本文重点参考了文章Mamba: The Hard Way和开源项目flash-linear-attention。
Prefill与Decoding
我们都知道,在Attention的计算中,Prefill和Decoding是两个不同的场景,具体特性如下:
| 特性 | Prefill | Decoding |
|---|---|---|
| 输入 | 长序列(长度 $L$) | 1 个新 token + 历史状态 |
| 常见瓶颈 | Compute bound(Tensor Core 利用) | Memory/Latency bound(状态读写 + 小矩阵计算) |
在回忆一下理论篇的介绍,特别是关于Mamba章节中的推导,常见的Linear Attention有两种表示格式:
矩阵格式(Attention视角):
$$ y_i = \sum_{j=0}^i (CausalMask(Q_i K_j^T)) V_j $$
递推格式(SSM视角):
$$ h_t = A_t h_{t-1} + B_t x_t $$ $$ y_t = C h_t $$
其中Decoding的算子可以比较直接的使用递归格式进行计算,因此我们本文重点还是看Prefill的实现。
Linear Attention常见算法
在Linear Attention的计算中,有一些常见的思路,本章结合flash-linear-attention的实现,对这些思路进行讲解。
Prefix Scan / Cumsum 前缀和
算法简介
先讲一下什么是Prefix Scan算法,简单来说Prefix是针对有结合性的算子提出的一种优化方式
假设有 $y_t = x_1 ⊗ x_2 ⊗ x_3 … ⊗ x_t$, 如果⊗支持结合律,那么y_t就可以用一个简单的Reduce进行求解
准备写一些关于线性注意力的文章,对相关理论和工程(Kernel)做一些梳理,这一篇是关于基础理论的。
Softmax Attention到线性注意力
Softmax Attention与O(N^2)复杂度
标准的Transformer使用的是Softmax Attention。给定查询(Query)、键(Key)、值(Value)矩阵 $Q, K, V \in \mathbb{R}^{N \times d}$,其中 $N$ 是序列长度,$d$ 是特征维度(通常 $d \ll N$)。Attention的计算公式为:
$$ Attention(Q, K, V) = \text{softmax}\left(\frac{QK^T}{\sqrt{d}}\right)V $$
让我们仔细分析一下这个计算过程的维度变化:
- 计算相似度矩阵:$QK^T$。
- $Q$ 是 $N \times d$,$K^T$ 是 $d \times N$。
- 相乘得到 $N \times N$ 的矩阵。这一步的计算复杂度是 $O(N^2 d)$。
- 应用Softmax:对每一行进行归一化,维度不变,仍为 $N \times N$。
- 加权求和:乘以 $V$。
- $N \times N$ 的矩阵乘以 $N \times d$ 的矩阵 $V$。
- 结果是 $N \times d$。这一步的计算复杂度也是 $O(N^2 d)$。
瓶颈所在: 由于Softmax是非线性的,我们必须先完整地计算出 $N \times N$ 的Attention Matrix。
背景
从年初 R1 火起来以后,看到了很多关于智能本质的讨论,目前大部分讨论似乎都认为:语言才是智能的基础,是通往 AGI 的路径。
比如张小珺[1-3]今年采访了很多大佬,就有两个这样的例子:
-
杨植麟[1]:认为在现有范式下,多模态能力往往难以提升模型的“智商”,甚至可能损伤模型已有的语言智能。他在接受采访时提到:“如果你想给模型加多模态能力,你需要确保这个多模态能力不要损伤它的‘脑子’。多模态能做到不损伤已经很好了。”他指出,在多模态模式下希望模型和纯文本模式共用一个“大脑”——也即多模态部分应尽量借用文本模型已有的智力,而不是开启另一套全新参数,否则可能丢掉原来文本部分学到的能力。
-
姚顺雨[2]也强调语言在通向通用智能方面更具潜力。他起初从事计算机视觉研究,但后来直觉告诉他语言才是更核心、更有潜力的方向,因此读博后转向了语言模型的研究。他指出,语言是人类为了实现认知泛化而发明的最重要工具,具有生成和推理的闭环特性,这使其成为构建通用智能系统的关键媒介。
不过还是有一些其他的观点,认为多模态能力的潜力可能被训练范式所限制,而非多模态本身毫无助益。例如阶跃星辰的张祥雨[3]就提到:
-
图文数据效果不好的原因是噪声数据:如果简单用图文混合数据进行训练,但不解决思维链(CoT)推理或任务复杂度的问题,模型的学习可能是有害的。在缺乏正确推理指导的情况下,模型每一步可能得不到有效信息,产生错乱的梯度,训练效果要么毫无提升,要么甚至更糟。这与他在一个万亿参数多模态模型项目中的发现一致:模型规模增大后,其数学和逻辑推理能力不仅没有提升,反而在达到平台期后开始下降。原因在于模型倾向于跳步直接给出答案而非踏实推演,从而累积误差。简单扩大模型或混合数据并不能自然地融合视觉与文本能力,背后缺少关键环节。
-
图文推理的能力同样需要预训练的激活:例如,OpenAI 的 O3 模型在推理过程中能够将图像直接融入思维链,通过动态操作图像(旋转、裁剪等)来辅助解题,在视觉推理基准 V⋆Bench 上取得了 95.7% 的高准确率,刷新了多模态推理上限。令人意外的是,O3 所采用的一些方法(如对原图进行局部放大裁剪)看似原始,却在许多问题上效果很好。他认为:这可能是因为在海量预训练语料中,存在大量图像附带局部放大及文字解释的模式。例如在电子维修论坛中,经常有人上传一张设备照片提问“哪里出了问题”,回答者会圈出图片局部并放大,说明某个电容烧了等。模型在预训练中已经隐式学习了这种“先整体看图 → 再局部看图解释”的模式。因此,像 O3 那样在推理时按需裁剪图像,严格遵循了预训练语料中的分布模式,反而取得了出色效果。
针对这个问题,想写一些自己对这个领域的了解和看法。
Vision LM 的推理能力研究
在开始讨论前,我先对智商这个事情做一个定义:通常我们可以把模型的能力分为理解、推理、生成三种,我们认为其中推理能力是智商的表现。
Vision CoT
链式思维(CoT)是大模型提升复杂推理最早被证明有效的范式之一;其视觉扩展(Vision CoT / Visual CoT)在 2023 年起就开始出现。早期的工作以语言+图像作为输出,但是以CoT只会以文本给出,这个时候图像不参与推理的过程,图像带来的推理能力自然就无从谈起。
后来O3的兴起带火了一个新的方向:thinking with images,其核心思想:不要把“看图”当成一次性输入,而是让图像参与到逐步推理循环中,成为中间状态的生成与消费对象。也就是说图像开始参与了推理的过程,因此我们就从这里作为了解Vision LM推理能力的起点。
(下图是thinking with images的例子)
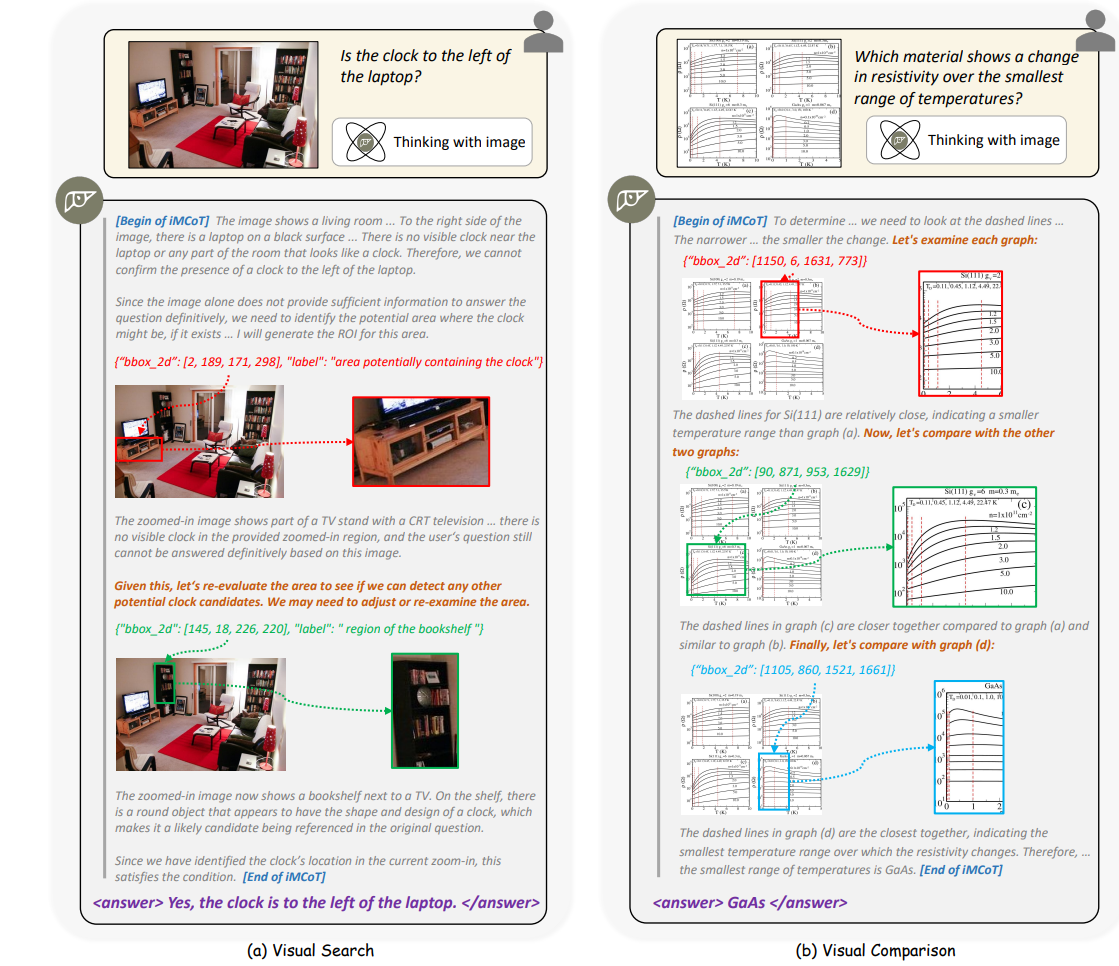
OpenAI O1 / O3 系列
OpenAI 在 GPT‑4 之后推出 o1 系列[4],算是第一次验证了Test Time Scaling和推理能力的关系。更进一步的 O3 模型在 demo 中展示了新的模式:除了“会看图”理解,还会“用图思考”。推理过程中模型可以:
- 主动定位相关区域(放大公式、框选局部结构、旋转视角);
- 将局部视觉观察嵌入后续思维链进行推理; O3 在视觉推理基准 V⋆Bench 上达到 95.7% 的成绩,也算是验证“显式把视觉纳入思维链”是可以提升推理能力的研究方向。
DeepEyes
DeepEyes[6] 应该是第一个开源再现“thinking with images”能力的项目。它不依赖额外人工 SFT,而是直接用 RL 激活模型的视觉逐步聚焦行为。模型可以按照:生成初始思维链 → 判断是否缺细节 → 自主调用“放大 / 裁剪”工具 → 将裁剪区域重新编码 → 继续推演。循环执行形成类似 O3 的效果,并且得到了验证:
上一篇文章我们聊了一下Ray与LLM强化学习框架设计,探讨了其架构的演进,但是没有提到为什么框架会往这个方向逐渐演进而不是一开始就使用现在的设计。这里面自然有实践中不断优化的结果,但是也是和整个LLM RL需求的变化密切相关的。
因此,本文会主要讨论一下LLM强化学习中,算法与系统框架是如何相互影响、协同演化的。首先分析两个相对成熟的协同设计案例,然后讨论几个正在不够成熟、但是在笔者看来很有潜力的优化方向。
算法与框架协同演化的典型案例
先讲两个目前已经相对得到了共识的问题:
案例一:推理模型驱动的分离式架构设计
在前一篇文章中提到过,之前的强化学习还是希望尽量on-policy的,因此早期的强化学习系统倾向于采用on-policy算法配合co-located的架构设计。这种选择有其合理性:算法层面,on-policy确实具备样本效率优势;系统层面,在CoT和Test-time Scaling兴起之前,模型输出长度差异相对较小,推理引擎产生的计算空泡还算可控。尽管资源利用率的问题客观存在,但on-policy算法的优势在一定程度上抵消了这种系统层面的低效。
不过,从去年o1发布开始,业界开始重视Test time scaling,加上R1的发布又给推理模型点了一把火,这种范式的改变打破了之前的平衡:模型在推理阶段生成的文本长度显著增加,且不同样本间的长度差异极为悬殊。在这种新的计算模式下,on-policy的算法优势已无法弥补系统资源的巨大浪费——所有并行环境必须等待最长推理任务完成才能进入下一轮迭代,这种同步约束造成了严重的吞吐量瓶颈和大量计算资源闲置。

正是因为这个挑战,业界逐渐开始转向异步RL框架设计。其核心思想是将Generation与Training完全解耦,构建生产者-消费者的流水线架构。以AsyncFlow和AReaL为例:
-
推理引擎(Rollout Workers):持续异步生成新的数据,彼此间无需同步等待。
-
训练引擎(Trainer Workers):训练节点异步地从共享缓冲区获取数据进行模型更新。
这种流式RL设计有效避免了慢速推理任务对整体流程的阻塞,确保所有计算设备维持高利用率,从而实现训练吞吐量的显著提升。这正是算法演进与系统架构优化协同设计的一个典型案例:新的需求需要新的取舍,进一步催生了新的架构。
案例二:MoE架构与训练推理引擎的精度对齐挑战
另一个挑战出现在系统层面,尤其是在使用超大模型或混合专家(MoE)模型时:训练引擎和推理引擎之间的不匹配。
在RL的训练中,通常为了效率,模型的推理(生成)过程可能会在专门的推理引擎上执行(例如使用vLLM),而梯度计算则在训练后端(例如DeepSpeed)上进行。然而,两者在数值精度(如FP16 vs INT8)、算子融合、批处理调度或MoE门控行为上都可能存在差异,进而导致rollout数据和训练计算之间的分布漂移。
实际上,这个问题并不是在MoE中才刚刚出现,以小红书为例,他们在去年的QCon演讲从0到1构建RLHF系统——小红书大模型团队的探索与实践中就提到了对训推一致性的要求,通过自研框架进行对齐。此外还有一些公司会选择使用推理引擎生产数据,然后通过训练引擎再次推理拿到logit进行概率计算。
但是随着MoE的兴起和推理引擎加速技术的不断发展,精度对齐变得越来越困难,比如MoE的路由层引入的不一致可能远高于Dense Model中的精度不一致。同时由于数据的实际采样概率还是由推理引擎决定,以前主要是不同引擎计算的概率不同,但是现在可能连采样出的token都会有巨大的变化,这让通过训练框架再次对齐也更不够用了。
为了解决这一问题,AREAL框架提出了Decoupled PPO算法,采用了一种巧妙的双引擎协同策略:利用推理引擎输出的概率进行重要性采样(因为它反映了真实的数据采样分布),同时使用训练引擎输出的概率来计算置信域(Trust Region),确保训练引擎对模型更新仍在训练引擎原来的有效范围内进行。

类似的,FlashRL 也在他们的blog中提出了一种截断重要性采样的技术TIS,通过对更新进行重新加权,来修正量化推理(用于采样)和全精度模型(用于优化)之间的策略差异。通过这一技术,即使是高度量化的rollout数据(如INT8/FP8)也能被用于训练,而不会损害最终效果。
可以看到,在这个例子里,研究者们通过算法的设计,来弥合了系统设计导致的训练和推理之间的鸿沟。
(可能的)发展趋势:协同设计的新兴挑战与机遇
讲了有共识的,有相对公认的解决方案的案例以后,我们来看一看有些相对不那么得到共识,或者大家意识到但是解决方案还没有完全收敛的方向:
方向一:Agent RL: 样本效率、环境管理与过程奖励
随着Agent RL的发展,强化学习的过程中,LLM需要升级为能够调用工具、API,并与环境持续交互的自主智能体时,新的挑战也随之浮现。
个人认为,根据当前研究趋势,Agent RL主要可归为两类典型范式:
- Sandbox + Browser:通常用来训练通用Agent,在受控沙箱或浏览器环境中进行任务执行与评估;
- MCP + Tooluse:常见于内部或垂直领域,增强模型使用工具集合使用能力。
以实际场景为例,可以更清晰地看到Agent RL所面临的关键难题。
1. 奖励稀疏性与延迟问题
在复杂任务中,类似o1的结果奖励机制效率极低。例如,Anthropic提到Claude Ops 4可在后台连续运行7小时完成软件开发任务,若仅在最终成败时给予奖励信号,这种延迟且稀疏的反馈使得样本的生成变得越加困难,同时单一的结果奖励几乎无法有效指导学习过程。因此,过程级奖励(Process-level Rewards)或者智能体引导机制(Agent Guidance)可能会重新变得重要。
近期工作如Agent-RLVR 框架,在 RL 训练中引入高层指令提示、动态错误反馈等“教学式”奖励信号,显著提升了智能体在复杂编程任务中的成功率。这类方法模拟人类教学过程,通过中间反馈加速策略收敛。
与之相关的,还有对样本效率的提高:一方面需要构建更高效的样本生成流水线,另一方面要探索高质量数据的重用机制以降低采样成本。相关研究也在逐步涌现,如Sample-efficient LLM Optimization with Reset Replay,为解决Agent RL中的样本稀缺问题提供新的思路。
2. 复杂状态表示与管理
Agent 的状态不仅包括对话历史,还涵盖工具调用输出、环境观测、以及内部思维链等多源异构信息。传统 RL 框架难以有效建模此类高维、长序列的状态空间。
最近LLM强化学习框架发展特别快,Ray作为被ChatGPT带火的框架,在LLM各个训练阶段中,RL阶段的应用应该是最多的。写篇文章记录一下这块发展的脉络和一些看法。
从Google Pathways说起
讨论Ray和RL系统,得从Google的Pathways系统开始:2021年Google提出了Pathways作为下一代AI架构和分布式ML平台,在相关文献中详细讨论了Single-Controller + MPMD的系统设计。
Single-Controller(单控制器)是指用一个中央协调器来管理整个分布式计算流程的架构模式。在这种设计中,有一个主控制节点负责整个计算图的执行,包括任务分发、资源调度、状态监控等。
Multiple-Controller(多控制器)则是指使用多个分布式控制节点来协同管理计算任务的架构模式。在这种设计中,没有单一的中央协调器,而是由多个控制器节点分别负责不同的子系统或计算子图,通过分布式协调协议来实现全局一致性。
在Ray中的Driver Process就可以被作为一个典型的Single Controller来启动不同的任务程序,而通过torchrun运行的PyTorch DDP分布式计算则是在每个node上各自执行自己的程序则属于典型的Multiple Controller范式。
MPMD(Multiple Program, Multiple Data)是一种分布式计算范式,指在一个计算任务中,不同的节点运行不同的程序来处理不同的数据。这种模式下,各个计算节点执行的代码逻辑可能完全不同,每个节点都有自己特定的任务和职责。
SPMD(Single Program, Multiple Data)则是另一种常见的分布式计算范式,指所有节点运行相同的程序,但处理不同的数据分片。
典型的SPMD任务包括传统的分布式训练,比如PyTorch DDP,每个节点运行相同的程序来处理不同的数据,最多根据rank的值会有一些特别的处理(比如rank=0的节点负责checkpoint)。相比之下,大模型训练包括了流水并行这种更复杂的任务,每个节点组需要运行不同的程序,就更适合用MPMD的方式来实现了。
一般来说,MPMD系统由于包含众多异构组件,各组件间的协调和同步变得相当复杂。为了简化开发复杂度并确保系统执行的一致性,Single-Controller架构成为了自然的选择——通过引入中心化的控制器来统一管理整个分布式计算流程,包括任务调度、状态同步和异常处理等关键环节。
更多的细节就不多说了,有兴趣的话可以去看Oneflow团队当年写的两篇文章,非常深刻:解读谷歌Pathways架构(一):Single-controller与Multi-controller和解读谷歌 Pathways 架构(二):向前一步是 OneFlow。
这与LLM强化学习有什么关系呢?用RL训练LLM本质上是一个多阶段、多节点的复杂分布式任务。典型的RLHF流水线涉及多个不同模型,计算流程分为几个关键阶段:
- 生成阶段:当前策略模型(LLM)对一批输入提示生成响应文本
- 评估阶段:这些响应由奖励模型评分,或通过人类/自动化偏好模型进行比较评估
- 训练阶段:基于获得的奖励信号更新策略模型权重(可能还包括价值函数或评论家网络的更新)
这些阶段之间存在明确的数据依赖关系——训练更新必须依赖于生成的样本及其对应的奖励分数。在朴素的实现中,这些阶段只能串行执行,引入大量上下文切换的同时还要求所有的模型使用相同数量的GPU进行计算,计算效率是相当低下的。因此正如Pathways架构所启发的那样,我们希望在保证正确性的前提下,通过良好的系统设计,尽可能地重叠和并行化这些工作阶段,以最大化计算资源的利用效率。
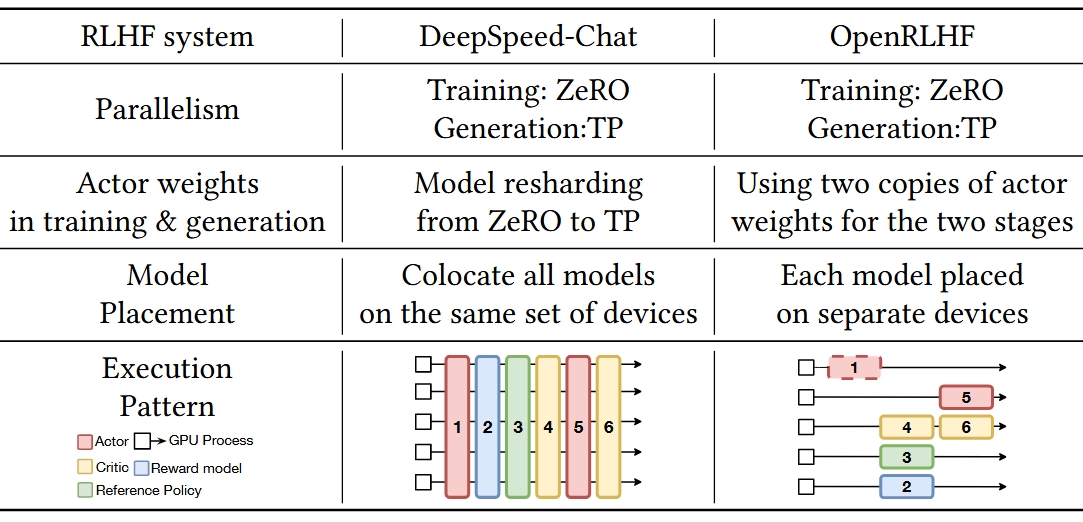
直接说有点抽象,可以看下面这个从HybridFlow里截的表格,我截了两个最早的RLHF系统,左边的DeepSpeed-Chat实现了SPMD的串行方式,而右边的OpenRLHF则是典型的MPMD系统。
Ray与LLM强化学习框架
其实从前面的内容可以看出来,Ray的设计很适合用来开发Single-Controller + MPMD的程序,也就自然适合LLM强化学习的场景了。
实际上,社区也确实基于Ray开发了大量的强化学习框架,目前主要的设计包括两种:Colocated架构和Disaggregated架构。粗略地说,Colocated架构意味着把生成阶段和训练阶段放在同样的节点上运行;而Disaggregated架构则把它们放在不同的节点上:
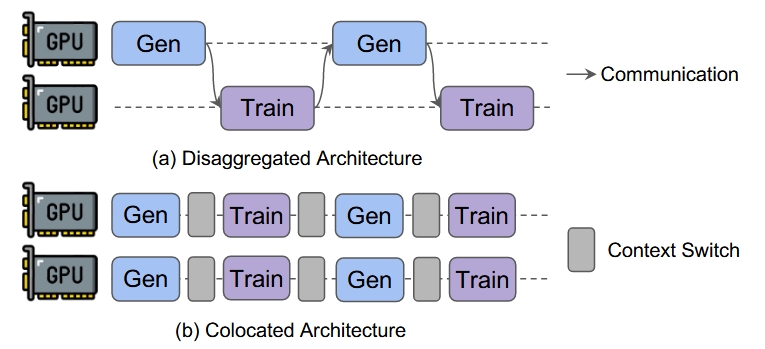
一看这个图,我们会发现Disaggregated Architecture中存在大量的计算bubble,甚至可能比不上之前SPMD模式!这也是为什么很多框架如OpenRLHF、Nemo-aligner、VeRL都是按照Colocated架构来设计的。
需要注意的是,图里的Train和Gen代表的是RLHF的不同阶段,每个阶段内每个GPU可能在运行不同任务,因此整个过程仍然是MPMD的。
以经典的PPO算法为例,整个Train的阶段包括Actor Model(on training Framework)/Reference Model/Reward Model/Critic Model四个模型,Gen阶段包括Actor Model(on inference framework)一个模型,以OpenRLHF为例:

可以看到这里Actor Model会在Deepspeed和vLLM两个引擎间进行切换,因为实际算法需要保存的模型共有5个。
Colocated RL框架 (解法和问题)
接下来继续看这个基于Ray的框架:OpenRLHF使用Ray启动和协调组件,但使用Ray的Placement group实现了Colocated架构,在每个节点上在rollout和训练任务之间分割GPU资源。例如,在给定节点上,框架可能将每个GPU的0.75分配给训练actor,0.25分配给生成actor,这样有效地让一个训练进程和一个生成进程"共享"每个GPU而不互相干扰。
很容易从前面的图看出来,Colocated框架中的资源共享是一个主要的优势,通过设计合适的分组方式,我们可以减少GPU的空闲时间,减少模型offload的频率,同时尽量并行化不同节点的执行,从而最大化提升资源利用效率。
然而,随着模型大小和集群大小的增长,Colocated框架也显示出了自己的局限性:
-
第一个关键问题是StreamRL中提到的资源耦合。虽然Colocated框架比起SPMD的程序提升了计算任务的并行性,并通过分组来允许每组model使用不同的资源,但是这并不能完全消除共享设备带来的问题:因为生成和训练同时共享相同设备,我们不能独立扩展或为每个阶段定制资源。同时训练任务(计算密集)和生成任务(IO密集)的瓶颈并不相同,这不利于GPU资源的利用。
-
另一个问题是,LLM生成的文本长度是不固定的,尤其随着thinking model的大火,生成任务中不同组的模型生成结果的时间可能差异很大。比如我们有32块GPU,每4块GPU为一组进行生成,如果其中一组生成任务过长,会导致其他28块GPU空等造成资源浪费。
总的来说,Colocated框架通过精细的资源管理实现了较高的GPU利用率,相对成熟和稳定,确实许多后续框架都借鉴了类似的设计思路。但是,正如前面提到的资源耦合问题,这种架构在可扩展性方面仍有局限。这也为下一代RL框架的发展指明了方向:能否通过打破严格的串行约束,让生成和训练阶段真正独立地并行执行?
On-Policy和Off-Policy
本文的重点是Ray和LLM RL的框架设计,因此不会在这一部分内容做过多阐述,大概而言:
做Ray Platform也快2年了,遇到过各种的问题,整理一些踩过的坑看一下。
先从我们自己最常用的Ray Data开始,看看最常见的OOM/OOD问题,这个问题很多时候都是和反压相关的。
说是Ray Data,不过这里的反压不止一层,大概包括下面几个地方:
- Ray Core Generator:针对Ray Generators的控制,防止后台生成的数据过多导致OOM/OOD。
- Streaming Executor + Resource Allocator:
- 针对正在执行的任务,控制生成结果的速度,避免单个任务生成的数据过多导致OOM/OOD。
- 针对单个Operator,控制提交任务的数量,避免在资源紧张时提交新任务。
- Backpressure Policies: 其他关于任务提交的反压规则。
下面我们逐层分析这些机制的实现。
Ray Core Generator:对象数量反压
Ray Generator 类似Python Generator,用来作为迭代器进行遍历,但是和Python Generator有一个很大的不同在于:Ray Generator使用ObjectRefGenerator在后台持续执行。也就是说如果Ray Data的单个read_task需要读取一个很大的文件时,没法通过控制拉取任务产出的速度来控制任务的内存占用。(不管下游是否主动拉取,都会持续读取新的数据block。)
针对这个问题,Ray Generators支持手动配置一个threshold(_generator_backpressure_num_objects parameter)来对Generators进行反压。
核心逻辑在task_manager.cc中的HandleReportGeneratorItemReturns这个方法里面。这个函数逻辑比较复杂,里面还有比如乱序/幂等等问题的处理,我们只看反压状态的管理:
// 请求的item的index
int64_t item_index = request.item_index();
// 生成器已生产的对象数量
auto total_generated = stream_it->second.TotalNumObjectWritten();
//已被消费的对象数量
auto total_consumed = stream_it->second.TotalNumObjectConsumed();
// item已经被消费了,说明消费速度足够快,不用反压。
if (stream_it->second.IsObjectConsumed(item_index)) {
execution_signal_callback(Status::OK(), total_consumed);
return false;
}
// Otherwise, follow the regular backpressure logic.
// NOTE, here we check `item_index - last_consumed_index >= backpressure_threshold`,
// instead of the number of unconsumed items, because we may receive the
// `HandleReportGeneratorItemReturns` requests out of order.
if (backpressure_threshold != -1 &&
(item_index - stream_it->second.LastConsumedIndex()) >= backpressure_threshold) {
RAY_LOG(DEBUG) << "Stream " << generator_id
<< " is backpressured. total_generated: " << total_generated
<< ". total_consumed: " << total_consumed
<< ". threshold: " << backpressure_threshold;
auto signal_it = ref_stream_execution_signal_callbacks_.find(generator_id);
if (signal_it == ref_stream_execution_signal_callbacks_.end()) {
execution_signal_callback(Status::NotFound("Stream is deleted."), -1);
} else {
signal_it->second.push_back(execution_signal_callback);
}
} else {
// No need to backpressure.
execution_signal_callback(Status::OK(), total_consumed);
}
所以未消费对象数量达到阈值时,Ray Generator会暂停任务执行。
准备对DeepSeek的开源项目整理一些文档,也顺便强化一下记忆,先从FlashMLA开始。
FlashMLA是DeepSeek开源的MLA算子实现,这个实现主要给inference decoding用的,Training和prefill应该是另外一个算子。
先拿下面的图表示一下MLA算子是在计算一个什么东西,这篇文章就不讲具体的推导了,反正这个算子大概就是下面的2个GEMM算子的融合。需要注意的是:
- 这里矩阵K和矩阵V的共享一部分参数。
- 图里只画显示了一个Query Head和一对KV Head的计算。在实际计算中还要num_kv_head和batch_size两个维度。
- 两个GEMM中间其实还有一个sotfmax,不过这里可以通过online softmax算法把这块逻辑独立处理分块处理,所以不影响主流程。
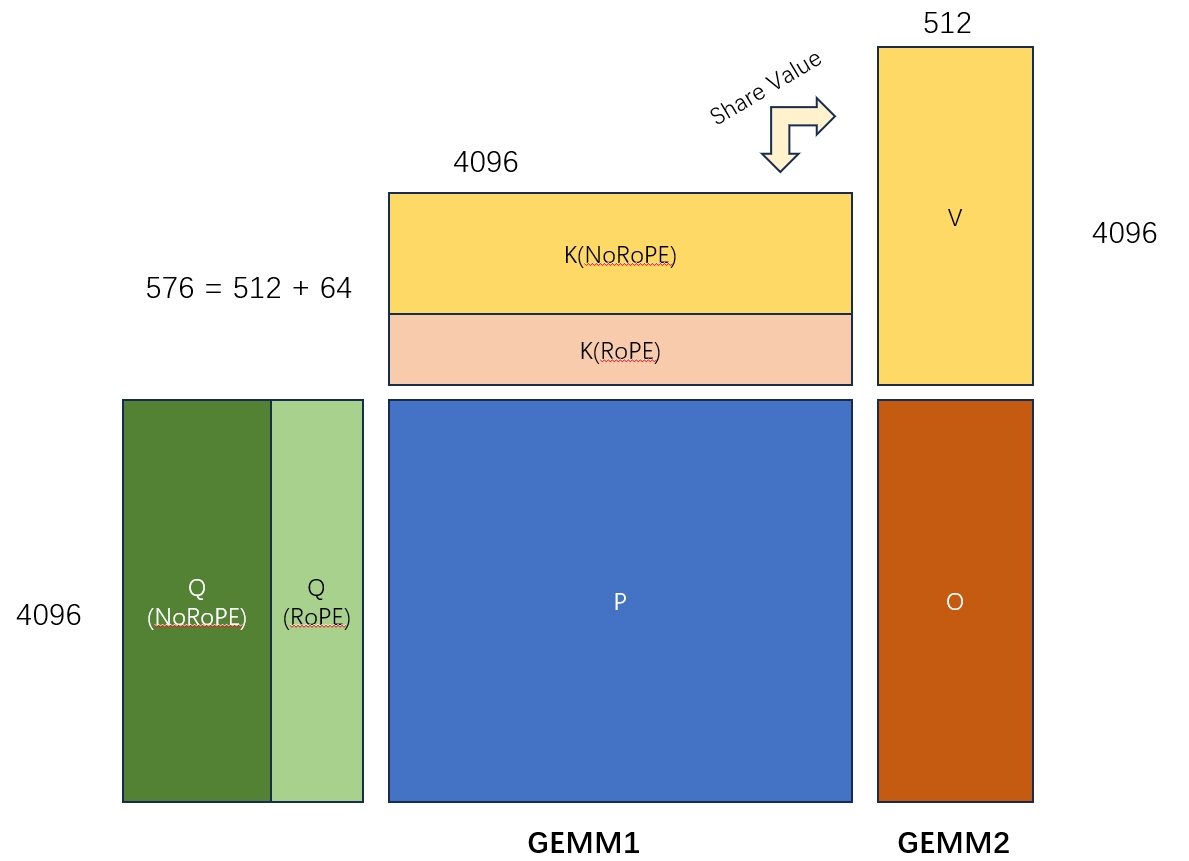
Kernel的调用主要分两部分
- 调用
get_mla_metadata来计算一些metadata,用来优化kernel的执行 - 调用
flash_mla_with_kvcache进行计算
在进入调用前,先大概说一下FlashMLA计算的拆分逻辑。这块和FlashDecoding很像,并没有要求一个thread-block必须处理一个完整的sequence,而是通过一个负载均衡算法,把所有的sequence放到一起,然后拆分成一个个的sequence-block,然后每个thread-block就去处理分配给它的那些block的计算,最后再把这些thread-block的结果用合并,得到正确的输出。
大概是下面这个图的样子:
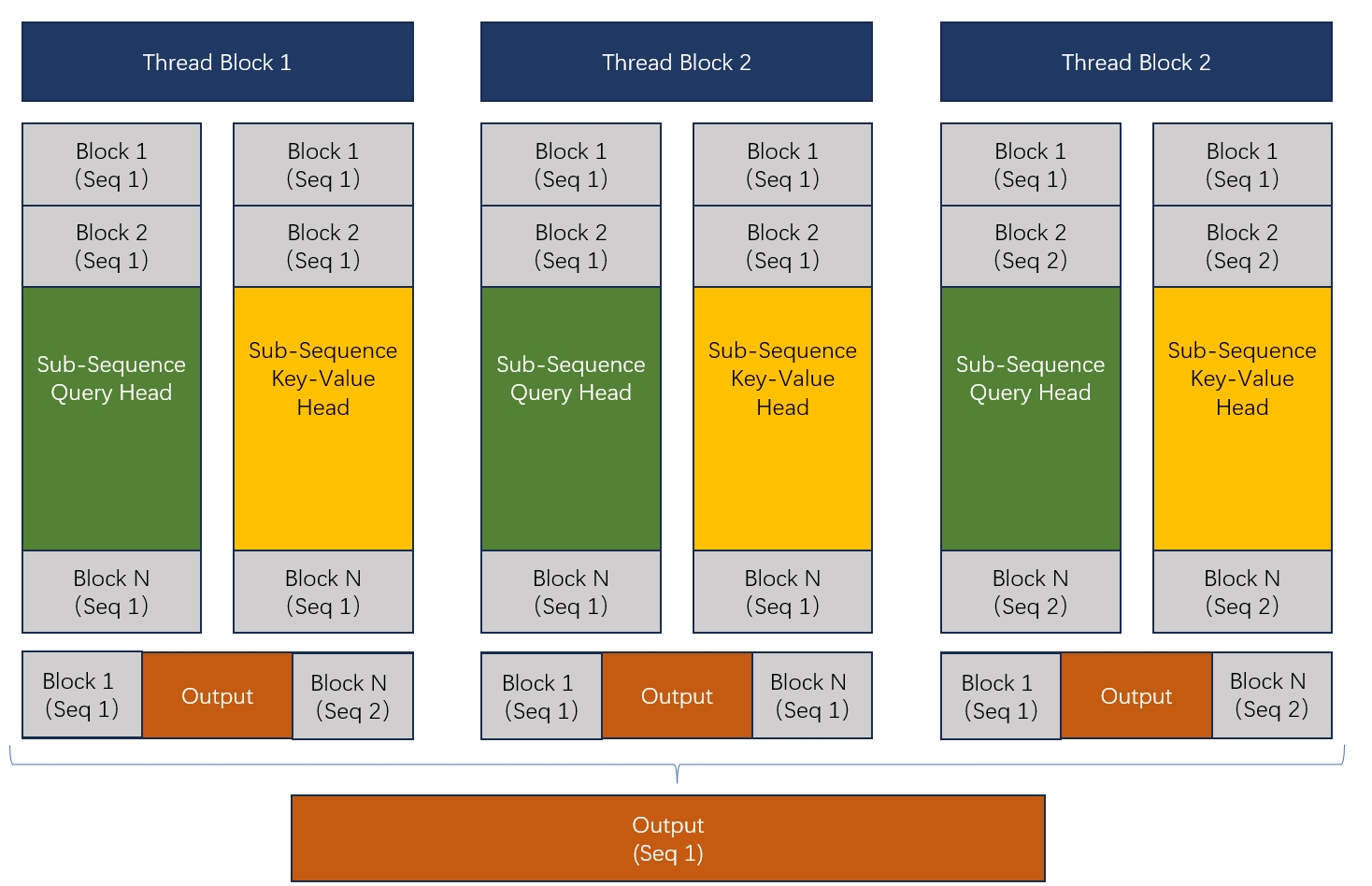
所以为了完成计算,第一步就是决定每个block需要处理哪些sub-sequence,也就是get_mla_metadata要完成的事情。
get_mla_metadata
先看get_mla_metadata具体提供了哪些元数据,我们从repo提供的测试代码入手,考虑最简单的情况(batch_size=128, query_sequence_len=1, mean_key_sequence_len=4096, MTP=1, num_kv_head=1, num_q_head=16, TP=1, hidden_NoRoPE_dim=512, hidden_RoPE_dim=64, varlen=False)。
# cache_seqlens = tensor([4096, 4096, ..., 4096], dtype=torch.int32),
# size=batch_size, value=sequence_len
# s_q=1 (query_sequence_len=1且MTP=1), h_q(num_q_head)=128 (TP=1=128/128) h_kv(num_kv_head)=1
# 基于这些配置,计算mla kernel的metadata
tile_scheduler_metadata, num_splits = get_mla_metadata(cache_seqlens, s_q * h_q // h_kv, h_kv)
因为这里我们是在测试decoding步骤,所以有query_sequence_len=1,可以看到三个入参:
- kv cache的大小
- 类似GQA的Group数量,这个参数表示每个kv head对应多少个query head。
- kv head的数量
get_mla_metadata会根据GPU中SM的数量和要处理的数据的大小,给每个SM分配任务。这个注意get_mla_metadata_kernel的参数为<<<1, 32, 0, stream>>>,因此所有计算会在1个warp中完成。
3月底整理了一个关于经典Paged Attention算法的ppt, 想起这个几年没写过的blog,把PPT改成一篇文章证明我还活着(-_-)。

vLLM 的 Paged Attention
开始前先说明一下,vLLM里的Paged Attention Kernel是有好几个不同的版本的,大概是下面这样子:
vLLM早期版本:
- Prefilling -> Flash Attention的flash_attn_varlen_func
- Dedocding -> 自己实现的Paged Attention
- paged_attention_v1 : 用于比较短的sequence
- paged_attention_v2 : 用于不想用v1的情况 :)
源码大概是这样的:
# NOTE(woosuk): We use a simple heuristic to decide whether to use
# PagedAttention V1 or V2. If the number of partitions is 1, we use
# V1 to avoid the overhead of reduction. Also, if the number of
# sequences or heads is large, we use V1 since there is enough work
# to parallelize.
# TODO(woosuk): Tune this heuristic.
# For context len > 8192, use V2 kernel to avoid shared memory
# shortage.
use_v1 = (max_seq_len <= 8192 and (max_num_partitions == 1 or num_seqs * num_heads > 512))
vLLM 最新版本就已经全部转向Flash Attention, 用cutlass实现了。
背景
多目标优化中有一个很常见的跷跷板问题,就是说在训练时,多个目标会相互影响,导致震荡—你降我升,我升你降。有时间还会出现Nan的结果,需要很仔细的调参测试+清洗数据才能训练出一个理想的模型。
针对这种问题,自然就有了一些尝试,比如从帕累托最优的角度寻找优化方向(阿里PEA),修改模型结构使Shared部分存储更泛化的信息(腾讯PLE)。不过这两个写的人都挺多了,就写一下Google Small Towers的这篇文章吧。
主要问题讨论
文章首先讨论了两个问题:
1. Over-parameterization对多任务模型的适用性
我们都知道over-parameterization对单任务模型是有价值的,那边对多任务模型是否成立?
这里以将多个目标的线性组合作为优化目标的例子,认为over-parameterization能够帮助处理各任务优化目标之间的冲突问题(既减少跷跷板问题的出现)。
2. 大型模型和小型模型的多目标学习表现对比
通过实验对比了大型模型和小型模型进行多目标学习中的不同表现。
实验中,不论是增加任务相关结构的复杂度,还是增加任务共享结构的复杂度,Pareto frontier都会呈现先变好在变差的趋势。
因此,文章认为over-parameterization并不利于多目标学习中的共享性,进而伤害了多目标学习中的泛化能力。因此,在多目标学习中,模型大小实质上是对模型有效性和泛化能力的一种平衡。
To summarize our insights, for a multi-task learning model, small models benefit from good multi-task generalization but hurts Pareto efficiency; big models theoretically have better Pareto efficiency but could suffer from loss of generalization.
Under-parameterized Self-auxiliaries模型结构
文章提出了under-parameterized self-auxiliaries的模型结构:
首先假设模型的共享方式是所有任务共享最下面的表示层(Hard Sharded,MMOE这种,PLE就不行),既对任务t,有:
$$f_{t}(x; \theta_{sh}, \theta_{t})=f_{t}(h(x; \theta_{sh}); \theta_{t}), \forall t$$
其中 $\theta_t$ 是任务相关的参数, $\theta_sh$ 为共享参数, $h(x;\theta_sh)$ 既为共享的表示层输出。