引入一个精度参数 ,定义
,定义 ,重新定义正域为
,重新定义正域为 ,边界域为
,边界域为 ,负域为
,负域为 。
。

1.3概率粗糙集模型3
概率粗糙集模型是变精度粗糙集模型的进一步泛化,通过引入两个参数 将正域、边界域和负域分别定义为
将正域、边界域和负域分别定义为  。
。

值得一提的是,这些参数并非一定要考实验者手动选择,有时可以作为数据集的一种性质而导出,比如当我们只有两个X和~X两种结论时,我们可以通过使用成本矩阵中提供的信息对参数进行求解。1
1.4其他粗糙集模型
除了上面提到的3种模型外,还有其他一些模型如模糊粗糙集模型、代数粗糙集模型(如粗糙群、粗糙环)4等,这些模型都是原有Pawlak粗糙集模型的泛化,可以根据不同的需要进行选择。
二、决策粗糙集
决策粗糙集是根据一张决策信息表定义的粗糙集模型,一张决策信息表是一个四元组{U,AT∪D,V,f},其中:
U={u1,u2,u3….} |U|=n<+∞
AT∪D表示属性的集合,分为信息属性AT和决策属性D两个互不相交的子集

通过属性的不同取值,我们可以对U进行分类,而根据AT和D两组属性,我们可以在U上定义两个等价关系,RAT与RD。通过根据这两组划分中的元素的相互关系,我们可以将他们间的元素联系起来,这样我们就得到了一系列的决策规则用于未知数据的预测。
2.1完备信息系统
完备信息系统是指信息系统中U中每个元素ui在AT∪D上的各个属性值确定已知,没有未知或丢失属性的情况发生,对于这种信息表,我们可以简单通过观察属性值是否相同来判断两个元素是否等价。
当信息系统中的属性都是简单的定性分类数据时,我们就可以简单的在U上定义两个等价关系,分别为:

通过这两个等价关系,我们得到了U上的两个划分,将U/RAT 中的元素记为pi(i=1,2..|U/RAT|),U/RD中的元素记为qj(j=1,2..|U/RD|),如果有i、j满足集合pi属于集合qj说明当一个元素与等价集合pi中的元素在AT上属性值相等时,就一定有i在D上与qj的元素属性值相等,即可得出一条规则pi->qj。
根据这一思想,我们可以引出更为一般的决策规则。定义信息原子表达式 表示满足信息属性ai等于v的所有元素集合。决策原子表达式
表示满足信息属性ai等于v的所有元素集合。决策原子表达式 表示满足决策属性di等于v的所有元素集合。
表示满足决策属性di等于v的所有元素集合。
现在对信息表达式进行定义,如果 是信息表达式则
是信息表达式则 也都是信息表达式,同时所有信息原子表达式是信息表达式。
也都是信息表达式,同时所有信息原子表达式是信息表达式。
同理定义决策表达式,用 表示。
表示。
用 表示规则中的所有元素属于。即如果元素满足表达式
表示规则中的所有元素属于。即如果元素满足表达式 ,则判断其满足表达式
,则判断其满足表达式 。这样我们就定义了最一般的规则表达式。
。这样我们就定义了最一般的规则表达式。
根据粗糙集的正域POS(X),边界域BND(X),和负域NEG(X),我们可以从决策信息表的两个划分中定义以下两种规则
 ,则有:
,则有:
2边界规则:如果 ,则有:
,则有:

根据这两种规则,我们就得到了从该信息系统中能得出的有效规则,通过这些规则,我们就可以通过任一元素在AT上的值,去估计它在D上的结论值。
另外,有时我们的属性表中虽然有确定已知的属性值,但可能数据并非简单的定性分类数据,而是定量连续数据,对于这种属性,离散化处理使其变为定性分类数据是最为简单有效的方法。
2.1.2定量属性—相似关系的引入5
有时,我们并不能用简单的定性分类属性表示AT中的所有属性,因此,就引入了另外两种关系:相似关系与优势关系。
当AT中的属性为量化数据时,我们可以简单改变原来属性值完全相等才属于同一类别的定义,对每一个数值定义一个范围的领域,当另一元素y的该属性值属于元素x的该属性的邻域中时,我们就说y与x相似,这样我们就在U上重新定义的一个二元相似关系。
由于邻域可以任意的选择(一般要包括该值自己),所以这一新的二元关系并不一定是等价关系了,这个关系将可能不再满足传递性与对称性。我们用xRy表示x相似于y。根据R对任一个x,我们可以定义两个集合,分别表示相似于x的元素集和x相似于的元素集。

这样我们就得到了两个U上的覆盖(由于这个关系将可能不再满足传递性与对称性,U上所有相似类也就不再一定会构成一个U的划分,而是构成一个覆盖。于是我们有覆盖:

有了关系R以后,我们认为一个元素x绝对属于X当且仅当x相似于的元素都属于X,同时,所有相似于X中某一元素x的元素都有可能属于X,于是可以定义U的任意子集X在关系R下上下近似为:

有了这个两个近似后,我们就可以像之前一样计算POS(X),BND(X),NRG(X)并简单的定义信息系统上的两种规则了。
2.1.3优势关系与排序问题
但是当我们决策属不再是简单的分类关系而是一中偏序关系时,我们就不能再像以前一样进行规则的推导了,这是,就要通过引入优势关系下的近似来进行处理。
在优势关系中,在属性集AT上我们定义xDy表示x比y更好,一般来说xDy定义为:

这样,我们就可以对每个x定义两个集合分别表示比x更优的元素和x比其更优的元素。

而处理决策集时,我们不再简单对每一类决策类求近似,而是求他们并集的近似:

有了这四种近似后,我们可以将(1)(2)分为一组,(3)(4)分为一组,分别按照原有方法导出两种规则求解一定属于 的元素规则和可能属于
的元素规则和可能属于 的元素规则。
的元素规则。
2.1.4成对比较表法PCT6
当我们拥有一张已经排序的信息表时,除了以上提到的方法以外,还有一种成对比较表法可以处理排序问题,导出规则对未知元素进行排序。
该方法的核心是将原来定义在U上的信息表扩展为一个UXU上的信息表。
新的信息表表示为{UXU,AT∪D,V,f}}
UXU: |UXU|=n*n
AT∪D中的属性与原有信息表中的属性一一对应,但是不再表示具体的属性值,对于AT中的属性a和元素(x,y),新的信息表中a的值表示在原信息表中元素x比y在属性a上的优异程度。而对于D中的属性值,新的信息表中的属性d仅表示x优于y或y优于x。
这一篇讲的是区间估计…..因为这不是一个关于统计学的系列,所以对文中出现的公式不会给予任何证明…..就是这样。
就从一个最简单的正态分布的方差已知时,求均值的置信区间开始吧。
书上的公式告诉我们这个区间是 $$\overline{x}\pm(\sigma/\sqrt{n})z_{(1-\sigma/2)}$$ ,其中Zp表示的是正态分布N(0,1)下侧的p分位数。
我们用R来实现求得这一结果的过程。下面设x里存储了给出的样本,sigma表示已知的方差,n表示样本的个数, alpha则是(1-置信水平)
mean<-mean(x) ans<-c(mean-sigma*qnorm(1-alpha / 2)/sqrt(n) , mean+sigma*qnorm(1-alpha / 2)/sqrt(n))
这样,ans就存储了要求的置信区间。
来解释一下吧,先用mean(x)求出样本的平均值,然后用qnorm(1-alpha / 2)求出Z1-a/2,(还记得么?前缀q是分位数函数,)剩下的就是套公式的加减法了。
这里的qnorm(1-alpha / 2)其实省略了很多参数,完整一些的写法是
qnorm(1-alpha/2,mean=0,sd=1,lower.tail=TRUE)
第一个参数就不用解释了,第二,三个参数mean=0,sd=1,表示这是一个标准正态分布(不同于前面,这里增加了mean=和sd=,这种做法的好处是可以改变参数的顺序,但是结果是一样的),最后一个参数lower.tail这个参数的意思就比较有意思了,官方解释如下:
if TRUE (default), probabilities are $P[X <= x]$, otherwise, $P[X > x]$.
明白了么?等于真的话,得出的就是X<=x的分位数,为假的话就是从X>x的方法寻找这个值。一般我们用默认的真就可以了。
接下来我们把它整理成一个函数,方便使用
z.test<-function(x,n,sigma,alpha){
mean<-mean(x)
ans<-c(
mean-sigma*qnorm(1-alpha/2,mean=0,sd=1,lower.tail=TRUE)/sqrt(n),
mean+sigma*qnorm(1-alpha/2,mean=0,sd=1,lower.tail=TRUE)/sqrt(n))
ans
}
这样我们就可以直接使用z.test()完成对u的置信区间的计算。
比如,有10个样本,分别是175,176,173,175,174,173,173,176,173,179。标准差为1.5,求均值95%的置信区间:
x<-c(175,176,173,175,174,173,173,176,173,179) z.test(x,10,1.5,0.05)
则返回置信区间:
[1]173.7703 175.6297
简单来说,R语言是一种主要用于统计分析、绘图的语言和操作环境。的源代码可自由下载使用,亦有已编译的执行档版本可以下载,可在多种平台下运行,包括UNIX(也包括FreeBSD和Linux)、Windows和MacOS。R主要是以命令行操作,同时有人开发了几种图形用户界面。
为什么我会使用R语言呢?毕竟我们还有SPSS,SAS,S等其他工具。就我个人而言(其实对很多人也是这样)有两个原因—-R的开源与其极高的自由度。
R是开源的,是属于GNU系统的一个自由、免费、源代码开放的软件因此在使用它时我们不用担心使用的资格问题。(当然对人一般人来说其他软件也可以使用盗版…起码国内是这样)另外作为一种语言,R拥有极高的自由度—-对于,很多新的统计学模型,也许SPSS等软件根本无法处理—你只能使用系统提供的有限选项。但是在R语言中,你可以自己去实现它。这也是学术界对R如此关注的原因。
敲了这么多废话,进入正题。
这一篇的内容是数据描述,就冲R中内嵌的一些简单分布开始吧。
R语言中提供了四类有关统计分布的函数(密度函数,累计分布函数,分位函数,随机数函数)。分别在代表该分布的R函数前加上相应前缀获得(d,p,q,r)。如正态分布的函数是norm,命令dnorm(0)就可以获得正态分布的密度函数在0处的值(0.3989)(默认为标准正态分布)。同理pnorm(0)是0.5就是正态分布的累计密度函数在0处的值。而qnorm(0.5)则得到的是0,即标准正态分布在0.5处的分位数是0(在来个比较常用的:qnorm(0.975)就是那个估计中经常用到的1.96了)。最后一个rnorm(n)则是按正态分布随机产生n个数据。上面正态分布的参数平均值和方差都是默认的0和1,你可以通过在函数里显示指定这些参数对其进行更改。如dnorm(0,1,2)则得出的是均值为1,标准差为2的正态分布在0处的概率值。要注意的是()内的顺序不能颠倒。
接下来我们用R来生成一个二项分布分布的图形吧。
binom是二项分布。
n<-20 p<-0.2 k<-seq(0,n) plot(k,dbinom(k,n,p))
R语言中用<-给变量赋值,我们先让n=20,p=0.2然后用函数seq生成一个向量(1,2,3…20)并将其赋于k。然后用polt函数画图。
在这里,我们用dbinom(k,n,p)生成了参数为n,p的二项分布在1….20处的概率值,然后以k的各个值为横坐标,dbinom(k,n,p)的各个值为纵坐标,绘图。
然后我们来看一些R对数据性质的描述。
绘制直方图:hist(x),横轴表示变量取值,纵轴表示频率。
x<-c(1,2,3,4,5) hist(x)
(R语言中的向量前要求加c进行说明,故第一步是让x为一个值为(1,2,3,4,5)的向量,当然也可以看成一个值为1,2,3,4,5的样本)
我们来画二项分布的直方图吧
N<-10000 n<-100 p<-0.9 x<-rbinom(x,n,p) hist(x)
思考一下,上面的代码是怎样运作的?
绘制茎叶图: stem(x)
x<-c(11,12,13,21,22,23) stem(x)
结果如下:
The decimal point is 1 digit(s) to the right of the |
1 | 123
1 |
2 | 123
另外还有
盒图:boxplot(x)
在各种图形之后,就是对数据的数值型描述了,包括
最大值max(x),最小值min(x),中位数median(x),五个分位数fivenum(x),平均数mean(x),样本方差var(x),样本标准差sd(x),样本偏度系数skewness(x),峰度系数kurtosis(x)等等。
N<-10000 n<-100 p<-0.9 x<-rbinom(x,n,p) max(x) min(x) median(x) fivenum(x) mean(x) var(x) sd(x) library(fBasics) skewness(x) kurtosis(x)
就可以得到生成的随机数据的各种描述。
** **一元线形回归模型:有变量x,y。假设有关系y=c+bx+e,其中c+bx 是y随x变化的部分,e是随机误差。
可以很容易的用函数lm()求出回归参数b,c并作相应的假设检验,如:
x<-c(0.10, 0.11, 0.12, 0.13, 0.14, 0.15,0.16, 0.17, 0.18, 0.20, 0.21, 0.23) y<-c(42.0, 43.5, 45.0, 45.5, 45.0, 47.5,49.0, 53.0, 50.0, 55.0, 55.0, 60.0) lm.sol<-lm(y ~ 1+x) summary(lm.sol)
仅列出部分返回结果:
Residuals:
Min 1Q Median 3Q Max
-2.0431 -0.7056 0.1694 0.6633 2.2653
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 28.493 1.580 18.04 5.88e-09 ***
x 130.835 9.683 13.51 9.50e-08 ***
在我们的输入中,关键是lm.sol<-lm(y ~ 1+x)的调用,这里可以看到,lm使用了参数y~1+x,即表示我们使用的是模型y=c+bx+e (1表示常数项)
然后我们使用summary查看了lm返回的结果。在Residuals:中,我们可以看到的是一些关于残差的信息:最小最大值,4分位数等。Coefficients:中则是最为关键的对c和b的相关估计。其中Estimate是与b,c值的估计,Std. Error 则是回归参数b和c的标准差:sd(b), sd(c)。剩下的两个参数则是对回归参数的假设检验: t value是对b,c进行假设检验的t值,以及P-值(用来与显著性水平比较决定是否接受该阿假设检验)Pr(>|t|)。最后我们还可以看到3个* 号,这表明x和y有非常显著的线性关系(*可以有0—3个,越多则线性关系越显著)。
做毕设的时候写的东西,贴上来吧…………
由于在OPENGL只能通过程序语言绘制模型,远不能达到可见既可得的目的。因此,比起3DMAX、MAYA等可视化3D建模工具,OPENGL模型的建立就相当的困难,为了简化这一问题的处理,可以使用简单小巧的MS3D来完成可见即可得的绘制过程。
MS3D的文件有着非常简单良好的文件结构,可从该文件中完美读取在可视工具中绘制的3D图形模型包含的点、线、面等各项基本结构的参数与位置,并在OPENGL根据读取结果即可进行绘制重现该模型。
MS3D全名为MilkShape3D,是一款简单小巧的3D可视化图形建模工具,可以简单的使用各种点、线面等基本图形元素组合建立模型,并进行贴图,分组。进一步的,该工具还支持简单的骨骼动画制作,是一款非常好用的3D图形构建工具。
[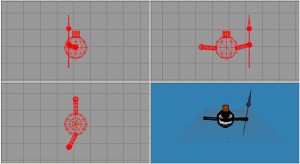 ][1]
][1]
在建立了MS3D中完成模型建立后可保存为.ms3d的文件格式,通过对该文件格式进行分析,就可以了解文件结构,以在程序中通过读取该文件重现所见模型。
该文件依次包括6段信息,除第一段文件头外,其它每段的开始位置都记录了该段中元素的数目,可用于计算该段的具体大小。
-
文件头:大小固定为14字节。前10个字节为固定的标志 MS3D000000<-其中后6个字节就是字符0(即值为48)后4个字节为该模型格式的版本号,这4个字节为一个有符号整数,目前该版本号的值为3或4,两种版本的格式细节不同。
-
点数据:紧接着文件头的就是模型的顶点数据部分,顶点部分的头两个字节为一个无符号整数,表示有多少个顶点。之后便是一个接一个的顶点的具体数据,包括可见性,x,y,z的坐标和绑定骨骼的ID编号(未绑定骨骼则为-1)。
-
多边形数据: 紧接着顶点数据的是多边形数据(三角形),多边形部分头两个字节是一个无符号整数,表示有多少个三角形。之后便是一个接一个的三角形数据。主要记录了每个三角形结构,包括顶点索引,顶点法线(用于光照计算),纹理坐标和组信息。
-
组信息:即网格信息,出于灵活性的考虑,模型的一个个三角形被按照网格或是组来划分。网格部分头两个字节是一个无符号整数,表示有得多少个网格。之后便是一个接一个的网格数据,每个网格结构的大小可能不同(因为他们拥有的三角形数不同)。主要包括网格的名字(字符串),三角形数量、三角形索引和材质索引(无材质则为-1)。
-
材质信息:贴图、颜色等材质部分。头两个字节是一个无符号整数,表示有多少个材质。之后便是一个接一个的材质信息。包括材质名、环境光、漫射光、高光、自发光、发光值、透明度、贴图文件名、透明贴图文件名。
-
骨骼信息: 动画、动作等。该结构是MS3D中的动态结构,仅当建立动态动画时存在,包括一种名为关键帧的结构,记录时间与对应的坐标系变换。骨骼信息,一开始是两个字节的无符号整数,表示一共有多少个骨骼,之后便是一个个的骨骼,骨骼的大小不是固定的。主要包括了骨骼名字,父骨骼名字,初始旋转与初始平移、以及之后的各个旋转与平移关键帧。
在分析了解了MS3D的文件格式后,就可以通过编写程序读取MS3D文件并根据该文件建立模型了,对应于MS3D的不同分段,可以依次建立6种结构体分别对应每段内容:
MS3DHeader /\*包含ms3d文件的版本信息\*
MS3DVertex /\*顶点信息\*/
MS3DMaterial /\*材质(纹理贴图等)信息\*/
MS3DTriangle /\*绘制三角形信息\*/
MS3DJoint /\*节点(骨骼)信息\*/
MS3DKeyframe /\*关键窗口\*/
//an example for vertex
struct MS3DVertex
{
unsigned char m_ucFlags; //编辑器用标志
CVector3 m_vVert; //x,y,z的坐标
char m_cBone; //Bone ID (-1 ,没有骨头)
unsigned char m_mcUnused; //保留,未使用
};
(1)第一个成员表示了该顶点在编辑器中的状态(引擎中不是必须)其各个值的含义如下:
0:顶点可见,未选中状态
1:顶点可见,选中状态
2:顶点不可见,未选中状态
3:顶点不可见,选中状态
(2)第二个成员为顶点的坐标,CVector3为三个float型组成,总共12字节
(3)第三个成员为该顶点所绑定的骨骼的ID号,如果该值为-1 则代表没有绑定任何骨骼(静态)
(4)第四个成员不包含任何信息,直接略过。
将MS3D各段内容分别导入对应的结构体,将其读入内存。
多边形(三角形)结构读取示范:
//内存空间分配
// pPtr为文件读取偏移指针
int nTriangles = *( word* )pPtr;
m_numTriangles = nTriangles;
m_pTriangles = new Triangle[nTriangles];
pPtr += sizeof( word );
//读取每个三角型
for ( i = 0; i < nTriangles; i++ )
{
MS3DTriangle *pTriangle = ( MS3DTriangle* )pPtr;
int vertexIndices[3] = {
pTriangle->m_vertexIndices[0],
pTriangle->m_vertexIndices[1],
pTriangle->m_vertexIndices[2]
};
float t[3] = { 1.0f-pTriangle->m_t[0], 1.0f-pTriangle->m_t[1], 1.0f-pTriangle->m_t[2] };
//数据读取
memcpy( m_pTriangles[i].m_vertexNormals, pTriangle->m_vertexNormals, sizeof( float )*3*3 );
memcpy( m_pTriangles[i].m_s, pTriangle->m_s, sizeof( float )*3 );
memcpy( m_pTriangles[i].m_t, t, sizeof( float )*3 );
memcpy( m_pTriangles[i].m_vertexIndices, vertexIndices, sizeof( int )*3 );
//文件读取指针前进
pPtr += sizeof( MS3DTriangle );
}
要注意得是,因为MS3D使用窗口坐标系而OpenGL使用笛卡儿坐标系,所以需要反转每个顶点Y方向的纹理坐标。
不同于之前的分类和聚类算法,优化的目的是尝试找到一个使成本函数输出最小化的值。这里主要包括两个算法:模拟退火算法和遗传算法。
成本函数:
接受一个经推测的题解,并返回一个数值结果,该值越大代表成本越高(题解表现越差),该值越小就表示题解越好。
模拟退火算法:
优化算法的目标可以看为寻找x使函数f(x)最小。
但是严格的最小值往往是很难达到的,我们不得不把眼光投入到寻找一个尽可能好的次优解去。
最简单的方法被称为随机法,即成千上万次的对x进行猜测,然后把这些x中使f(x)最小的一个作为答案。虽然这样很简单,但是效果很差。于是出现了爬山法。
爬山法从一个随机解出发,然后不断向该解附近的使f(x)的值更小的x移动,直到当前x附近的解都比x差为止。为了使效果更好,我们可以从多个随机解出发重复着一个过程,将最好的一个作为答案。很容易就能认识到,这样找到的解是一个极值点,是一个局部最小值。
爬山法虽然好,但是在其寻找最优解的过程中,前进的方向是固定的(使f(x)更小的方向),但是有时向其他方法前进也是必要的,因为f(x)可能先增大在变小成为最优的。
于是就有了模拟退火法。
该算法这源于固体的退火过程,即先将温度加到很高(大量原子被激发),再缓慢降温(即退火),则能使达到能量最低点。如果急速降温(即为淬火)则不能达到最低点。
模拟退火法同样是从一个随机解出发。但是它在寻找最优解时并不一定是向更好的x移动,也有一定的概率向更差的x移动,这个概率开始较大,但是会随时间而渐渐变小,直到稳定。一般该概率可以定义为:p=e ^ (- (highcost – lowcost ) / temperature ),其中temperature是随时间增大而变小的温度,开始温度很高时p -> 1,后来会渐渐变小使p->0。
遗传算法:
遗传算法的思想来自生物的遗传和变异,算法以种群为单位(一个种群为一组既多个解),其算法的运行过程如下:
- 随机生成一组初始解(初始种群)。
- 计算种群中各个解的成本,然后进行排序。
- 我们将种群中靠前(成本低)的解保留下来,删除其他解,这一过程称为精英选拔。
- 对已有解进行微小的改变,将改变后的结果作为新的元素加入种群,这一过程称为变异。
- 选择一些优秀的解两两组合,然后将他们按某种方式进行结合(如求平均),将得到的结果作为新的元素加入种群,这一过程称为交叉(配对)。
- 不断重复2—5步,直到达到指定迭代次数或成本函数连续数代都没有更好的改善。
- 得到一组解,该组解为算法输出。
该系列结束,恩,也许以后学了更多,有了更好的了解后会回来改一改,谁知道呢?
数学基础:
线性代数的矩阵乘法运算。
非负矩阵分解是一种特征提取的算法,它尝试从数据集中寻找新的数据行,将这些新找到的数据行加以组合,就可以重新构造出数据集。
算法要求输入多个样本数据,每个样本数据都是一个m维数值向量,首先把我们的数据集用矩阵的形式写出来,每一列是一个数据,而每一行是这些数据对应维度的数值。于是我们就有了一个大小为m*n的输入矩阵。而算法的目标就是将这个矩阵分解为另外两个非负矩阵的积。
我们将分解矩阵后新得出的一个维度称为特征,那么在前一个m*r的矩阵中,第i行第j列的值就代表属性i对第j种特征的贡献值,而后一个矩阵的第i行第j列则代表第i种特征对第j个样本的贡献值。这样我们就找出了输入样本的r种特征。
r的大小应该依照需要进行选择,比如如果是希望找到某些共性特征,则就要选择较小的r。当我们确定了一个较为合适的r值后,就要想办法确定后面两个矩阵具体的值了。
书中给出的算法大致如下:
- 定义一个函数计算用来两个矩阵的差异程度(每个对应元素相减后平方的和)
- 随机生成2个矩阵(mr维和rn维)记为A(权重矩阵),B(特征矩阵)
- 计算AB与输入的mn的数据矩阵的差异,足够小则停止,否则继续
- 按一定规则调整A,B的值后转3.
对于调整的方法,可以用模拟退火(下一篇文章中会提到)等多种算法,书里使用的是乘法更新法则,该法则我没有认真去看….感兴趣的可以去看论文….英文的…
http://hebb.mit.edu/people/seung/papers/nmfconverge.pdf.
算法如下:
hn 转置后的权重矩阵和数据矩阵相乘的结果
hd 转置后的权重矩阵和原权重矩阵相乘再乘特征矩阵的结果
wn数据矩阵与转置后的特征矩阵相乘的结果
wd权重矩阵与特征矩阵相乘,再与转置后的特诊矩阵相乘得到的矩阵
为了更新特征矩阵和权重矩阵,我们先把上面所有矩阵变为数组.然后把特征矩阵中每一个值与hn中对应值相乘,并除以hd中对应的值.类似的,我们再将权重矩阵中每一个值与wn中的对应值相乘,并除以wd中对应的值.
最近的算法都很好理解的样子…不过写起来还是挺麻烦的….还有最后一篇优化了,内容挺多,包括模拟退火和遗传算法….恩
一直没有时间写…..唉
这个东西好像是属于数据可视化?反正就是把多维的数据降到低维空间但是仍然尽可能的保持原来数据之间的距离关系(就是在原来维度下离的远的点仍然离得远,接近的点仍然接近) 。最常见的应该就是降到2维以方便打印和屏幕输出。
算法的输入是所有数据在高维情况下两两之间的距离(记i与j的距离为Dij)。现在以降到2维为例说明这个算法。
首先我们把所有数据点随机绘制在一张二维图像上,然后计算它们两两之间的距离dij,然后我们计算出它与高维距离Dij的误差,根据这些误差,我们将每对数据点按比例移近或移远,然后重新计算所有dij,不断重复到我们没法减少误差为止。
还是来具体说明一下吧,假设有n个点
- 输入每一对点之间的距离Dij。
- 随机在2维平面生成n个点,点i坐标记为x[i]、y[i],计算它们两之间的距离,记为dij.
- 对所有i 和j计算:eij=(dij-Dij) / Dij,每个点用一个二维的值grad[k]来表示它要移动的距离的比例因子(初始为0,0)。在计算出每个eij后,计算 ((x[i]-x[j]) / dij)* eij,然后把它加到grad[i][x]上,同样把((y[i]-y[j]) / dij)* eij加到grad[i][y]上。
- 把所有eij的绝对值相加,为总误差,与前一次的总误差比较(初始化为无穷大),大于前一次的话就停止。否则把它作为上一次总误差,继续。
- 对每个点,新的坐标为x[i] -= rate * grad[i][x] y[i] -= rate*grad[i][y],其中rate是开始时自己定义的一个常数参数,该参数影响了点的移动速度。重新计算各个dij,回到3。
伪码:
for m = 1 to 1000{
for i=1 to n
for j = 1 to n
dij=sqrt((x[i] – x[j])^2+(y[i]-y[j])^2)
for i=1 to n
gradi=0
totale=0
for i= 1 to n
for j= 1 to n{
if(j==i) continue
eij=(dij-Dij) / Dij
grad[i][0]+= ((x[i] - x[j]) / dij)* eij
grad[i][1]+=((y[i] - y[j]) / dij)* eij
totale+=abs(eij)
}
if (laste < totale) break;
laste=totale
for i=1 to n{
x[i] -= rate * grad[i][x]
y[i] - = rate* grad[i][y]
}
}